
Variables ajustables clave
Las siguientes variables ajustables de clave se pueden ajustar para mejorar el tiempo de procesamiento global:
Recuento de hebras del procesador (tareas simultáneas)
El procesador predeterminado se ejecuta en una sola hebra, procesando solo un archivo de flujo a la vez. Si se desea el proceso simultáneo, se puede ajustar el número de tareas simultáneas que puede realizar. Establezca el número de hebras para el grupo de procesos cambiando el valor de Tareas simultáneas de procesador (en la pestaña Configuración del procesador o PLANIFICACIÓN ).
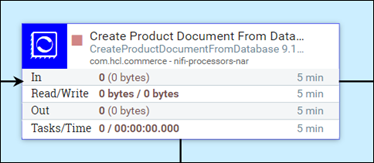
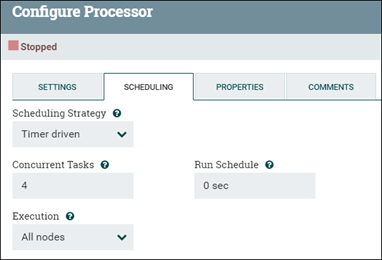
Si un CPU puede realizar varias tareas, el aumento de las hebras disponibles para el procesador aumenta el rendimiento del procesador. El procesador de transformación (como en el NLP) y el procesador de actualización masiva son dos ejemplos de este tipo. Esta actualización no es útil para todos los procesadores. La mayoría de los procesadores vienen con una configuración predeterminada que tiene en cuenta esta variable y no es necesario modificarla. Cuando las pruebas de rendimiento revelan un obstáculo frente a los procesadores, la configuración predeterminada podría beneficiarse de un ajuste adicional.
Cuando el procesador puede procesar archivos de flujo a la misma velocidad a la que se reciben, el valor tareas simultáneas es ideal, y evita grandes acumulaciones de archivos de flujo en la cola de espera del procesador. Puesto que no siempre se puede alcanzar tal equilibrio, la mejor configuración debería centrarse en reducir la acumulación de archivos de flujo en la cola de espera.
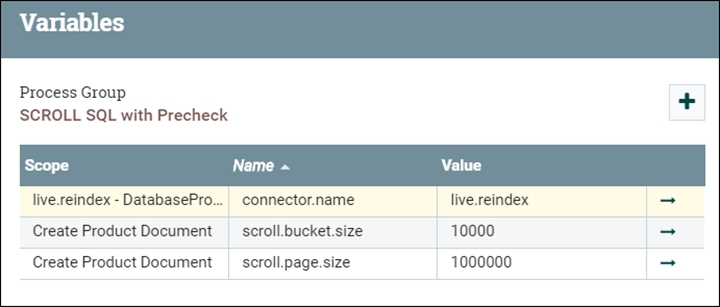
Tamaño de grupo (scroll.bucket.size)
- scroll.bucket.size
- scroll.bucket.size es el número de filas de los datos captados en cada grupo para su procesamiento.
- bucket.size
- El parámetro bucket.size determina el tamaño de los archivos de flujo (y el número de documentos que hay contenidos en cada archivo).
El tamaño de grupo es óptimo cuando ve que el archivo de flujo se procesa fácilmente a través del sistema (incluida la carga de Elasticsearch). Aumentar el tamaño (número de documentos en el archivo de flujo) aumenta el rendimiento. Sin embargo, cuando se aumenta a un tamaño muy alto, el rendimiento se reduce gradualmente. Al mismo tiempo, los recursos del sistema (NiFi y Elasticsearch) pasarán a estar bajo presión, lo que conduce a un rendimiento más bajo.
Tamaño de página de desplazamiento (scroll.page.size)
- scroll.page.size
- El parámetro scroll.page.size contiene el número de filas captadas de la base de datos por el SQL. SQL se ejecuta varias veces (una vez con cada vuelta de página) si el recuento de filas recuperadas es menor que el recuento de filas total de la tabla.
La configuración de desplazamiento es óptima cuando el tiempo que se tarda en procesar los datos coincide con el tiempo que tarda el siguiente desplazamiento de SQL en recibir sus datos. Esta mejora elimina el procesamiento innecesario y tiempo de E/S. Otros factores adicionales a tener en cuenta incluyen el espacio de memoria disponible en NiFi para contener el conjunto de resultados al analizarlo y dividirlo en archivos de flujo, y el número total de archivos de flujo que se crearían en NiFi a la vez. Si el tamaño de página de desplazamiento es mayor, cabe esperar un impacto en las operaciones de NiFi. Cuando alcance este límite, puede aumentar los recursos de NiFi o reducir el tamaño de página de desplazamiento a una medida tolerable.
- scroll.page.size es el número de documentos que se captan de Elasticsearch. Si el número es demasiado pequeño, NiFi debe realizar más conexiones con Elasticsearch.
- El parámetro scroll.bucket.size es el número de documentos incluidos de los datos captados procesados en cada grupo. El parámetro bucket.size determina el tamaño de los archivos de flujo (y el número de documentos que hay contenidos en cada archivo).