
Interpretación de patrones y ajuste de la solución de búsqueda
Dispone de varias opciones para mejorar el rendimiento general. Ajustar la introducción también implica aprender sobre posibles efectos secundarios y resultados negativos.
Un caso de transferencia de datos lenta: ejecución multihebra
La operación de transferencia de NiFi a Elasticsearch es un ejemplo de un segmento poco óptimo que puede detectar fácilmente. Esta operación suele ser gestionada por el procesador de actualizaciones masivas, que aparece en Grafana como un rápido crecimiento en el número de documentos entrantes, que luego alcanza los picos, seguido de una desacelerada disminución superficial en el número de documentos debido a la velocidad de transferencia. Como puede ver, tiene este aspecto:
Debido a la ralentización de la velocidad de transferencia a Elasticsearch, puede ver un agotamiento superficial de los documentos en la cola. Puede aumentar esta velocidad abriendo más conexiones a Elasticsearch y configurando más hebras para que el procesador de actualizaciones masiva aumente el rendimiento.
Cuando se genera el número total de hebras, el gráfico siguiente representa lo que sucede en el sistema: ![]()
Cuando el procesador de actualizaciones masivas se configura con solo tres hebras, la configuración inicial muestra un agotamiento muy superficial de los documentos. Cuando se configura con hebras 16, el ángulo de bajada de rampa aumenta significativamente, y cuando se configura con hebras 64, mejora aún más. La distinción importante es que el aumento del número de hebras en este procesador aumenta el número de conexiones HTTP abiertas desde NiFi a Elasticsearch, mientras que la utilización de CPU resultante permanece casi sin cambios.
Otros procesadores, como el grupo de procesos de NLP, podrían beneficiarse de observaciones y mejoras similares. La simultaneidad máxima posible en el sistema está restringida por el número de núcleos de CPU físicos disponibles para el pod de NiFi mientras se utilizan procesadores enlazados a la CPU como NLP.
Efectos secundarios de aumento de hebras
Aumentar el número de hebras del procesador es una modificación arriesgada que debe realizarse en pequeños incrementos y no en grandes. Por ejemplo, no se recomienda pasar de 3 a 64 hebras. Realice cambios incrementales más pequeños de 16, 32 y finalmente 64 hebras, testando cada incremento y observando los resultados. Se observa que después 32 de hebras por CPU, las ventajas son insignificantes en la mayoría de los casos.
Además, los recursos disponibles del sistema operativo para el pod/JVM en el que se ejecuta NiFi deben tenerse especialmente en cuenta. Por ejemplo, un procesador enlazado a la CPU se beneficia de la simultaneidad solo si hay núcleos disponibles en la CPU. Por otro lado, el aumento de la simultaneidad en los procesadores aumenta el tamaño de almacenamiento dinámico de JVM y la memoria nativa necesaria. Para detectar y corregir este tipo de situaciones, es fundamental supervisar los valores de almacenamiento dinámico y la memoria global.
Efectos secundarios del aumento del tamaño de grupo
El aumento del tamaño de grupo afecta en gran medida a los recursos del sistema NiFi, como el almacenamiento dinámico y, lo que es más importante, la memoria nativa. Puesto que la memoria nativa se utiliza como área de almacenamiento intermedio al enviar los datos a Elasticsearch, aumenta la ocupación total de memoria del pod.
La detección y captura de un error de este tipo es un caso poco común que a menudo se pasa por alto. Aquí se comparte un suceso de este tipo, junto con los valores de las métricas:
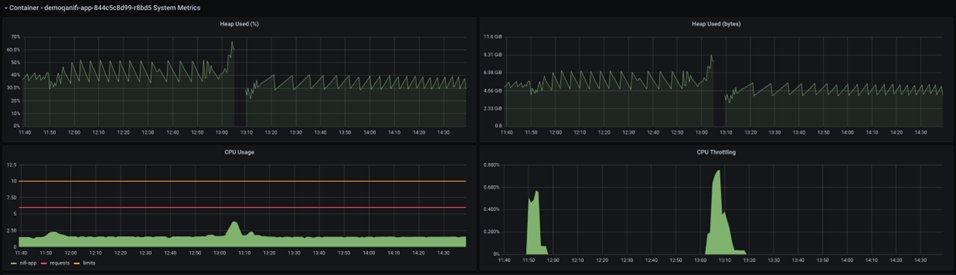
El tamaño de almacenamiento dinámico de Java se muestra en el gráfico anterior. La breve pausa en medio del gráfico refleja un bloqueo y reinicio del pod NiFi. Si observa la CPU antes del fallo, puede ver un pico en la utilización de la CPU, pero el tamaño de almacenamiento dinámico nunca alcanza el 100 % , sino que se mantiene alrededor del 70 %, que es un tamaño de almacenamiento dinámico razonable.
Sin embargo, el gráfico siguiente muestra una imagen totalmente diferente:
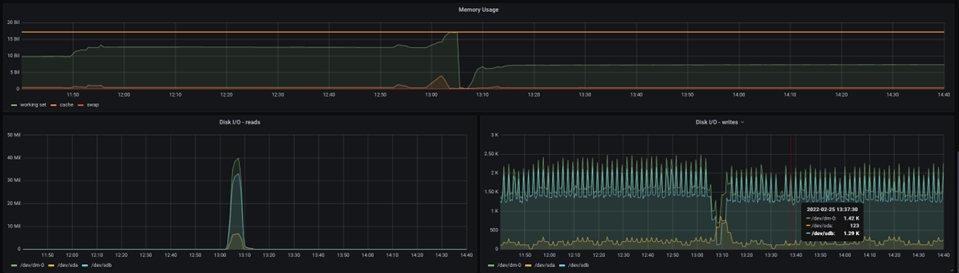
Aquí se muestra la memoria total asignada al pod, y puede ver que la memoria solicitada está alcanzando el máximo de memoria asignada en el momento de la caída de la JVM de NiFi. Como resultado, se debe asignar más memoria para dar cabida a un tamaño de grupo más grande.
Con un tamaño de grupo grande, puede surgir un problema diferente: Elasticsearch puede ralentizar significativamente la importación de datos a medida que aumenta el tamaño del archivo de flujo, hasta el punto en que las ventajas de NiFi se inutilizan completamente y el procesamiento se degrada debido a la importación de datos de Elasticsearch. Organice y realice un seguimiento de las pruebas de introducción con diferentes valores de tamaño de grupo para evitar dichas situaciones y resultados confusos.
Un caso de procesamiento lento: ajuste de tamaño de desplazamiento
La ralentización de la entrega de datos a NiFi es la tercera razón más común del retardo del procesamiento de datos. Esto podría deberse a la falta de potencia de procesamiento de bases de datos, a un ajuste inadecuado o a una personalización ineficaz. Aunque este problema se aborda a través de la base de datos, a veces es mucho más eficiente optimizar el acceso a datos de NiFi para minimizar el impacto de la sobrecarga de la base de datos en la ejecución de Ingest.
En este caso concreto, la ralentización será visible dentro de los gráficos de Grafana como tiempo de inactividad entre los picos de los elementos en cola. Esto sucede cuando el parámetro scroll.size está configurado para ser relativamente bajo en comparación con el tamaño total de la tabla de bases de datos a la que se accede. Lo idóneo es que scroll.size coincida con el tiempo de procesamiento, en cuyo caso, el tiempo de consulta de base de datos debe ser igual al tiempo de procesamiento de NiFi de los datos extraídos. Sin embargo, en casos especiales en los que el SQL se ejecuta durante más tiempo que el procesamiento de NiFi, esto podría observarse como picos cortos en el gráfico de elementos consultados, separados por una línea horizontal/inactiva.
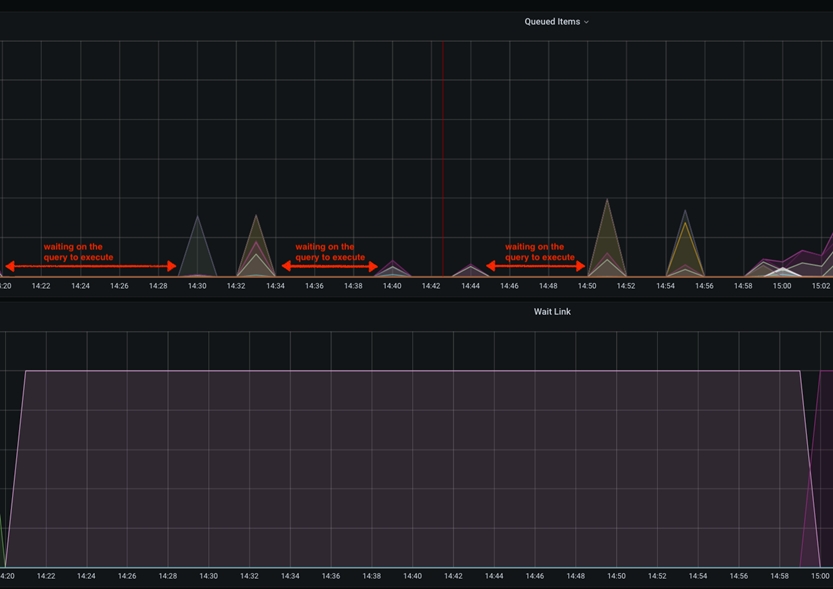
Este tiempo de inactividad entre las captaciones de los datos de las bases de datos se puede mitigar aumentando el valor de scroll.page.size a un número más alto. Por ejemplo, si la base de datos tiene un total de 1 M de artículos del catálogo y scroll.page.size se establece en 100000 elementos, todo el proceso incluye 10 iteraciones. Esto indica que los elementos de la cola tienen 10 picos, con intervalos de tiempo de inactividad. Puede reducir el tiempo de espera en un 50 % aumentando scroll.page.size a 200000, reduciendo así los ciclos a 5 ciclos. Debería establecer scroll.page.size en 1M para que se puedan recuperar todos los datos en un ciclo y solo se observe un periodo de inactividad para la fase de procesamiento. El gráfico siguiente muestra uno de estos casos:
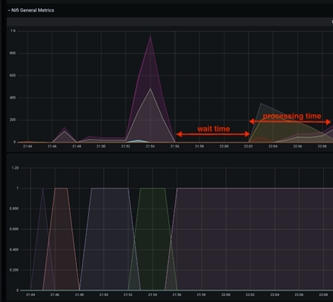
Efecto secundario de tamaños de desplazamiento muy grandes
Puesto que el efecto de cambiar el pod de NiFi puede ser considerable, este ajuste menor debe estudiarse con detenimiento. Dado que todos los datos se envían a NiFi al mismo tiempo, necesitará suficiente almacenamiento y RAM para que el pod siga funcionando sin problemas. Si NiFi se está quedando sin almacenamiento dinámico, memoria nativa o espacio de almacenamiento, se debe supervisar y modificar cuidadosamente para mantener un rendimiento óptimo.
Buscar el punto óptimo
En general, la estrategia descrita debería proporcionar un ajuste y una prueba de rendimiento de las operaciones NiFi/ Elasticsearch supervisados y medidos. Aunque algunas variables de ajuste tienen un mayor impacto en el sistema, debe tener en cuenta las tres para obtener un rendimiento óptimo del sistema.
Debido a los efectos secundarios, se producen cambios de variables de ajuste muy grandes que pueden afectar negativamente al tiempo total de procesamiento. Hay que tener en cuenta de nuevo que se debe supervisar y medir cualquier cambio cuidadoso de los valores, asegurándose de que cada cambio individual produzca un cambio positivo (mejora) en el tiempo de proceso global.
Otras consideraciones
- Tamaño de antememoria
"[${TENANT:-}${ENVIRONMENT:-}live]:services/cache/nifi/Price": localCache: maxSize: -1 maxSizeInHeapPercent: 8 (default 2) remoteCache: enabled: false remoteInvalidations: publish: false subscribe: false "[${TENANT:-}${ENVIRONMENT:-}auth]:services/cache/nifi/Inventory": localCache: maxSize: -1 maxSizeInHeapPercent: 8 (default 2) remoteCache: enabled: false remoteInvalidations: publish: false subscribe: false "[${TENANT:-}${ENVIRONMENT:-}auth]:services/cache/nifi/Bulk": localCache: maxSize: -1 maxSizeInHeapPercent: 4 (default 1) remoteCache: enabled: false remoteInvalidations: publish: false subscribe: false "[${TENANT:-}${ENVIRONMENT:-}auth]:services/cache/nifi/Wait": localCache: maxSize: -1 maxSizeInHeapPercent: 4 (default 1) remoteCache: enabled: false