Crear índices por fragmento utilizando varios JVM
Cuando la indexación tarda demasiado tiempo y el ajuste adicional no parece ser útil, podría ser que el servidor se acerque a sus limitaciones físicas. Para evitar una condición de este tipo, puede distribuir el índice en dos o más servidores de búsqueda, para que la carga de trabajo de indexación también se distribuya. Puede distribuir el índice entre varias máquinas virtuales Java.
Antes de empezar
Para poder realizar la fragmentación de índice con el servidor de búsqueda, configure primero el entorno de fragmento utilizando las directrices siguientes.
- Determine el número de fragmentos que utilizará, en función de la capacidad disponible del servidor. Al menos una capacidad del núcleo del CPU debe estar disponible para cada fragmento de índice independiente.
- Si está utilizando la réplica de índice, no configure ninguna de las fragmentaciones de índice para participar en la red de réplica de índice. Estos fragmentos solo se utilizan para la creación de índices. La versión final del índice debe estar en el servidor maestro, que se debe replicar en el repetidor y, a continuación, en los subordinados.
- Asigne suficiente memoria de almacenamiento dinámico para cada una de las fragmentaciones de índice. Consulte HCL Commerce Search : ajuste del rendimiento para obtener recomendaciones sobre cómo configurar el archivo de configuración de solrconfig.xml.
Por qué y cuándo se efectúa esta tarea
Para distribuir un índice, divídalo en particiones denominadas fragmentos. Los fragmentos pueden compartir el mismo contenedor de Docker de búsqueda o ejecutarse por separado en sus propios contenedores de búsqueda, en función del rendimiento del sistema. Si los contenedores de fragmento de búsqueda y el contenedor maestro de búsqueda no se encuentran en la misma máquina virtual o máquina física, es posible que necesite una tecnología de sistema de archivos distribuidos adicional, como por ejemplo remoteStorage, para ayudar a los contenedores de fragmento de búsqueda a compartir una carpeta de índice con el contenedor maestro.
Una vez que todos los fragmentos de índice se han rellenado satisfactoriamente, se pueden fusionar en un índice optimizado, que se utilizará con el escaparate para la ordenación, la faceta y el filtrado.
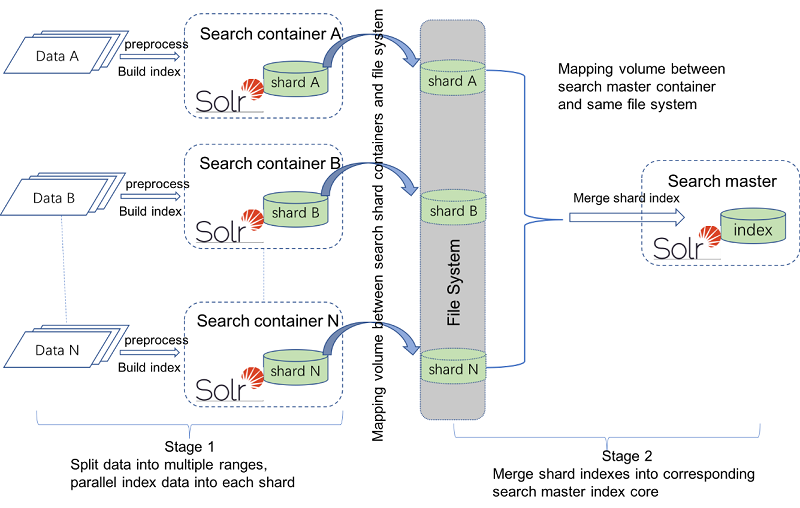
Hay dos etapas para indexar la fragmentación con varios JVM, ya que hay una sola JVM. En la primera etapa, los datos originales se dividen en varios rangos. Cada rango de datos se preprocesa y se indexa en los núcleos de índice de una fragmentación en paralelo. En la segunda etapa, todos los núcleos de índice de fragmentos se fusionan en el núcleo de índice correspondiente del maestro de búsqueda. Por ejemplo, los índices de fragmentos estructurados de CatalogEntry se fusionan en el índice estructurado de CatalogEntry maestro de búsqueda, y los índices fragmentados no estructurados se fusionan en el núcleo de índice no estructurado de maestro de búsqueda. Para varios JVM, el método estándar es crear cada índice de fragmento en un contenedor de servidor de búsqueda independiente. Si los recursos del sistema lo permiten, puede configurar un servidor de búsqueda para crear varios índices fragmentados.
Es necesario realizar algunos pasos adicionales para correlacionar volúmenes entre contenedores y un sistema de archivos externo. El contenedor maestro de búsqueda necesita esta correlación para que pueda acceder a todas las carpetas de índice de fragmento.
Una vez que haya configurado el entorno de fragmentación, podrá realizar la indexación en cada fragmento utilizando el programa de utilidad di-parallel-process. El diagrama siguiente muestra las dos etapas para la fragmentación en varios contenedores de Docker de búsqueda.
Procedimiento
- Copie docker-compose.yml en su entorno de desarrollo. Cambie el nombre por docker-compose-shardingMultiJVMs.yml.
-
Ejecute el mandato siguiente para configurar el entorno:
Si no ha cambiado los valores predeterminados en el archivo, este mandato crea tres servidores de fragmentación de búsqueda, un servidor maestro de búsqueda, un servidor de transacciones, un contenedor DB2 y un contenedor de programa de utilidad. Tres servidores de fragmento de búsqueda se correlacionan con diferentes puertos para cada contenedor. Los puertos sondocker-compose -f docker-compose-shardingMultiJVMs.yml up -dhttppuerto 3737 yhttpspuerto 3738.Para los servidores de fragmentación de búsqueda, modele la configuración en el ejemplo siguiente:shard_a: image: search-app:latest hostname: search_shard_a environment: - WORKAREA=/shard_a - LICENSE=accept - TZ=Asia/Shanghai ports: - 3747:3737 - 3748:3738 volumes: - /shard_a depends_on: db: condition: service_healthy healthcheck: test: ["CMD", "curl", "-f", "-H", "Authorization: Basic ","http://localhost:3737/search/admin/resources/health/status?type=container"] interval: 20s timeout: 180s retries: 5Nota: Defina un nombre de host distinto, puertos externos y carpetas externas para distintos contenedores de fragmento de búsqueda.Para el contenedor maestro de búsqueda:master: image: search-app:latest hostname: search_master environment: - SOLR_MASTER=true - WORKAREA=/search - LICENSE=accept - TZ=Asia/Shanghai ports: - 3737:3737 - 3738:3738 volumes_from: - shard_a:ro - shard_b:ro - shard_c:ro networks: default: aliases: - search depends_on: db: condition: service_healthy healthcheck: test: ["CMD", "curl", "-f", "-H", "Authorization: Basic ","http://localhost:3737/search/admin/resources/health/status?type=container"] interval: 20s timeout: 180s retries: 5Nota: La correlación de volúmenes externos para el nodo maestro de búsqueda está configurado para la carpeta de índice de fragmento, para permitir el acceso del nodo maestro a todos los índices fragmentados. -
En el contenedor Docker del servidor del programa de utilidad, modifique
/opt/WebSphere/CommerceServer90/properties/parallelprocess/di-parallel-process.propertiespara que coincida con su entorno. Puede utilizar los ejemplos siguientes como guía.Configure el nombre de host y el puerto para distintos servidores fragmentados como se indica a continuación.
El nombre del servidor de fragmento debe ser el mismo que el nombre de host/alias con el archivo de Docker Compose. b) Configure el directorio de núcleo de índice de fragmento como se indica a continuación:Shard.A.common.index-server-name=shard_a Shard.A.common.index-server-port=3738 … Shard.B.common.index-server-name=shard_b Shard.B.common.index-server-port=3738Shard.A.en_US.unstructured-index-core-dir=/shard_a/index/solr/MC_10001/en_US/Unstructured_A/ Shard.A.en_US.structured-index-core-dir=/shard_a/index/solr/MC_10001/en_US/CatalogEntry_A/ … Shard.B.en_US.unstructured-index-core-dir=/shard_b/index/solr/MC_10001/en_US/Unstructured_B/ Shard.B.en_US.structured-index-core-dir=/shard_b/index/solr/MC_10001/en_US/CatalogEntry_B/ Note: the directory should be absolute path inside each shard container.Puede automatizar el proceso de configuración de fragmentación. Esto es útil si, por ejemplo, espera crear un gran número de fragmentos. El proceso de fragmentación automática configurará automáticamente propiedades como, por ejemplo, preprocessing-start-range-value, preprocessing-end-range-value, index-core-name e index-core-dir.
Para obtener información sobre cómo configurar la fragmentación automática, consulte Archivo de propiedades de entrada de fragmentación.
-
Vaya al directorio
/opt/WebSphere/CommerceServer90/bin. -
Ejecute el mandato siguiente para realizar la fragmentación en varios JVM.
Para obtener más información, consulte Ejecución de programas de utilidad desde Utility server Docker container../di-parallel-process.sh /opt/WebSphere/CommerceServer90/properties/parallelprocess/di-parallel-process.properties