
Perfiles de Ingest
Puede utilizar perfiles de Ingest para definir extensiones Java para la extracción de datos de base de datos SQL y para definir la lógica de transformación de datos. Los perfiles de Ingest están enlazados a canalizaciones de conector y se ejecutan como parte del proceso de canalización.
- 1. Extracción de datos
- Puede asignar SQL predeterminado a un atributo
ingest.database.sqlde archivo de flujo para que los proveedores de SQL en sentido descendente opcionales implementados en Java puedan realizar modificaciones adicionales en él. - 2. Transformación de datos
- Puede utilizar una lista de preprocesadores Java opcionales para modificar el conjunto de resultados de base de datos antes de enviarlo a la lógica de transformación predeterminada. También puede proporcionar otra lista de posprocesadores Java opcionales. Estos pueden realizar una personalización adicional en el documento de Elasticsearch generado por la lógica predeterminada antes de enviarlo a Elasticsearch para la indexación.
Puede desarrollar y crear estas extensiones Java personalizadas de la misma manera que un procesador NiFi típico, dentro de NiFi Toolkit en Eclipse. Para activar los binarios, empaquételos e impleméntelos en la carpeta /lib dentro del contenedor NiFi.
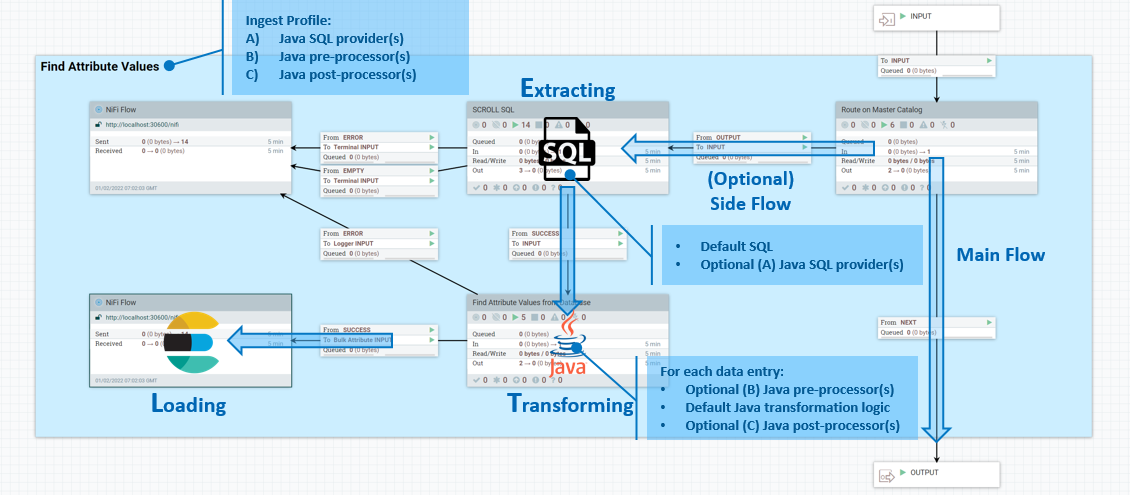
Gestión de perfiles de Ingest
profileType=Ingest que se ha añadido a las API de perfiles existente en la aplicación de servicio de consulta. Puede encontrar el punto final en http://query_host:query_port/search/resources/api/v2/documents/profiles?profileType=Ingest Tenga en cuenta que /profiles contiene un directorio, custom, con otros tres subdirectorios en su interior: ingest, nlp y search. Puede colocar perfiles personalizados en el subdirectorio adecuado. Esto permite que las imágenes de consulta de datos personalizadas incluyan sus propias configuraciones personalizadas. Estas se pueden crear utilizando su propia canalización de CI /CD. De este modo, las imágenes se pueden reutilizar en varios entornos, sin necesidad de utilizar configuraciones del ZooKeeper específico del entorno.
Tenga en cuenta que /profiles contiene un directorio, custom, con otros tres subdirectorios en su interior: ingest, nlp y search. Puede colocar perfiles personalizados en el subdirectorio adecuado. Esto permite que las imágenes de consulta de datos personalizadas incluyan sus propias configuraciones personalizadas. Estas se pueden crear utilizando su propia canalización de CI /CD. De este modo, las imágenes se pueden reutilizar en varios entornos, sin necesidad de utilizar configuraciones del ZooKeeper específico del entorno.
Para obtener más información sobre la API de consulta, consulte Especificaciones de API de servicio de consulta.