Indexación y manejo de contenido no estructurado
La información almacenada en el contenido no estructurado puede organizarse y almacenarse desde diferentes ubicaciones, incluida la base de datos de HCL Commerce, en sistemas de archivos de servidores y en Internet. Por lo tanto, el proceso de indexación de contenido no estructurado utiliza un híbrido de orígenes de datos para crear información de indexación utilizando la infraestructura de indexación de HCL Commerce Search existente.
Organización y recuperación de contenido no estructurado
El contenido no estructurado incluye información de entrada de catálogos y sus archivos adjuntos asociados. Los archivos adjuntos de HCL Commerce se utilizan para encontrar el archivo adjunto relacionado con la entrada de catálogo para un idioma específico. Puesto que no todos los archivos adjuntos contienen un language_id, el comportamiento por defecto fusiona los resultados language_id nulos con los resultados language_id específicos.
Donde language_id se define desde la tabla de HCL Commerce, -1 representa el inglés de Estados Unidos y la lista de catentry_id es el parámetro de entrada. El resultado de la búsqueda contiene elcatentry_id, la vía de acceso del archivo adjunto, el uso del archivo adjunto y la descripción del archivo adjunto. La lista de tipo de uso de archivo adjunto predeterminado es DOCUMENTS, USERMANUAL, WARRANTY y OTHER. Para la personalización estos tipos de uso son configurables para satisfacer los requisitos de búsqueda específicos.
<script><![CDATA[
function isWriteToFile(row) {
var ruleName = row.get('RULENAME');
var writeToFile = "false";
if(ruleName != null){
if(ruleName == 'DOCUMENTS' || ruleName == 'USERMANUAL' || ruleName == 'WARRANTY'
|| ruleName == 'OTHER'){
writeToFile = "true";
}
}
row.put('writeToFile', writeToFile);
return row;
}
]]></script>
Data Import Handler y la indexación de contenido no estructurado
Data Import Handler maneja el proceso de indexación de contenido no estructurado utilizando un híbrido de orígenes de datos para crear información de indexación utilizando la infraestructura de indexación de HCL Commerce Search existente. TikaEntityProcessor se utiliza para soportar los datos híbridos.
El diagrama siguiente ilustra el rol de TikaEntityProcessor en la gestión de contenido no estructurado en HCL Commerce:
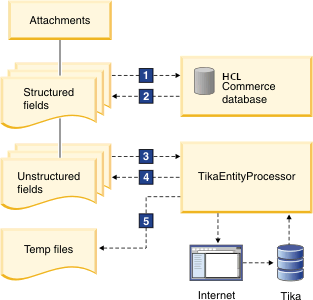
- 1, 2
- Las entradas de catálogo se indexan desde la base de datos de HCL Commerce como contenido estructurado.
- 3, 4, 5
- La lógica reutiliza las características de la infraestructura DIH como los bucles a través filas de conjuntos de resultados SQL y pasando parámetros en un formato parecido al
${Attachment.CATENTRY_ID}. TikaEntityProcessor utiliza el parámetrosourceUrlcon los parámetroscommercebasepara captar contenido de Internet, analiza el contenido binario y devuelve los resultados al índice de contenido no estructurado. A continuación, TikaEntityProcessor adjunta el contenido de texto al archivo catentryId.txt, ubicado en la carpeta temporal en la carpeta raíz de núcleo no estructurado.
Los parámetros commercebase pueden personalizarse para cumplir con los requisitos de búsqueda específicos. Los parámetros tikacontentfield y tikaprefix se correlacionan directamente con los parámetros de celda Solr fmap.content y uprefix. Para obtener más información, consulte ExtractingRequestHandler.
La llamada RESTful buildindex se utiliza para indexar el contenido no estructurado.Creación del índice de HCL Commerce Search
Actualizaciones de proceso de Data Import Handler de contenido estructurado para contenido no estructurado de índice
Es posible que se deba hacer una búsqueda los objetos estructurados según el contenido del contenido no estructurado relacionado. Por lo tanto, el contenido estructurado también necesita el contenido no estructurado. Es decir, el proceso de indexación DIH de contenido estructurado predeterminado también debe leer el contenido de contenido no estructurado. El PlainTextEntityProcessor se utiliza para leer el contenido de los archivos temporales e indexarlos en el campo definido. Utiliza los archivos temporales que TikaEntityProcessor crea durante el proceso DIH de contenido no estructurado.
El origen de datos basePath del archivo de configuración DIH define la ubicación de la carpeta temporal. En esta configuración, onError="continue" se establece de modo que si el archivo no existe, o hay otros errores, el proceso DIH sigue ejecutándose e ignora el error. El nombre del campo unstructure es un valor fijo establecido como plainText y no puede cambiarse.