Indexación con propagación de transición
Al indexar con la propagación de transición, los usuarios de empresa aplican cambios en un área de transición, que posteriormente se propaga al entorno de producción por los administradores de TI. Se utiliza un repetidor de índice para capturar el contenido de índice desplegado más reciente, y que también sirve como copia de seguridad.
En caso de aplicar un cambio de emergencia, se puede utilizar el repetidor para la reindexación en lugar de hacerlo directamente en los subordinados de búsqueda que están en producción. Esto puede evitar cualquier tiempo de inactividad potencial debido a la corrupción durante la reindexación. Es decir, los subordinados de búsqueda que están en producción se tratan siempre como servidores subordinados, con la reindexación siempre en el repetidor. Una vez que la reindexación se ha realizado correctamente, los cambios delta se replican en los nodos subordinados de los subordinados de búsqueda que están en producción. Esta réplica de índice parece perfecta para los administradores, ya que después de que la réplica se haya completado en el sistema de producción, la nueva versión del índice de búsqueda se activa automáticamente.
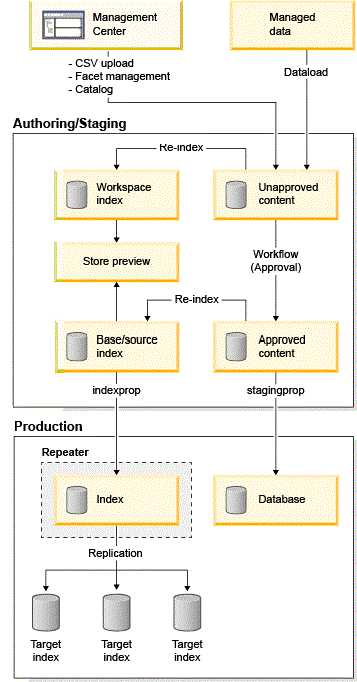
Flujo de índice de búsqueda con propagación de transición y el índice de espacio de trabajo
Cronología de sucesos
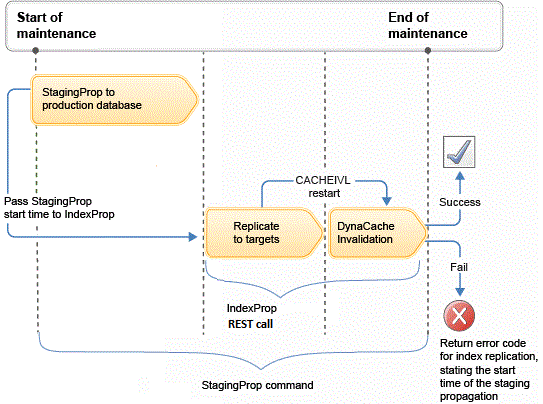
Donde:
- Se pasa una hora de inicio como un parámetro a la API REST indexprop en el momento en que un administrador de TI emite el mandato.indexprop Para más información sobre esta API, consulte Propagación del índice de búsqueda.
- Esta hora de inicio define el periodo en que se inicia la invalidación de memoria caché. Normalmente, éste es el inicio de la operación de propagación de transición.
- La API REST indexprop se puede utilizar para supervisar el progreso de la réplica de índice en todos los servidores subordinados de búsqueda en producción.
- Después de todas las réplicas de índice se hayan completado satisfactoriamente, se llama a la API REST indexprop para emitir una instrucción de invalidación de memoria caché insertando una entrada de tipo de reinicio en la tabla CACHEIVL, utilizando el parámetro de hora de inicio proporcionado como la hora en que empezar a realizar la invalidación de memoria caché.
- Los cambios de catálogo se realizan en HCL Commerce con el Centro de gestión o el programa de utilidad de carga de datos en un entorno de transición. Los usuarios de empresa prueban y previsualizan todos los cambios en este entorno de preproducción antes de que se publiquen los cambios en los entornos de producción. En este escenario, hay un índice de búsqueda dedicado para el entorno de transición y el procedimiento de actualización delta para sincronizar los cambios de catálogo es el mismo que en un entorno que no sea de transición.
- El índice de búsqueda de espacio de trabajo se utiliza para que los usuarios de empresa obtengan una vista previa de los cambios que se realizan en el Centro de gestión, por ejemplo, la subida de archivos CSV u otros cambios de catálogo.
- Cuando los usuarios de empresa están satisfechos con los cambios, los datos se liberan y se publican en producción utilizando la propagación de transición (stagingprop). El programa de utilidad es utilizado por los administradores de TI para coordinar las tareas siguientes al publicar en producción:
- stagingprop
- Se utiliza para datos gestionados, tales como los de catálogo y configuración.
- La API REST indexprop se utiliza para propagar el índice HCL Commerce Search:
- La llamada RESTful indexprop la utilizan los administradores de TI para iniciar la réplica del índice de búsqueda desde el entorno de transición en el repetidor y realizar la invalidación de memoria caché para HCL Commerce Search en producción. Para obtener más información, consulte Propagar el índice de HCL Commerce Search con el repetidor.
Para obtener más información sobre cómo actualizar el archivo de configuración de réplica (replication.csv), descargue y extraiga el archivador siguiente que contiene archivos CSV de ejemplo sdsearch_replication_samples.zip.Nota: Cuando se ejecuta el trabajo de planificador UpdateSearchIndex:- El trabajo de planificador UpdateSearchIndex no llama a la API indexprop de forma predeterminada. Por lo tanto, no es necesario copiar replication.csv en una ubicación fuera del directorio de inicio de Solr.
- El archivo replication.csv debe copiarse en una ubicación fuera del directorio de inicio de Solr. Esto evita que tenga lugar automáticamente la réplica cada vez que se ejecuta el trabajo de planificador UpdateSearchIndex. Por ejemplo, copie replication.csv en el directorio WC_installdir/instances/instance_name/search. A continuación, pase el valor -solrHome al llamar a la API REST indexprop.
- El repetidor de índice de búsqueda se utiliza como un maestro y un subordinado para la réplica de búsqueda.
Se utiliza como un subordinado cuando se replica con el índice de búsqueda de transición, donde el índice de búsqueda de transición es el maestro y el repetidor es el subordinado que actúa como copia de seguridad del índice de búsqueda para producción. Después de que la primera réplica se ha completado desde la transición, el repetidor comunica los cambios a sus nodos subordinados que están en producción.
Entonces el repetidor se convierte en el maestro, donde todos los nodos de los subordinados de búsqueda se configuran para sondear los cambios del repetidor en un rango de tiempo fijo preconfigurado regular. Este rango de tiempo está definido en el archivo solrconfig.xml bajo
replication.La réplica entre el repetidor y todos los subordinados de búsqueda en producción se pueden automatizar, ya que los datos indexados en el repetidor siempre coinciden con los datos indexados en producción. El repetidor de índice de búsqueda debe ser un subordinado del servidor de búsqueda de transición y el maestro para el servidor de búsqueda de producción.
Importante: El repetidor debe residir en Producción, ya que depende de la base de datos de producción para realizar actualizaciones de emergencia. - Deben tenerse en cuenta las siguientes consideraciones cuando los archivos de elementos y los datos de catálogo se publiquen en la producción:
- La próxima vez que se va a producir la réplica entre el índice de búsqueda de producción y el repetidor.
- La cantidad aproximada de tiempo que la réplica de índice puede tardar en completarse.
- Se debe realizar la invalidación de memoria caché para el escaparate antes de que los cambios actualizados sean visibles en la producción.
- Se puede ejecutar una invalidación memoria caché automatizada utilizando la llamada RESTful indexprop.
Cuando se utiliza la opción de tiempo de reinicio indexprop para realizar la reinvalidación, después de que todas las réplicas de índice se hayan completado satisfactoriamente, el programa de utilidad indexprop emite una instrucción de invalidación de memoria caché insertando una entrada de tipo reinicio (restart) en la tabla CACHEIVL, utilizando el parámetro de hora de inicio proporcionado como la hora para empezar a realizar la invalidación de memoria caché. Esto permite que el mandato de planificador DynaCacheInvalidation vuelva a realizar la misma invalidación, empezando por el parámetro de hora de inicio proporcionado. Esto impide la invalidación precoz, lo que hace que se vuelva a almacenar en memoria caché contenido obsoleto ante de que estén disponibles los últimos cambios de índice. Estas entradas de invalidación en la tabla CACHEIVL pueden ser los ID de dependencia utilizados para la invalidación de memoria caché de fragmentos JSP o la invalidación de memoria caché de objeto de datos.
- Se puede ejecutar una invalidación memoria caché automatizada utilizando la llamada RESTful indexprop.