
Ajuste del rendimiento de búsqueda basado en Elasticsearch parte II
Varios factores influyen en el rendimiento de la creación de índices de búsqueda, incluyendo la ocupación del hardware, el tamaño del catálogo y la riqueza de datos/cardinalidad del diccionario de los atributos. Comprender los obstáculos y cómo se expresan a través de todo el proceso es crucial para ajustar la solución de búsqueda.
Información general
- Recuperación de datos.
- Procesamiento/Transformación de datos.
- Carga de datos.
- Recuperación de grupo de datos: Captar datos de la base de datos o Elasticsearch.
- Procesando grupo de datos: Para los datos captados: cree, actualice o copie los documentos de índice.
- Subirgrupo de datos: Suba el documento de índice a Elasticsearch.
Cada grupo tiene una influencia en la velocidad y la eficiencia del proceso de creación de índices. El grupo de recuperación de datos, por ejemplo, estaría en control del tamaño del archivo de flujo (tamaño de grupo) y de la frecuencia de ejecución de las consultas (tamaño de página de desplazamiento). Puede optimizar el coste de recuperación y la carga útil de la base de datos, como el bloque de datos de procesos de NiFi como una unidad, alterando estas variables. El tamaño del archivo de flujo afecta al rendimiento de carga de Elasticsearch. Las estructuras complejas y grandes pueden tardar más tiempo en analizarse en Elasticsearch, lo que resulta en una escalabilidad deficiente.
El grupo de datos de procesamiento controla la cantidad de trabajo que NiFi puede realizar. Por ejemplo, puede regular cuántos archivos de flujo pueden procesarse simultáneamente controlando el recuento de hebras del procesador. Esto aumenta la velocidad de procesamiento de un procesador típico, lo que potencialmente mejora la acumulación de los archivos de flujo frente al procesador. Por ejemplo, el procesador NLP es un procesador típico que se beneficia significativamente de las hebras adicionales. Puede controlar cuántas conexiones realiza simultáneamente a Elasticsearch utilizando el procesador de actualización masiva más especializado, lo que le permite importar más datos a Elasticsearch.
Estos escenarios se examinarán en mayor detalle en Interpretación de patrones y ajuste de la solución de búsqueda, utilizando ejemplos y datos reales.
Requisitos de infraestructura
Los requisitos de infraestructura del producto están bien definidos y, aunque NiFi/Elasticsearch puede funcionar en una huella reducida, el rendimiento podrá verse afectado. Necesita un buen ancho de banda de E/S en la infraestructura de NiFi y Elasticsearch, así como una buena cantidad de memoria para el almacenamiento dinámico y la asignación de memoria nativa de Java y, preferiblemente, suficiente memoria para el almacenamiento en caché de archivos. Es posible que sea necesario especificar este último en el pod ya que garantiza que el sistema operativo tenga suficiente RAM adicional para el servicio.
Variables ajustables clave
Las siguientes variables ajustables de clave se pueden ajustar para mejorar el tiempo de procesamiento global:
Recuento de hebras del procesador (tareas simultáneas)
El procesador predeterminado ejecuta una sola hebra a la vez, procesando un archivo de flujo a la vez. Si se desea el proceso simultáneo, se puede ajustar el número de tareas simultáneas que puede realizar. Establezca el número de hebras para el grupo de procesos cambiando el valor de Tareas simultáneas de procesador (en la pestaña Configuración del procesador o PLANIFICACIÓN ).
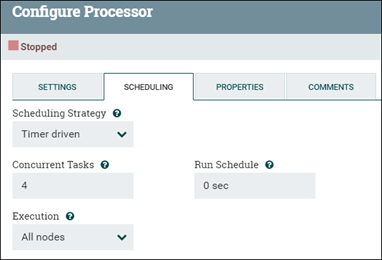
El rendimiento se puede mejorar si un CPU puede realizar varias tareas aumentando el número de hebras que emplea. El procesador de transformación (como en el NLP) y el procesador de actualización masiva son dos ejemplos de este tipo (envía datos a Elasticsearch). Esta actualización no ayuda a todos los procesadores. La mayoría de los procesadores vienen con una configuración predeterminada que tiene en cuenta esta variable y no es necesario modificarla. Cuando las pruebas de rendimiento revelan un obstáculo frente a los procesadores, la configuración predeterminada podría beneficiarse de un ajuste adicional.
Cuando el procesador puede procesar archivos de flujo a la misma velocidad a la que se reciben, el valor tareas simultáneas es ideal, y evita grandes acumulaciones de archivos de flujo en la cola de espera del procesador. Puesto que no siempre se puede alcanzar tal equilibrio, la mejor configuración se centra en reducir la acumulación de archivos de flujo en la cola de espera.