Ajuste del rendimiento del servicio de introducción
Puede ajustar el rendimiento de búsqueda en tiempo de introducción de datos ajustando los valores de NiFi o durante la ejecución cambiando las opciones de memoria para Elasticsearch.
Ajustar Apache NiFi
Para maximizar el rendimiento, NiFi divide los datos entrantes utilizando un enfoque de clúster de maestro cero. Los datos se dividen en fragmentos y cada nodo en el clúster realiza la misma operación en el fragmento que recibe. ZooKeeper elige un nodo como Coordinador de clúster y todos los demás nodos envían datos de monitorización. El coordinador es responsable de desconectar los nodos que no informan puntualmente, o de conectar nuevos nodos que prueban que tienen la misma configuración que los demás nodos del clúster.
| Valor | Descripción: | Valor predeterminado | Range/options |
|---|---|---|---|
| Memoria (valores de archivo Bootstrap.conf) | |||
| memoria JVM | Memoria de almacenamiento dinámico mínima y máxima. Tenga en cuenta que un almacenamiento dinámico muy grande puede ralentizar la recogida de basura. | 512mb | Se establece de 4 a 8 GB, por ejemplo:
|
| Recogida de basura: XX:+UseG1GC | Java 8 tiene problemas al utilizar la implementación de writeAheadProvenance recomendada introducida en Apache NIFi 1.2.0 (HDF 3.0.0). |
||
| Java 8 o posterior (valores de archivo nifi.properties) | |||
| XX:ReservedCodeCacheSize | NiFi almacena sus datos en disco mientras lo procesa. En condiciones de rendimiento alto, los valores predeterminados de CodeCache pueden resultar inadecuados. | Varía según la versión de Java; puede ser tan baja como 32 MB | 256Mb |
| XX:CodeCacheMinimumFreeSpace | Elimine el comentario de nifi.properties para utilizar. | 10mb | |
| XX:+UseCodeCacheFlushing | Establece el umbral para vaciar la memoria caché. | ||
| Almacenamiento de sistema de archivos para repositorios internos de NiFi | |||
| Archivo de flujo | |||
| Base de datos | |||
| Contenido | |||
| Procedencia | |||
| Ajuste (por nodo NiFi) | |||
| Hebras | Número de subprocesos para subprocesos controlados por temporizador. No utilice subprocesos activados por sucesos. | de 2 a 4 veces el número de núcleos en el host | |
Definir Elasticsearch
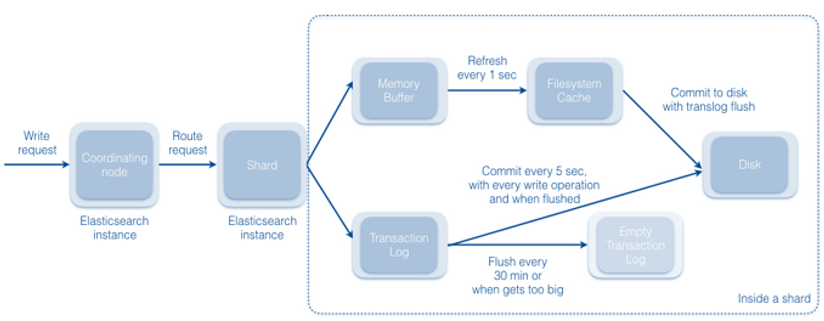
Elasticsearch utiliza el mismo método de clúster maestro cero que NiFi. El nodo de coordinación recibe solicitudes de escritura y asigna solicitudes de direccionamiento a otras instancias de clúster (fragmentos). De forma predeterminada, cada fragmento renueva su memoria caché de sistema de archivos una vez por segundo y se compromete cada cinco segundos. La fragmentación mantiene un registro de transacciones y vacía el registro cada treinta minutos.
En la fase de consulta del proceso de búsqueda, el nodo de coordinación toma búsquedas entrantes y las envía a todos los fragmentos. Cada fragmento realiza su propia búsqueda, de forma local. La fragmentación prioriza los resultados y devuelve información sobre los principales 50 documentos al nodo de coordinación. En la fase de captación, el nodo de coordinación determina los diez documentos principales de cada lista de fragmentos y solicita que esos documentos envíen cada fragmento.
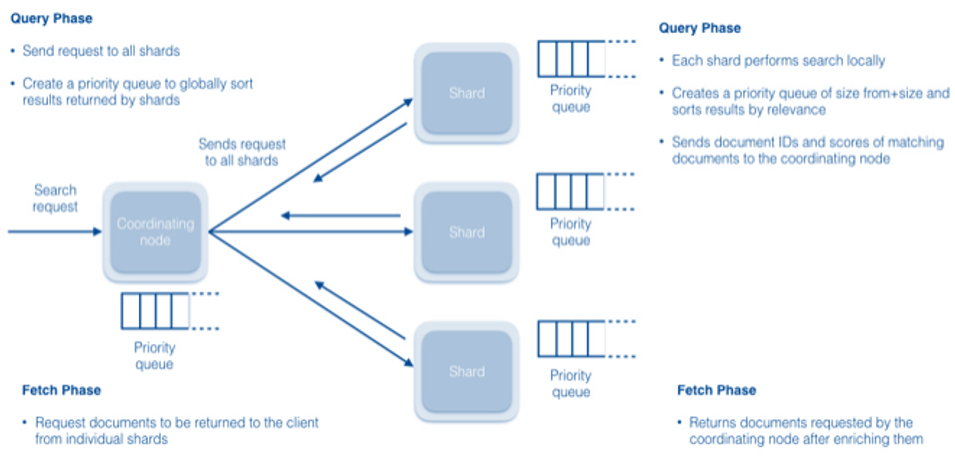
La fase de consulta suele tardar bastante más que la fase de captación, ya que, durante la consulta, los fragmentos tienen que correlacionar la búsqueda con una lista potencialmente larga de documentos y determinar una puntuación para cada una. Por el contrario, la captación puede completarse rápidamente porque el servidor de coordinación solicita un subconjunto de los documentos utilizando direcciones directas.
La forma principal de mejorar el rendimiento de Elasticsearch es aumentar el rango de renovación. Cuando lo haga, Elasticsearch creará un nuevo segmento de Lucene y lo fusionará más tarde, aumentando el recuento total de segmentos. Además, evite el intercambio si es posible. Establezca bootstrap.memory_lock=true para facilitarlo.
Ajuste los valores específicos siguientes para mejorar el entorno de trabajo de optimización de Elasticsearch.
| Valor | Descripción: | Valor predeterminado | Range/options |
|---|---|---|---|
| Memoria | |||
| Almacenamiento dinámico JVM | Memoria de almacenamiento dinámico mínima y máxima. |
|
|
| Recopilación de basura | XX:+UseG1GC | Utilice el primer recopilador de basura de Java 8 para tamaños de almacenamiento dinámico por debajo de 4 GB. | |
| Tamaño de almacenamiento intermedio de índice | 10 % de tamaño de almacenamiento dinámico. | ||
| Memoria caché del sistema de archivos |
|
El 50 % del tamaño de memoria de Elasticsearch | |
| Memoria caché de LRU | |||
| Memoria caché de consulta de nodo | Establecer con el parámetro indices.queries.cache.size | El 10 % de tamaño de almacenamiento dinámico | |
| Compartir memoria caché de consulta | Se utiliza para agregación | ||
| Memoria caché de datos de campo | Se establece con el parámetro de indices.fielddata.cache.size | Se limita al 30 % del tamaño de almacenamiento dinámico | |
| Valores generales | |||
| Agrupaciones de subprocesos | generic, index, get, bulk |
||