Servicio Ingest
El servicio de introducción es responsable de incorporar datos a HCL Commerce Search. Estos datos, que pueden estar en muchos formatos diferentes, se pasan a Apache NiFi, que lo prepara para que los utilice Elasticsearch. Para administrar el servicio de introducción, defina una especificación de datos para escribir descriptores de NiFi. Cada descriptor define el comportamiento de un conector determinado. Strung juntos, los conectores gestionan la canalización de datos y crea su índice.
Tuberías
Una barra vertical es un grupo de procesos NiFi que contiene un puerto de entrada NiFi, un flujo compuesto de una serie de procesadores NiFi y un puerto de salida. Los puertos de entrada y salida solo pueden recibir y enviar, pero los procesadores de NiFi a los que informan también pueden leer y escribir en el índice de búsqueda, u otros repositorios de datos permanentes. El grupo de procesos se almacena en un registro de NiFi, que es gestionado por versión.
Una canalización NiFi está formada por el conjunto total de canalizaciones NiFi responsables de poner en un tipo determinado de datos. Cada conducto conector predeterminado utiliza una plantilla de placa de caldera que contiene el siguiente patrón de introducción de datos ETL (extracción, transformación y carga):
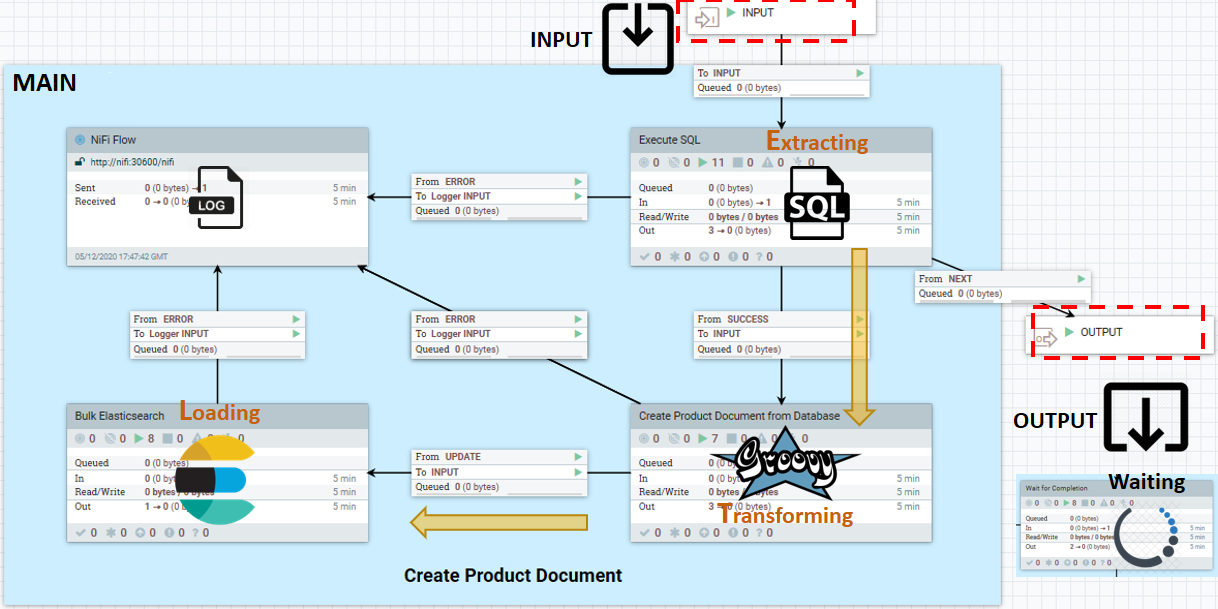
- INPUT
- El puerto que escucha las señales de los éxitos anteriores del procesador. Enviar solo señales de desencadenante a través de este y el puerto de salida. Los datos de negocio deben leerse, procesarse y grabarse en repositorios de datos externos desde dentro del conducto. Esta política impide las dependencias entre los conductos.
- MAIN
- Lógica de proceso de ETL. En este ejemplo, una extracción y transformación SQL utilizando un script Groovy. Sin embargo, el componente principal puede ser cualquier cosa, incluyendo
- Leer desde un almacén de datos externo
- Procesar cada entrada de datos que se lee
- Enviar uno o más documentos de datos procesados a Elasticsearch
- Esperar hasta que se agote todo el conjunto de datos de origen
- OUTPUT
- Puerto de salida utilizado para enviar un desencadenante con señal de éxito a las tuberías en sentido descendente.
WaitLink conecta un conducto con otro conducto o canalización. Detiene el flujo de datos hasta la finalización (satisfactoria, parcialmente satisfactoria o fallida) de la etapa actual.
No modifique estos grupos de procesos NiFi predeterminados o el código fuente incluido para referencia.
Se proporciona un servicio de registro con el servicio de introducción. Puede utilizar esto para realizar un seguimiento de los mensajes y los estados de las canalizaciones individuales, ya que los datos fluyen a través del sistema.
Conectores
Un conector es una canalización de flujo de datos o un conjunto de canalizaciones (grupos de procesos NiFi y sus conexiones) que realizan tareas de introducción y transformación de datos para preparar los datos para el índice de búsqueda. Los conectores proporcionan el contexto del ciclo de vida de los datos y negocios a las canalizaciones de los grupos de procesos conectados en NiFi. Algunos ejemplos del contexto del conector son el ciclo de vida de datos (producto, categoría, etc.); si el flujo de datos está pensado para el entorno real o de autoría, o si se utiliza en una reindexación completa o en tiempo casi real.
Hay conectores maestros que pueden compilar un índice (en el caso de auth.reindex y live.reindex). Los conectores se definen como un descriptor de conector creado mediante la API de servicio Ingest y almacenado en ZooKeeper.
 Note: A partir de la versión 9.1.10, el servicio Ingest sincroniza automáticamente NiFi con los descriptores de conector personalizados almacenados en Zookeeper. Los descriptores de conector predeterminados de versiones anteriores, previamente almacenados dentro de Zookeeper, ya no son necesarios, excepto los que están personalizados. Mantiene su propia copia dentro de Zookeeper. Para obtener más información, consulte Liberar cambios en el servicio Ingest.
Note: A partir de la versión 9.1.10, el servicio Ingest sincroniza automáticamente NiFi con los descriptores de conector personalizados almacenados en Zookeeper. Los descriptores de conector predeterminados de versiones anteriores, previamente almacenados dentro de Zookeeper, ya no son necesarios, excepto los que están personalizados. Mantiene su propia copia dentro de Zookeeper. Para obtener más información, consulte Liberar cambios en el servicio Ingest.http://ElasticSearchhostname:30600/nifi/Para obtener más información sobre el uso de NiFi, consulte la Guía del usuario de Apache NiFi.
Procesadores
Los procesadores NiFi son los bloques de construcción esenciales de las canalizaciones de flujo de datos. Los procesadores realizan tareas específicas dentro de la canalización, como escuchar los datos entrantes; extraer datos de fuentes externas; publicar datos en fuentes externas, y direccionar, transformar o extraer información de archivos de flujo. Los procesadores se agrupan en grupos de procesos y se conectan entre sí para formar canalizaciones de flujo de datos. Las canalizaciones de flujos de datos se agrupan a su vez y se les da un contexto mediante conectores. Un procesador NiFi especial, como por ejemplo un "procesador de enlaces" puede proporcionar un control de flujo en una canalización. Por ejemplo, un procesador de enlaces de uso frecuente es un "WaitLink" que pone en pausa el flujo de datos hasta que se ha completado la etapa actual, con un estado de success, partially successful o failed antes de autorizar la transmisión de datos al siguiente grupo de procesos en la canalización de flujo de datos.
Grupo de procesos
Un grupo de procesos NiFi es una red de procesadores NiFi donde cada procesador solo es responsable de procesar una tarea simple. Estos procesadores están conectados entre sí para gestionar una operación más complicada. Los grupos de procesos se conectan adicionalmente y se pueden anidar dentro de NiFi para formar canalizaciones de flujo de datos. Al igual que con los procesadores, los datos entran en un grupo de procesos con un estado y salen de él con otro estado. Tanto los procesadores como los grupos de procesos no tienen estado. Los grupos de procesos NiFi y sus conexiones (representadas en JSON como "flujos" almacenados y organizados en "contenedores") se versionan y mantienen en el registro NiFi.
Especificaciones de datos
Cada especificación de Apache NiFi define el tipo de datos y la estructura de un documento de entrada. Si desea crear una canalización NiFi, generalmente empieza con la especificación. NiFi da soporte de forma nativa a cientos de especificaciones diferentes. Si ya existe uno, es posible que pueda utilizarlo sin modificación. Si desea personalizar la canalización, NiFi proporciona un potente kit de herramientas, que incluye una API que le permite definir sus propias especificaciones.