
Detalles del procesamiento de NLP en las respuestas de la API
Detalles del procesamiento de NLP
Los detalles del análisis de NLP (Natural Language Processing) de la solicitud de búsqueda actual están disponibles en la sección de metadatos de la respuesta de la API de búsqueda de términos. Estos metadatos se generan después de que se haya aplicado cualquier lógica de eliminación de términos de búsqueda aplicable a la consulta. Junto con estos detalles, en los metadatos se proporcionará también la consulta de Elasticsearch final. Estos detalles se devuelven al utilizar el parámetro de solicitud esQueryWithGrouping. Este parámetro devuelve la consulta de agrupación si la agrupación está habilitada. esQueryWithoutGrouping devolverá la consulta sin la agrupación en caso de que la agrupación esté inhabilitada.
- Cuál era el término de búsqueda
- Detalles sobre la corrección ortográfica
- Términos excluidos
- Ampliación de sinónimos o sustituciones realizadas para cualquier palabra clave
- Filtros de precios
- Parte de codificación de voz / Reconocimiento de entidades nombradas
- Filtro de color
El ejemplo siguiente presupone que ha configurado los sinónimos y las sustituciones como se indica a continuación.
{ "chair => sofa": "", "sofa, couch": "" } Imagine que se realiza una búsqueda mediante la cadena sille roja para casa por debajo de 500 $, donde la palabra clave chair está mal escrita (debería ser cheir). La lista nlpParsing incluye dos objetos JSON, que muestran que en la primera iteración la consulta ha devuelto cero resultados. En la siguiente iteración, el servicio de consulta aplica la lógica de descarte de términos de búsqueda basándose en la prioridad de descarte definida en el perfil NLP. El segundo objeto JSON de la lista de análisis contiene el resultado del análisis con esa lógica aplicada. Si esto falla, el proceso continúa hasta que se devuelve un resultado o bien no se devuelve ninguno. En este caso, cheir coincide con chair. La lista nlpParsing se rellena en cada iteración. Durante el análisis de NLP, a cada token se le asigna una clasificación de correlaciones. Cuando se aplica la asociación de términos de búsqueda (STA), chair se sustituye por sofa y, a continuación, sofa se amplía con sofa OR couch, under $50 se analiza como un filtro de precios y [LTE:50] se considera como menor o igual a 50 $.
El contenido completo de nlpParsing se muestra en la siguiente captura de pantalla.
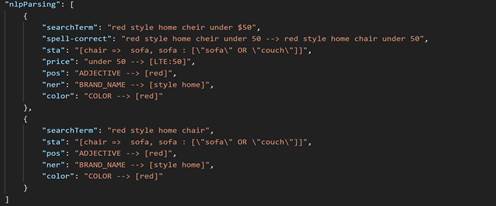
chair se clasificará como CATEGORY.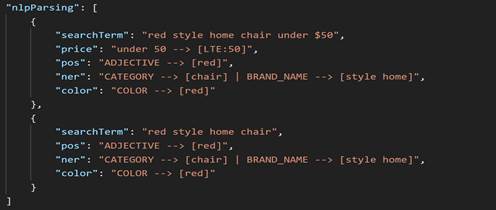
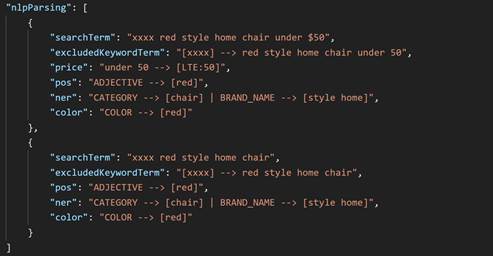
xxxx. Este parámetro pasa a ser un término excluido.
En todas las capturas de pantalla anteriores, el texto rojo se correlaciona con la sección ADJECTIVE (pos), así como con la sección COLOR. En este caso, el color se analiza primero como un adjetivo. En la fase posterior del procesamiento de NLP, se escanean todos los adjetivos de la lista de adjetivos y se extraen los nombres de los colores, enviándose al filtro de color.
Si desea disponer de la consulta de Elasticsearch generada en la respuesta para solucionar problemas, introduzca los parámetros esQueryWithGrouping= o trueesQueryWithoutGrouping= en el término solicitud de la API de búsqueda. La consulta se devolverá en la sección de metadatos de la respuesta de la API. Esta consulta se genera basándose en la última iteración del ciclo de análisis de NLP.true

Mejora de los términos de búsqueda en Basic NLP
Al mejorar los términos de búsqueda de tipo NOUN, CATEGORY y BRAND_NAME, se puede incluir información de mejora en la respuesta de búsqueda dentro del nodo metaData.nlpParsing. Este factor de mejora se puede personalizar.
pos y ner se añaden a ambos términos de búsqueda con un factor de mejora de 100,0. La información solo complementa la respuesta de búsqueda y el proceso general de mejora permanece igual. Antes de esta mejora, se define como:{ "metaData": { "price": "1", "nlpParsing": [ { "searchTerm": "Stonehenge gifts" } ] } ... }{ "metaData": { "price": "1", "nlpParsing": [ { "searchTerm": "Stonehenge gifts", "pos": "NOUN --> [bath~bathing] (boosted by 100.0)", "ner": "BRAND_NAME --> [stonehenge] (boosted by 100.0)" } ] } ... }