Uso del servicio HCL Commerce Search
Con la versión 9.1, HCL Commerce introduce un nuevo servicio para la introducción y organización de los datos. Esta nueva versión de HCL Commerce Search es un sistema de gestión de datos genérico que pueden utilizar otros subsistemas de comercio, incluyendo pero sin limitarse al motor de Elasticsearch. Junto con el servicio de introducción que aporta los datos, el nuevo servicio de consulta proporciona un proceso de lenguaje natural, un reconocimiento de color y mucho más. Para los clientes que necesitan compatibilidad con versiones anteriores, la solución de búsqueda basada en Apache Solr anterior sigue estando disponible.
El servicio HCL Commerce Search introducido en la versión 9.1 le proporciona una escalada mejorada, una administración más simple y una seguridad mejorada. Esta arquitectura incluye Elasticsearch como el microservicio de búsqueda de versión 9.1 preferido. HCL Commerce El sistema de búsqueda de la versión 9.1 es compatible con versiones anteriores con el de la versión 9.0. La API de búsqueda sigue siendo la misma independientemente de si utiliza Solr o Elasticsearch, lo que significa que la mayoría de las implementaciones podrán conmutar a Elasticsearch sin impacto en el escaparate. Si ha personalizado previamente la configuración o plantillas de indexación o el tiempo de ejecución de búsqueda, es posible que tenga que migrar las personalizaciones.
- Proceso de lenguaje natural (NLP) con Stanford CoreNLP. El sistema NLP mejora la relevancia de la búsqueda, con los modelos proporcionados para inglés, español, francés, alemán, árabe y chino.
- La mayoría de modelos de idiomas de CoreNLP son capaces de realizar la codificación, lematización, codificación de parte de voz, nombre-entidad-reconocimiento, división de oraciones y análisis de forma de idea. Pueden realizar análisis gramaticales con el área, el análisis de dependencia y la coreferenciación.
- Se ha añadido un procesador NLP adicional para proporcionar prestaciones de Matchmaking adicionales, tales como buscar colores o medidas similares, y conversión automática de medidas.
- Totalmente integrado con Elasticsearch como la tecnología de búsqueda central predeterminada.
- Soporte multilingüe mejorado con más de 30 analizadores específicos del idioma incorporados para el análisis de texto como, por ejemplo, la señalización, la lematización, las palabras de detención.
- Las fragmentaciones de índice dinámico permiten que se añadan más nodos de forma dinámica y reequilibren los datos automáticamente en el clúster sin tiempo de inactividad cero.
- Intercambio en caliente de índices recién creados utilizando alias de índice. La reindexación tiene un impacto mínimo en el clúster de índice activo.
- Instantáneas incrementales rápidas, que le permiten realizar copias de seguridad a rangos frecuentes.
- Introducción de datos a través de canalizaciones de indexación en Apache NiFi.
- El servicio HCL Commerce Search soporta totalmente el marketing de varios niveles y las características en tiempo casi real.
- Interfaz de despliegue preparada para Kubernetes.
- Actualización de servicio sin interrupciones y control de versiones. Una actualización sin interrupciones del contenedor de servicios permite que se entreguen continuamente nuevas características y arreglos de errores a través de paquetes de servicio recurrentes.
La pila de contenedores Docker que ejecuta los microservicios se aloja en UBI8 y utiliza la infraestructura de Spring Boot.
El siguiente diagrama muestra la arquitectura de HCL Commerce Search. Los microservicios del recuadro principal estaban dentro del contenedor de búsqueda monolítico en la versión 9.0. Estos servicios ahora se han dividido en sus propios contenedores y se comunican a través del entorno de datos.
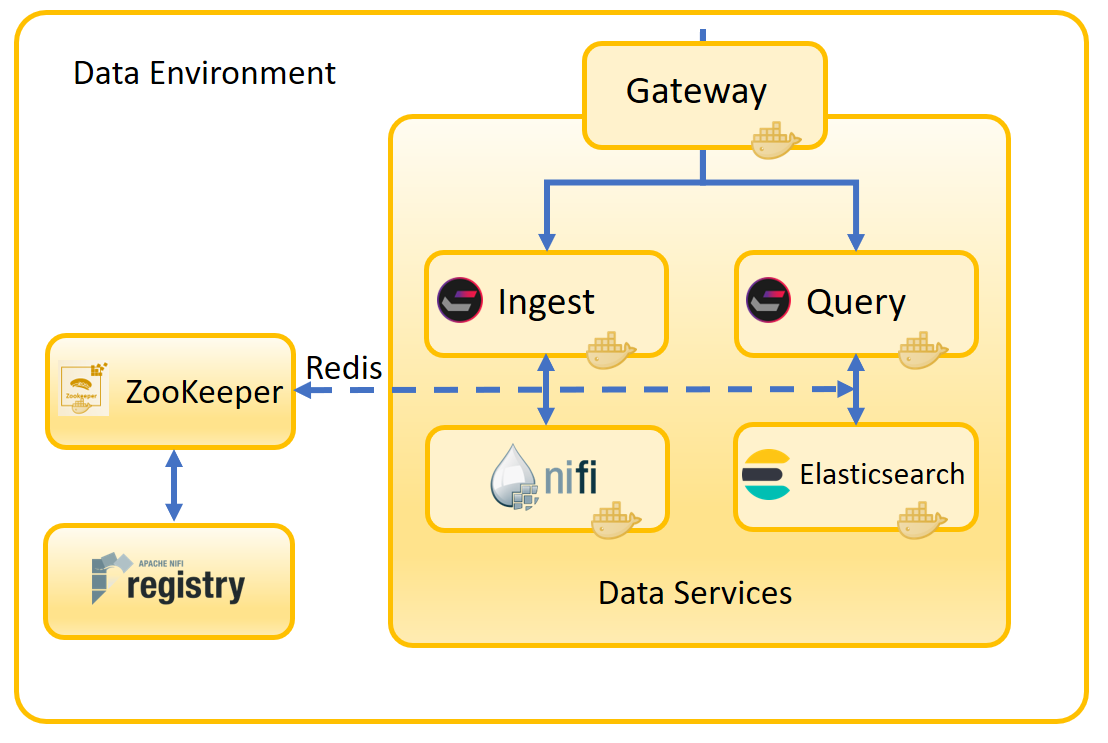
Los componentes de HCL Commerce Search son:
- El servicio de introducción
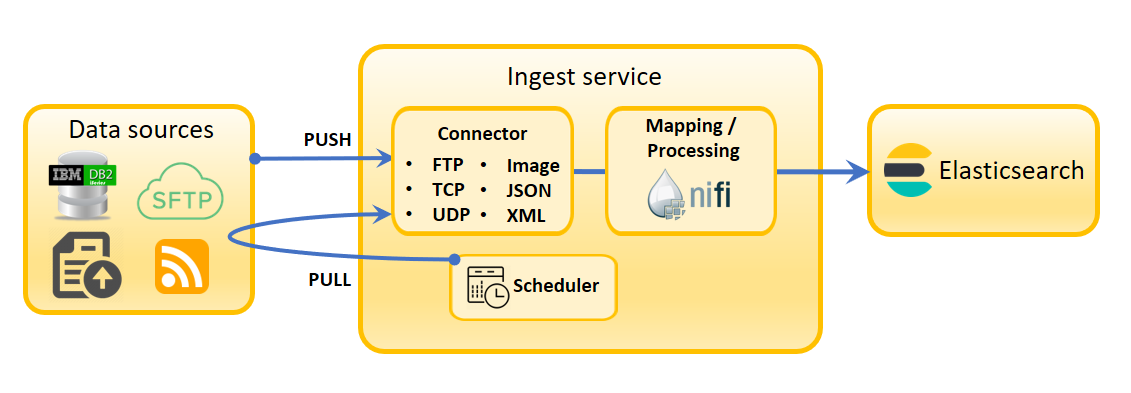
- Este microservicio gestiona operaciones de grabación. Realiza las operaciones de extracción, transformación y carga (ETL) esenciales en datos de negocio que hacen que estén disponibles para el índice de búsqueda. La lógica de negocio que hay detrás del ciclo de vida de indexación, que anteriormente se encontraba en el servidor de transacciones, ahora se gestiona aquí.
-
- Query Service
- El servicio de consulta crea las expresiones de búsqueda y, a continuación, entrega la expresión a Elasticsearch. También toma los resultados de la consulta y los convierte de nuevo a un formato que pueda ser utilizado por el escaparate. El escaparate no necesita saber que la respuesta fue generada por Elasticsearch en lugar de Solr.
- Apache NiFi
- NiFi es la canalización de indexación que utiliza el servicio de introducción. Utiliza conectores para incorporar datos en bruto y convertirlos en un formato que pueda ser utilizado por Elasticsearch. Puede utilizar los conectores NiFi predeterminados para los tipos de datos conocidos o definir los suyos para que NiFi pueda introducir tipos de datos personalizados. NiFi se ejecuta en su propio contenedor y es totalmente extensible.
- Elasticsearch
- El servicio de consulta y el perfil de búsqueda determinan la mejor manera de manejar la consulta de búsqueda. Elasticsearch utiliza su motor de alto rendimiento para ejecutar la búsqueda y, a continuación, la respuesta se vuelve a filtrar a través del perfil de búsqueda antes de que se vuelva a enviar al escaparate. El uso del perfil de búsqueda para filtrar la respuesta significa que el escaparate no necesita saber que está interactuando con Elasticsearch en lugar de Solr.
- Redis
- Redis se utiliza como bus de mensajes para distribuir sucesos de cambio así como sucesos de invalidación de caché. Para obtener más información, consulte el sitio del proyecto redis.
- ZooKeeper
- ZooKeeper se utiliza para almacenar las configuraciones predeterminadas y personalizadas, descriptores de conector junto con propiedades personalizadas y extensiones. Se inicia con el perfil de búsqueda y el perfil de incorporación ya está presente.
Puede utilizar los gráficos Helm preconfigurados que se incluyen con la versión 9.1 para desplegar una pila de búsqueda completa y preconfigurada. Al editar sus propios gráficos Helm, puede utilizar Kubernetes para desplegar un sistema adecuado a sus propias necesidades empresariales.