Personalización de perfiles de Ingest
Puede utilizar perfiles de Ingest personalizados para invalidar temporalmente la definición del esquema de índice. También puede utilizarlos para personalizar el flujo lateral de extracción, transformación y carga (ETL) del proceso de Ingest y para servicios masivos. Existen métodos de Java para facilitar la personalización de cada etapa.
{ "profileName": "DatabasePriceStage1a", "provider": [ "com.mycompany.data.ingest.product.providers.ChangeSQL" ], "preprocessor": [], "postprocessor": [] } Puede desarrollar y crear las extensiones Java personalizadas utilizadas por el perfil dentro de NiFi Toolkit en Eclipse. Para activar los binarios, los tiene que empaquetar y desplegar en la carpeta /lib del contenedor NiFi.
Personalización de definiciones de esquema de índice
Puede personalizar la definición de esquemas de índice durante la etapa de preparación del índice. Puede definir el proveedor de esquemas utilizando un perfil de Ingest y establecerlo a nivel de canal de esquema de conector.
IndexSchemaProvider. El método se define de la forma siguiente.public interface IndexSchemaProvider { public String invoke(final ProcessContext context, final ProcessSession session, final String schema) throws ProcessException; }- contexto
- Proporciona acceso a métodos prácticos para obtener valores de propiedad, retrasar la planificación del procesador, proporciona acceso a los servicios de controlador, etc.
- sesión
- Proporciona acceso a un {@link ProcessSession}, que se puede utilizar para acceder a FlowFiles, etc.
- esquema
- Contiene el valor de esquema de índice de Elasticsearch y la definición de asignación.
- devolución
- La definición del esquema modificado.
- emite
- Genera una ProcessExeption si el procesamiento no se ha completado normalmente.
public class MyProductSchemaProvider implements IndexSchemaProvider { @override public String invoke(final ProcessContext context, final ProcessSession session, final String schema) throws ProcessException { String mySchema = schema; // TODO: logic for customizing schema definition goes here return mySchema; } }{ "profileName": "MyProductSchema", "provider": [ "com.mycompany.data.index.product.providers.MyProductSchemaProvider" ] }Personalización de lógicas de ETL predeterminadas
El servicio Ingest realiza las operaciones de extracción, transformación y carga (ETL) esenciales en datos de negocio que hacen que estén disponibles para el índice de búsqueda. Cada canal de un conector es responsable de realizar una o más operaciones de ETL y puede añadir y personalizar sus propias canalizaciones.
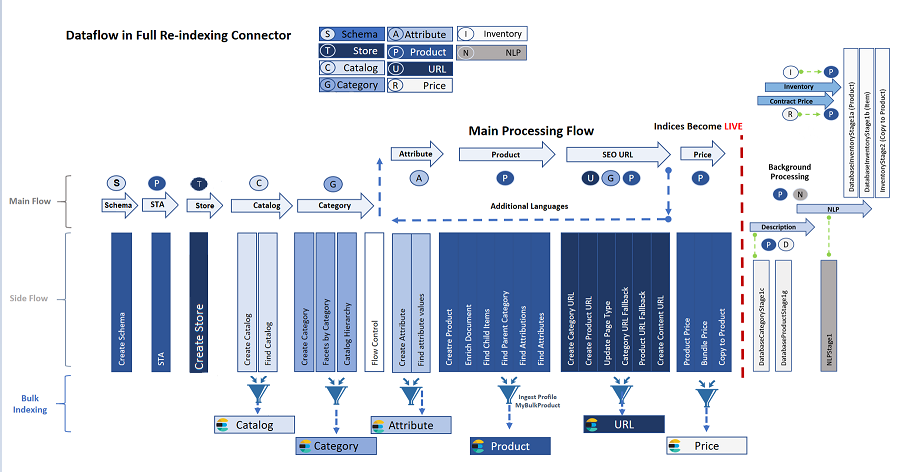
La canalización de indexación consta de un flujo principal, en el que se mueven de forma lineal los datos que el servicio Ingest sabe cómo extraer de entrada a salida; y un flujo lateral de ETL, que tiene varias etapas cuyo comportamiento puede personalizar. El diagrama siguiente muestra el modelo de diseño para el sistema.
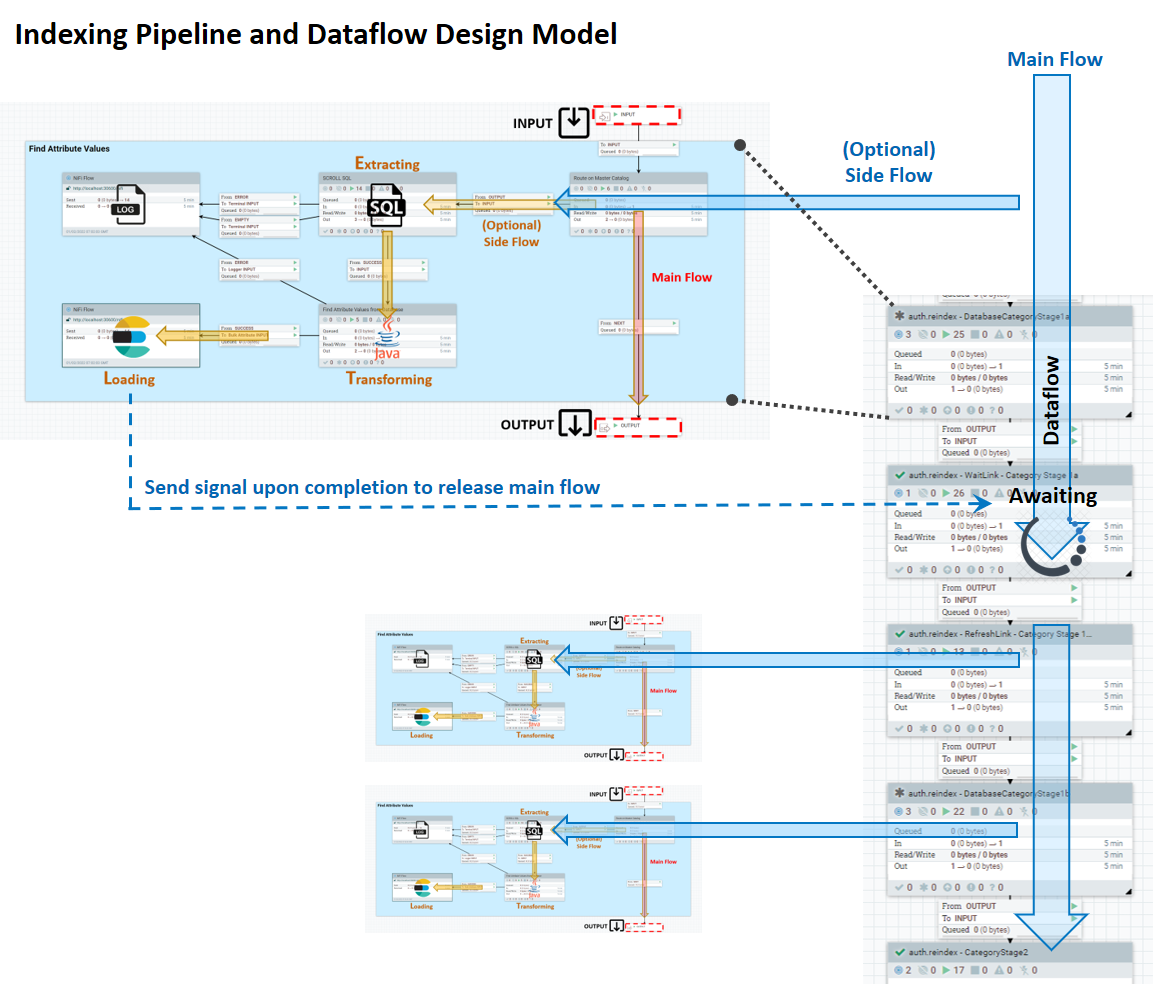
Los procesos de ETL tienen lugar en el flujo lateral de entrada de datos. En el flujo lateral, la extracción se gestiona mediante las consultas de SQL, la transformación se realiza utilizando expresiones de Java y la carga la realiza Elasticsearch. Un perfil de Ingest le permite definir proveedores SQL de Java adicionales para la etapa de extracción y preprocesadores y postprocesadores, también en Java.
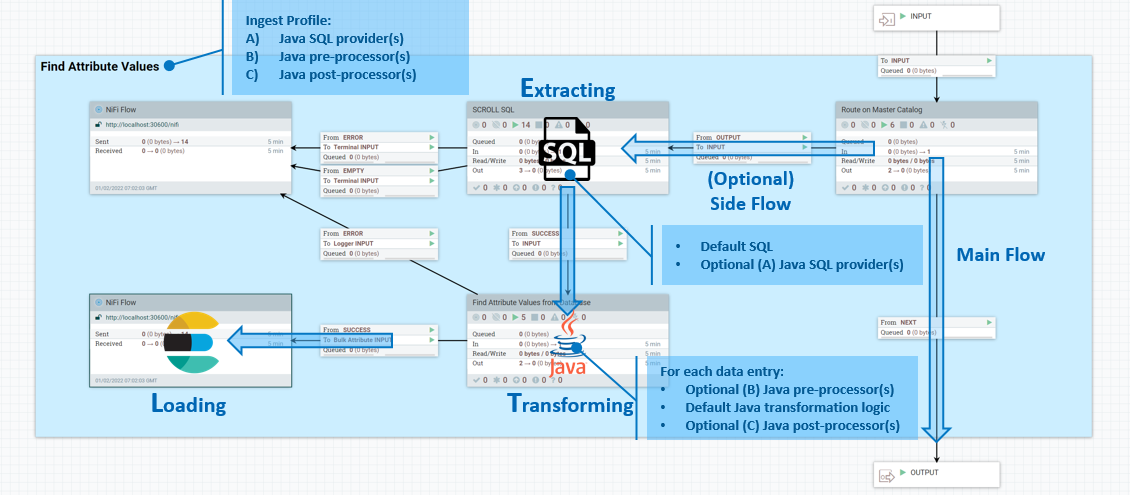
Etapa de extracción
IngestExpressionProvider como salida personalizada para personalizar ETL. La interfaz se define de la forma siguiente.public interface IngestExpressionProvider { public String invoke(final ProcessContext context, final ProcessSession session, final String expression) throws ProcessException;- contexto
- Proporciona acceso a métodos prácticos para obtener valores de propiedad, retrasar la planificación del procesador y proporcionar acceso a los servicios de controlador, entre otros.
- sesión
- Proporciona acceso a
{@link ProcessSession}, que se puede utilizar para acceder a archivos de flujo y a otros procesos. - expresión
- Contiene la expresión SQL de base de datos que se va a ejecutar.
- devolución
- La expresión SQL modificada.
- emite
ProcessExceptionsi el procesamiento no se ha completado normalmente.
Para personalizar la fase de extracción del proceso ETL, puede intervenir en la lógica dentro de la parte SCROLL SQL del flujo lateral. La ubicación exacta en el flujo de NiFi es auth.reindex-Product Stage 1a (Main Document)/Create Product Document/SCROLL SQL.
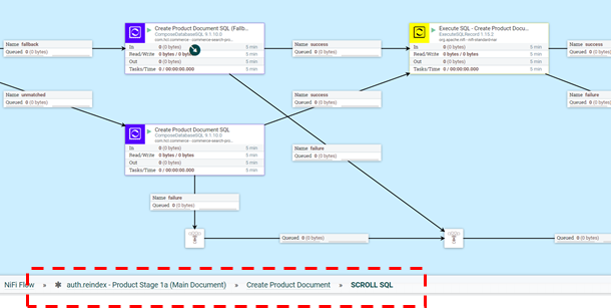
public class MyProductStage1aProvider implements IngestExpressionProvider { @override public String invoke(final ProcessContext context, final ProcessSession session, final String expression) throws ProcessException { String myExpression = expression; //Logic for customizing database SQL expression goes here return myExpression; } }Etapa de preprocesamiento
IngestFlowPreProcessor a su perfil, como una salida de usuario personalizada antes de que se produzca la transformación del flujo en la etapa actual. La interfaz se define de la forma siguiente.public interface IngestFlowPreProcessor { public Map<String, Object> invoke (final ProcessContent context, final ProcessSession session, final Map<String, Object> data) throws ProcessException; }- contexto
- Proporciona acceso a métodos prácticos para obtener valores de propiedad, retrasar la planificación del procesador y proporciona acceso al controlador y otros servicios.
- sesión
- Proporciona acceso a
{@link ProcessSession}, que se puede utilizar para acceder a archivos de flujo y a otros servicios. - data
- Contiene una entrada del conjunto de resultados de la base de datos.
- devolución
- Los datos modificados para el proceso de sentido directo.
- emite
ProcessExceptionsi el proceso no se ha completado correctamente.
IngestFlowPreProcessor.public class MyProductStage1aPreProcessor implements IngestFlowPreProcessor { @Override public Map<String, Object> invoke(final ProcessContext context, final ProcessSession session, final Map<String, Object> data) throws ProcessException { // TODO: logic for customizing database result entry goes here return myData; } } Postproceso
IngestFlowPostProcessor como a una salida de usuario personalizada después de la etapa de transformación y antes de la etapa de carga. El método se define de la forma siguiente.public interface IngestFlowPostProcessor { public Map<String, Object> invoke(final ProcessContext context, final ProcessSession session, final Map<String, Object> data, final Map<String, Object> document) throws ProcessoException;- contexto
- Proporciona acceso a métodos prácticos para obtener valores de propiedad, retrasar la planificación del procesador y proporciona acceso al controlador y otros servicios.
- sesión
- Proporciona acceso a
{@link ProcessSession}, que se puede utilizar para acceder a archivos de flujo y a otros servicios. - data
- Contiene una entrada del conjunto de resultados de la base de datos.
- documento
- Contiene un objeto Json que representa el documento final que se enviará a Elasticsearch.
- devolución
- Los datos modificados para el proceso de sentido directo.
- emite
ProcessExceptionsi el proceso no se ha completado correctamente.
La siguiente captura de pantalla muestra un ejemplo de código utilizado para ampliar la etapa de postproceso a través de IngestFlowPostProcessor. Aquí, myDocument representa el documento Json final que se enviará a Elasticsearch.
public class MyProductStage1aPostProcessor implements IngestFlowPostProcessor { @override public Map<String, Object> invoke(final ProcessContext context, final ProcessSession session, final Map<String, Object> data, final Map<String, Object> document) throws ProcessException { Map<String, Object> myDocument = new HashMap(document); // TODO: logic for customizing the Json document before sending to Elasticsearch // // For example .... final Map<String, String> x_field1 = new HashMap<String, String>(); // Retrieve value of FIELD1 from database result entry final String FIELD1 = (String) data.get("FIELD1"); // Insert value of FIELD1 into the resulting document to be sent to Elasticsearch if (StringUtils.isNotBlank(FIELD1)) { // Re-use default dynamic keyword field name "*.raw" (can be found from Product index schema) String field1 = FIELD1.trim(); // // TODO: perform your own transformation of field1 // x_field1.put("raw", field1); // x_field1.raw myDocument.put("x_field1", x_field1); } return myDocument; } }Personalización de servicios masivos
El flujo de reindexación completo continúa como un conjunto de etapas con flujos secundarios opcionales. La salida de estos flujos laterales se canaliza a través de servicios masivos y en cada índice correspondiente. Cada índice tiene un servicio masivo específico y puede enlazarse un perfil de Ingest a este servicio si es necesario inyectar una salida de usuario personalizada en este flujo de datos. También puede llamar a un preprocesador y posprocesador en esta etapa, antes de enviar la carga útil masiva a Elasticsearch y después de recibir la respuesta de Elasticsearch.
Creación de personalizaciones
- Creación de un entorno de desarrollo con el kit de herramientas de NiFi. Para obtener más información, consulte Configuración de HCL Commerce Developer Search environment.
- Desarrolle y pruebe por unidad las lógicas personalizadas de su perfil de Ingest.
- Cree la configuración de su perfil de Ingest y enlácela con un canal de conector en un entorno de ejecución de NiFi.
- Despliegue las extensiones personalizadas de su perfil de Ingest en el entorno de ejecución de NiFi para realizar más pruebas.
Para obtener una guía de aprendizaje detallada sobre cómo personalizar, probar y desplegar las personalizaciones a través de los perfiles de Ingest, consulte Guía de aprendizaje: Personalización de conectores predeterminados con un perfil de Ingest. En esta guía de aprendizaje se tratan temas como los requisitos previos del entorno de desarrollo, la creación y transferencia de archivos personalizados .jar al entorno.
Pruebas y depuración
Puede realizar la codificación y las pruebas de la unidad dentro del kit de herramientas de NiFi basado en Eclipse utilizando datos simulados, mediante la opción de prueba de JUnit proporcionada por Maven. En el archivo commerce-custom-search-marketplace-seller.zip se proporcionan dos ejemplos de pruebas de unidad. Estos archivos son ComposeDatabaseSQLTest.java, y CreateProductDocumentFromDatabaseTest.java.
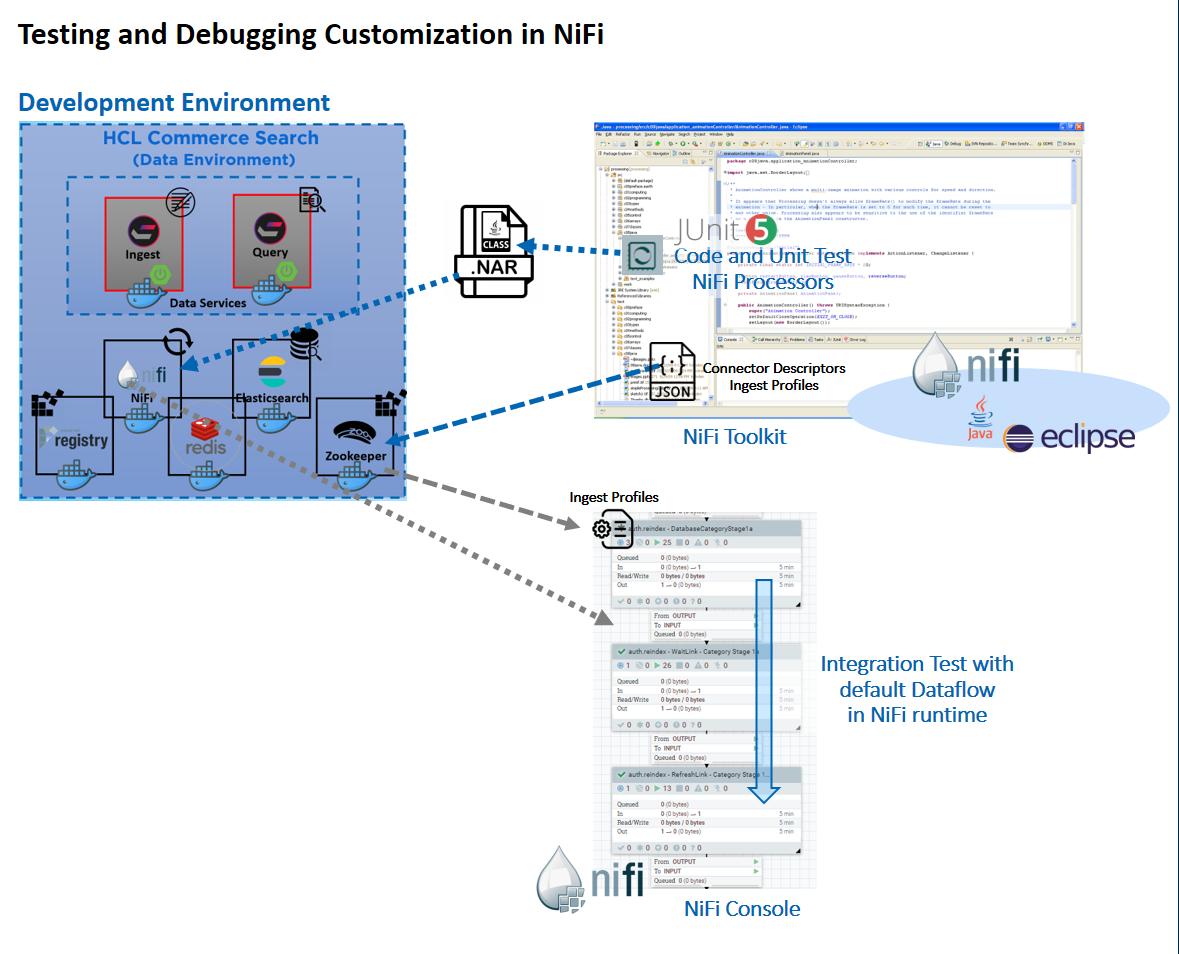
ChangeSQL es un proveedor de expresiones de perfil de Ingest. Puede utilizar esta referencia de ejemplo para aprender a modificar el SQL utilizado en las etapas predeterminadas de Extracción, Transformación y Carga (ETL). ComposeDatabaseSQLTest es la prueba de JUnit que se puede utilizar para verificar la lógica de código dentro de ChangeSQL.
ChangeDocument es una extensión de postprocesador del perfil de Ingest que muestra cómo puede realizar una manipulación de datos más detallada después de la transformación predeterminada, en una de las etapas de Ingest relacionadas con el producto. CreateProductDocumentFromDatabaseTest es la prueba de JUnit que se puede utilizar para verificar la lógica del código dentro de ChangeDocument.
Una vez que las configuraciones personalizadas y la lógica de extensión Java están preparadas, se pueden exportar a un archivo NAR NiFi personalizado y añadirse al contenedor NiFi. Esto le permite probar la lógica personalizada con el flujo de datos predeterminado en el tiempo de ejecución de NiFi.
Para ejecutar la prueba de JUnit, pulse el botón derecho del ratón en la clase de prueba de JUnit elegida y elija Ejecutar como... o .