Indexación de contenido de sitio con la HCL Commerce Search
HCL Commerce WebSphere Commerce contiene contenido sin gestionar como por ejemplo contenido de sitio que debe rastrearse mediante el rastreador de contenido de sitio. El contenido sin gestionar pensado para la producción debe publicarse por separado, ya que no forma parte de la propagación de transición. Una vez que el contenido estático se copia en la ubicación adecuada, se precisa de una reindexación de contenido de sitio manual del sistema de producción contra el repetidor.
Rastreador del contenido de sitio
El rastreador de contenido de sitio rastrea HTML y otros archivos de sitio de tiendas de inicio de HCL Commerce para ayudar a rellenar el índice de búsqueda de contenido de sitio.
El rastreador de contenido de sitio captura el contenido de sitio, lo almacena en caché en un directorio local y coloca las entradas en el archivo manifest.txt. A continuación, correlaciona las ubicaciones físicas con las URL correspondientes. El indexador utiliza el archivo de manifiesto para recuperar las ubicaciones de archivo temporal físicas, crea los índices y, una vez se han convertido en señales, asocia las URL de archivo con el registro de índice.
En la tabla siguiente se resalta el flujo de trabajo del rastreador del contenido de sitio:
| Acción de rastreador de contenido de sitio | Flujo de trabajo de rastreador de contenido de sitio |
|---|---|
| El rastreador de contenido de sitio se inicia | El rastreador de contenido de sitio:
|
| El rastreador de contenido de sitio crea la estructura de directorios | El rastreador de contenido de sitio:
El diagrama siguiente muestra una visión general de alto nivel de la estructura del directorio del rastreador de contenido de sitio: 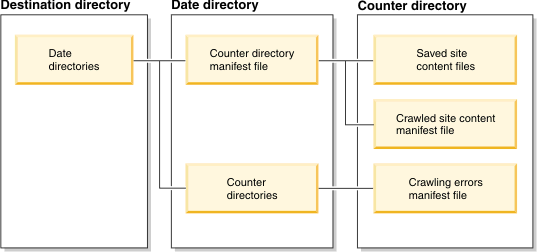 |
| El rastreador de contenido de sitio rastrea el contenido de sitio | El rastreador de contenido de sitio:
|
| El rastreador de contenido de sitio finaliza | Si el rastreador de contenido de sitio tiene éxito, realizará lo siguiente:
|
Rastreador de contenido de sitio e integración de indexador
El indexador actúa como servicio para el rastreador de contenido de sitio. Una vez que se completa cada rastreo, el rastreador de contenido de sitio invoca directamente una solicitud al servidor de HCL Commerce Search con la URL específico. A continuación, el proceso de indexación se inicia de forma asíncrona. la URL típico se parece al URL de muestra siguiente:
- http://localhost:3737/solr/MC_$catalogId_CatalogEntry_Unstructured_$localename/webdataimport?command=full-import&storeId=$storeId