Tablas de base de datos personalizadas para la interfaz
Puede obtener datos de catálogo de la base de datos añadiendo una tabla de base de datos personalizada para CATENTRY y CATGROUP. También puede controlar cómo se serializan los datos de base de datos en Elasticsearch para que entren conjuntos de datos grandes.
Procedure
-
Establezca las siguientes variables NiFi en las canalizaciones
ReindexLink,NRTLinkyDataloadLink.- Utilice custom.table.catentry para proporcionar una tabla CATENTRY personalizada para refinar el ámbito base de las SQL de entrada de catálogo.
- Utilice custom.where.catentry para proporcionar una cláusula Where personalizada de la tabla CATENTRY personalizada.
- Utilice custom.table.catgroup para proporcionar una tabla CATGROUP personalizada para refinar el ámbito base de los SQL de grupo de catálogo.
- Utilice custom.where.catgroup para proporcionar una cláusula Where personalizada de la tabla CATGROUP personalizada anterior.Note: Una vez definida una tabla personalizada, se generará un conjunto equivalente de variables TI_DELTA de archivo de flujo. El nombre de variable similar empieza por X_CUSTOM en lugar de TI_DELTA.
Utilice estas variables "custom table" y "custom condition" para generar una condición INNER JOIN para todos los SQL de las canalizaciones predeterminadas.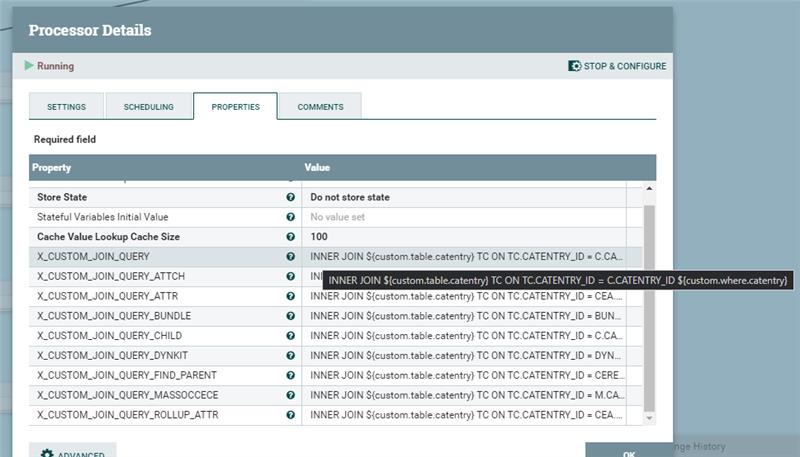 Utilice la variable X_CUSTOM_JOIN_QUERY en el SQL declarado en cada una de las con canalizaciones de conector. Por ejemplo,
Utilice la variable X_CUSTOM_JOIN_QUERY en el SQL declarado en cada una de las con canalizaciones de conector. Por ejemplo,
-
Opcional: Si desea permitir alterar temporalmente el nombre de esquema de base de datos, siga los pasos anteriores para actualizar las variables NiFi en
ReindexLink,NRTLinkyDataloadLink. Sin embargo, utilice flow.database.schema para definir el nombre de esquema de base de datos personalizado que se utilizará para la indexación.