Ajuste de la carga de índice
Puede ajustar la carga de índice para obtener un rendimiento óptimo configurando los valores ajustables y evaluando los resultados.
Por qué y cuándo se efectúa esta tarea
La carga de índice empieza con un solo origen de entrada, utiliza el proceso multihebra y termina con un solo servicio por lotes grabando en un índice único.
El diagrama siguiente muestra las áreas ajustables disponibles de carga de índice:
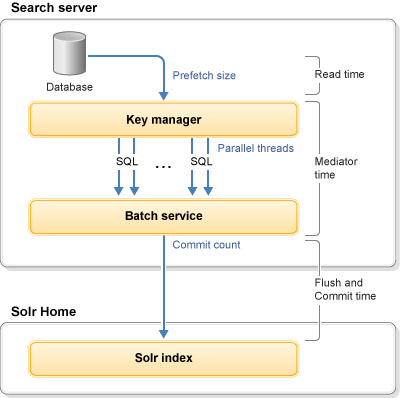
Donde existen las siguientes áreas ajustables principales:
- Hebras paralelas
- El número de hebras que se deben utilizar para la indexación paralela.
- Tamaño de captación previa
- El número de filas a devolver para cada llamada de base de datos (SQL).
- Recuento de compromisos (compromiso fijo)
- Número de documentos de índice a mantener en memoria antes de grabar en el índice Solr.
- Recuento de lotes (compromiso flexible)
- Número de documentos de índice a mantener en el almacenamiento intermedio de tiempo de ejecución de carga de índice antes de enviarlos a la pila de memoria Solr.
Cuanto más alto es el valor de recuento de lotes, mayor es el rendimiento de indexación pero con más basura generada.
Existen los siguientes indicadores de medición para determinar el rendimiento que se pueden ver desde la página de estado de carga de índice:
- Tasa
- Promedio de documentos indexados por segundo en la pila Solr.
- Tiempo de lectura
- Promedio de tiempo empleado en ejecutar llamadas SQL.
- Tiempo de desecho
- Promedio de tiempo empleado en compromisos flexibles de Solr.
- Tiempo de compromiso
- Promedio de tiempo empleado en compromisos fijos de Solr.
- Tiempo de indexación
- Tiempo global total empleado en la indexación.
Puede utilizar estas estadísticas para ajustar las principales áreas ajustables de carga de índice.
El diagrama siguiente muestra cómo funciona la carga de índice con fragmentos de datos y cómo puede ajustar la captación previa, las hebras y el recuento de procesos por lotes para el rendimiento:
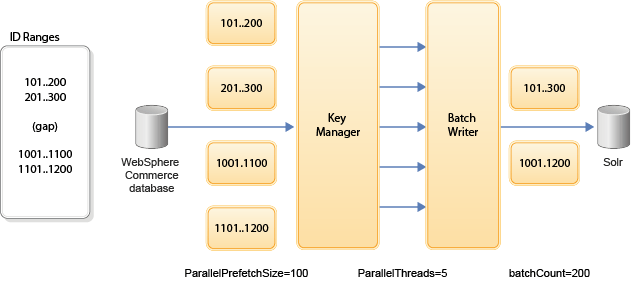
Donde:
Donde:
- El gestor de claves utiliza la captación previa para obtener pequeños fragmentos de datos de la base de datos y los distribuye uniformemente en todas las hebras de trabajo. Esta técnica evita la sobrecarga de la base de datos cuando se procesa un conjunto de resultados de tamaño muy grande. Es posible que los conjuntos de resultados de tamaño muy grande no encajen ni siquiera en el registro de transacciones de base de datos. Mediante el uso de fragmentos de datos más pequeños, el tiempo de consulta se mejora y la carga de trabajo de hebra de carga de índice está distribuida más uniformemente.
- El tamaño de captación previa (ParallelPrefetchSize) define el tamaño de bloque de anticipación, mientras que el siguiente SQL de rango (ParallelNextRangeSQL) se utiliza para tratar espacios rango de ID vacíos grandes. El SQL de rango siguiente sólo se utiliza cuando la anticipación no contiene datos. Es decir, cuando se detecta un espacio. Este SQL se utiliza para devolver el siguiente ID disponible y, por lo tanto, evita el rastreo innecesario.
- El tamaño de captación previa, el recuento de hebras, los rangos y el recuento de proceso por lotes son todos ellos factores a tener en cuenta al ajustar carga de índice.
Procedimiento
-
Utilice la técnica de ajuste general siguiente para conseguir un rendimiento óptimo de carga de índice:
- Empiece con una ventana de tiempo fija o un conjunto de datos pequeño para ajustar antes del escalado ascendente. Esto ayuda a calibrar las tareas con el hardware.
- Determine el tamaño de captación previa óptimo, cuando el tiempo de lectura es ligeramente superior a 0 e idealmente cuando el tiempo de lectura total transcurrido es inferior a 1 minuto. Se utiliza el tamaño de captación previa para controlar el tiempo de lectura.
- Alcance el mejor rendimiento, cuando los tiempos de desecho y de compromiso se aproximan a 0. Es decir, cuando la sobrecarga de índice general de Solr es 0. El recuento de lotes se utiliza para controlar el tiempo de desecho (compromiso flexible). El recuento de compromisos se utiliza para controlar el tiempo de compromiso.
- Cuando se encuentren los valores óptimos, reduzca el número de hebras hasta que descienda la tasa de rendimiento. Esta técnica ayuda a encontrar la potencia máxima a establecer en cada canalización.
-
Utilice los valores generales siguientes para ayudarle a maximizar la velocidad de indexación:
- Utilice una JVM de 64 bits y asígnele tanto almacenamiento dinámico como sea posible para reducir la recogida de basura global.
- Utilice un rango de claves codificado, de modo que la carga de índice no pierda tiempo explorando rangos vacíos.
- Utilice un ThreadLaunchTimeDelay para evitar procesar todas las hebras de indexación en paralelo en el arranque y sobrecargar los recursos de base de datos.
-
Ajuste los valores siguientes para determinar cómo funciona la carga de índice con fragmentos de datos:
- Ajuste el tamaño de captación previa para controlar cuántas filas se leen desde el origen de datos a la vez. Esto se debe ajustar para equilibrar la carga de base de datos con la disponibilidad de datos para hebras worker.
- Ajuste el recuento de hebras para controlar cuántas hebras paralelas están procesando estas filas. Esto debe ajustarse para equilibrar la carga de CPU global con la capacidad de procesar datos en paralelo.
- Ajuste ParallelNextRangeSQL para evitar espacios en rangos de ID de entrada. Cada rango se capta y distribuye entre las hebras worker.
- Ajuste el recuento de lotes para controlar los tamaños de los lotes que se envían a Solr.
-
Ajuste los atributos de rendimiento configurables en los archivos de configuración de carga de índice wc-indexload-profileName.xml y wc-indexload-businessobject.xml.
Para obtener más información, consulte Archivos de configuración de carga de índice para la indexación desde la base de datos.
-
Seleccione uno de los siguientes métodos de ajuste que afectan a la velocidad de indexación global y ajuste los parámetros de ajuste como corresponda.
Nota: La combinación de varios métodos de ajuste puede producir resultados imprevisibles y afectar negativamente la velocidad de indexación general.
Opción Descripción Recomendado: Configuración basada en asignación de memoria Establezca los valores siguientes en el archivo solrconfig.xml: Lucene ramBufferSizeMBbatchSizedisable commitCount
Configuración de carga de índice basada en recuento de documentos Establezca los valores siguientes al configurar la carga de índice: batchSizecommitCount
Configuración de Solr basada en recuento de documentos Establezca los valores siguientes en el archivo solrconfig.xml: maxDocs of Solr autoCommitbatchSize- inhabilitar
commitCount
Configuración de Lucene basada en recuento de documentos Establezca los valores siguientes en el archivo solrconfig.xml: Lucene maxBufferedDocsbatchSize- inhabilitar
commitCount
Donde:- Lucene ramBufferSizeMB
- Define la cantidad de espacio de memoria, en MB, que se debe utilizar para poner en el almacenamiento intermedio los documentos indexados. Una vez que las actualizaciones de documentos acumulados superan el espacio de memoria asignada, se produce un vaciado de disco, que también puede crear segmentos nuevos o desencadenar una fusión de segmentos de índice.
- Lucene maxBufferedDocs
- Define el número de actualizaciones de documentos que se deben poner en el almacenamiento intermedio en memoria antes de que se vacíen como un nuevo segmento. Una vez que las actualizaciones de documentos acumulados superan este valor, se produce un vaciado de disco, que también puede crear segmentos nuevos o desencadenar una fusión de segmento de índice.
- maxDocs of Solr autoCommit
- Parámetro a nivel de Solr que define el número máximo de documentos indexados que se deben poner en el almacenamiento intermedio en memoria antes de que produzca un vaciado de disco. Comparado con el nivel maxBufferedDocs de Lucene, este valor no garantiza un vaciado de disco de bajo nivel. Cuando el valor maxBufferedDocs de Lucene es mayor que este tamaño de autoCommit, este valor es irrelevante.
- commitCount de carga de índice
- Define el número máximo de documentos no comprometidos que se deben poner en el almacenamiento intermedio en memoria antes de que se produzca un vaciado de disco. Este es un control a nivel de aplicación y desecha en el almacenamiento físico utilizando la API de compromiso fijo de Solr. Establezca el valor en 0 para inhabilitarlo.
- batchSize de carga de índice
- Define el número de documentos que se deben conservar en la memoria antes de comprometerse de forma flexible en Solr. Esta acción no garantiza un vaciado en disco, porque la decisión final también depende de los valores de maxDocs y de los valores ramBufferSizeMB y maxBufferedDocs de Lucene, si alguno de ellos están configurados. Establezca el valor en 0 para inhabilitarlo.
Nota: El valor de recuento de compromisos reemplaza el valor de tamaño de lote cuando el tamaño de lote es mayor que el recuento de compromiso. -
Supervise la carga de índice y utilice las métricas al indexar para ayudar a refinar los parámetros de ajuste y mejorar el rendimiento.
Para obtener más información, consulte Supervisión de carga de índice.