Ampliación del servicio Ingest
El servicio de la versión 9.1 HCL Commerce Search incluye Ingest y Elasticsearch, que juntos forman un motor de análisis y búsqueda distribuido y escalable. Puede encadenar las agregaciones basadas en reglas del servicio Ingest para aumentar la relevancia de los SKU de Hero o ciertas facetas, y utilizar métricas sofisticadas para analizar el rendimiento de su búsqueda.
HCL Commerce Search proporciona análisis y búsqueda en tiempo real. Como un almacén de documentos distribuidos que utiliza datos estructurados y no estructurados, se puede utilizar para muchos fines además de las búsquedas de sitio. En HCL Commerce, el cliente primario de Ingest es el sistema de búsqueda de alto rendimiento de Elasticsearch . Ingest utiliza una tecnología configurable denominada NiFi y sus canales de conector personalizados.
Indexación de los flujos de datos
La canalización de indexación consta de un flujo principal, en el que se mueven de forma lineal los datos que el servicio Ingest sabe cómo extraer de entrada a salida; y un flujo lateral de ETL, que tiene varias etapas cuyo comportamiento puede personalizar. El diagrama siguiente muestra el modelo de diseño para el sistema.
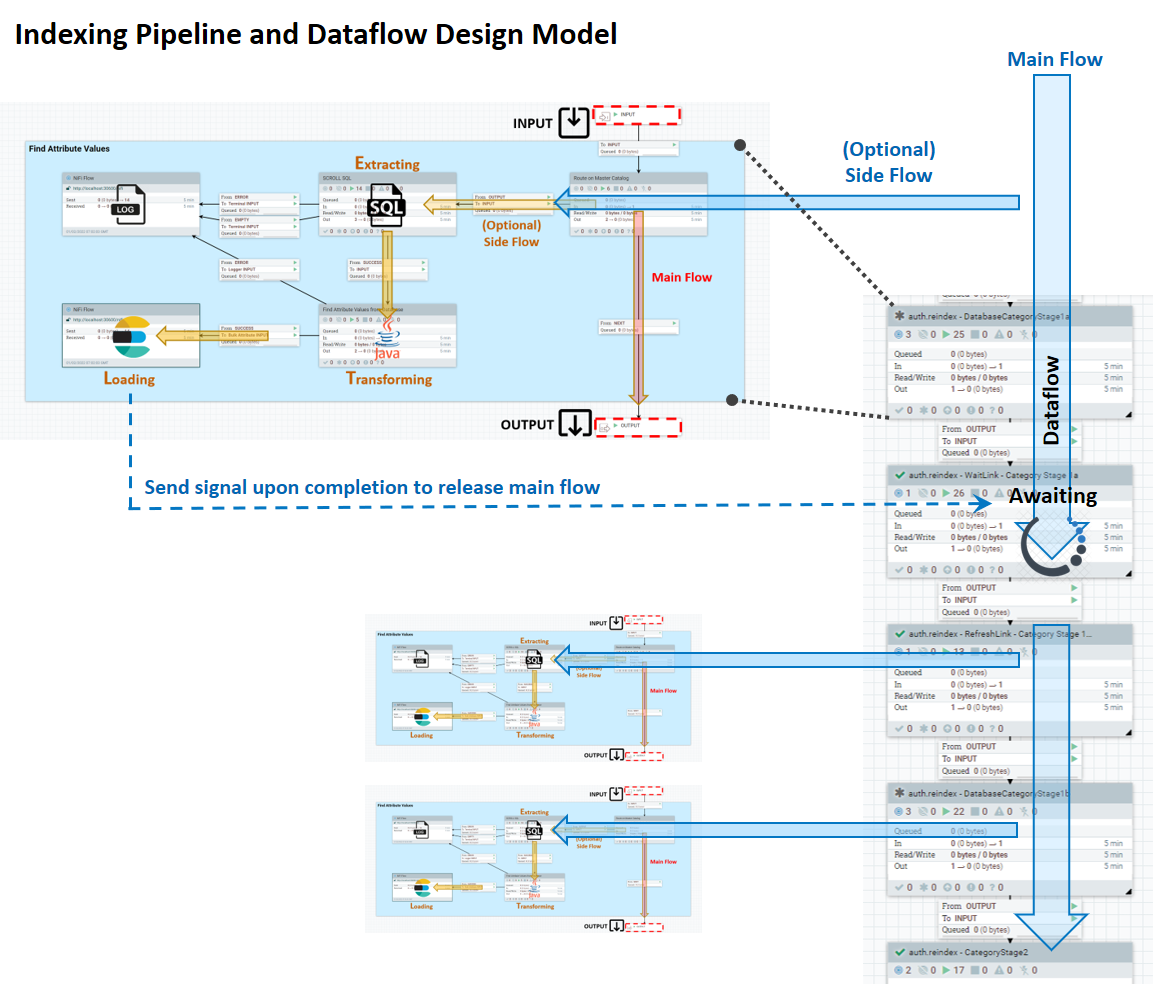
- ENTRADA: puerto de entrada del flujo de éxito anterior
- PRINCIPAL: Lógica de proceso de ETL, por ejemplo:
- Leer desde un almacén de datos externo
- Procesar cada entrada de datos que se lee
- Enviar uno o más documentos de datos procesados (indexación lista) a Elasticsearch
- SALIDA: puerto de salida al siguiente canal.
Un enlace conecta un conducto con otra conexión o canalización. Un enlace utilizado con frecuencia es un WaitLink. Este enlace pausa el flujo de datos hasta la finalización de la etapa actual, con uno de los estados siguientes: satisfactoria, parcialmente satisfactoria o fallida.
Se proporciona un servicio de registro con Ingest para realizar un seguimiento de los mensajes y los estados de conexiones individuales a medida que los datos fluyen por el sistema.
Desplegar personalizaciones
Puede ampliar el flujo de datos predeterminado creando un nuevo conector o modificando un conector predeterminado existente para incluir conexiones personalizadas. Posteriormente se pueden almacenar y crear versiones en un registro de NiFi personalizado independiente.
Cree canalizaciones de conector personalizadas (también conocidas como grupos de procesos de NiFi) en su entorno de desarrollo. Estas canalizaciones se pueden probar en un NiFi local o en un entorno de prueba y desarrollo de Commerce integrado. Una vez que sus canalizaciones personalizadas están listas, se pueden promocionar a entornos más altos para realizar pruebas y despliegues. Para obtener información sobre cómo crear sus propios conectores, consulte Crear un conector de servicio NiFi .
Utilice un sistema de control de versiones de origen independiente como repositorio maestro para mantener sus propios conductos personalizados. El registro de NiFi solo se utiliza para coordinar el release de versiones con la canalización que están en funcionamiento y no se puede utilizar como almacenamiento permanente de las canalizaciones de conector personalizadas.
Clústeres de Elasticsearch enHCL Commerce
- Nodo maestro
- El clúster elige automáticamente el nodo maestro y controla su comportamiento. Si un nodo maestro se desactiva, el clúster elegirá otro en su lugar. Los nodos maestros son obligatorios en los clústeres de Elasticsearch.
- Nodos de datos
- Estos nodos contienen datos de negocio y utilizan Apache Lucene para realizar operaciones de creación, lectura, actualización y supresión en los datos. Los nodos de datos reconocen dos tipos de datos, activos y cálidos; los datos activos o utilizados con frecuencia se almacenan en memoria caché, preferiblemente en un entorno SSD.
- Coordinación de nodo
- Los nodos de coordinación transfieren los resultados de búsqueda entre los nodos de datos.
- Nodos de introducción
- HCL Commerce Search with Elasticsearch utiliza nodos de Apache NIFI como canalización de admisión. Esta canalización transforma y enriquece los documentos entrantes antes de que se indexen. Tiene una cola persistente para la entrega garantizada.
Índices y fragmentos
El índice Elasticsearch es un espacio de nombres lógico que se correlaciona con instancias del motor de búsqueda de Apache Lucene que se ejecuta dentro de los nodos de datos. El índice Elasticsearch es similar en función a una tabla en una base de datos relacional. Para obtener una descripción completa de los campos de índice de Elasticsearch, consulte Tipos de campos de índice de Elasticsearch .
Los motores de Lucene se conocen como fragmentos. La implementación HCL Commerce de Elasticsearch utiliza dos tipos de fragmento: un fragmento primario que puede realizar tanto operaciones de lectura como de escritura y fragmentos de réplica que están optimizados solo para operaciones de lectura.