
Métricas clave de supervisión
El panel de control del tiempo de consulta y el panel de control de utilización de la CPU son las dos métricas de supervisión primarias que le permitirán supervisar el clúster de Elasticsearch (ES) e identificar los cambios a lo largo del tiempo de forma dinámica.
Las siguientes dos métricas de supervisión fundamentales le permiten supervisar de forma dinámica el clúster de Elasticsearch, así como detectar variaciones a lo largo del tiempo:
- Panel de control del tiempo de consulta
- Panel de utilización de la CPU
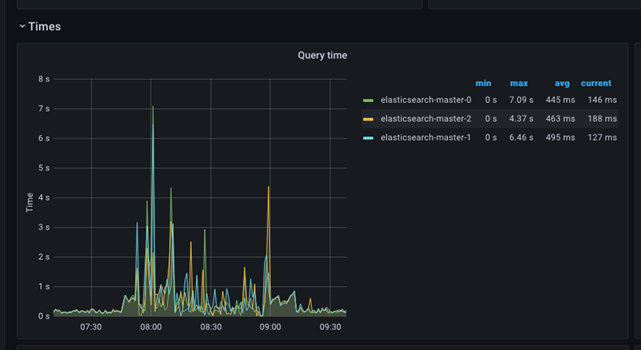
Las siguientes capturas de pantalla muestran el tiempo de consulta y el tiempo de procesamiento de un período determinado. Los valores mínimo, máximo y promedio se muestran en la tabla lateral, mientras que el gráfico presenta los valores máximos.
El gráfico es fácil de entender y se puede utilizar para identificar problemas rápidamente. Cualquier salto repentino en los valores máximos del tiempo de consulta indicaría que hay un problema grave en el clúster; en ese caso, será obligatorio investigar el problema. El gráfico muestra una situación en la que el tiempo de procesamiento de la consulta se ha visto afectado durante un período más prolongado, y dicho período debe correlacionarse con las demás pantallas para determinar el origen del problema.
También es posible que haya picos repentinos y que luego regrese a la normalidad. Estos picos suelen deberse a sucesos externos que afectan al tiempo de procesamiento de la consulta.
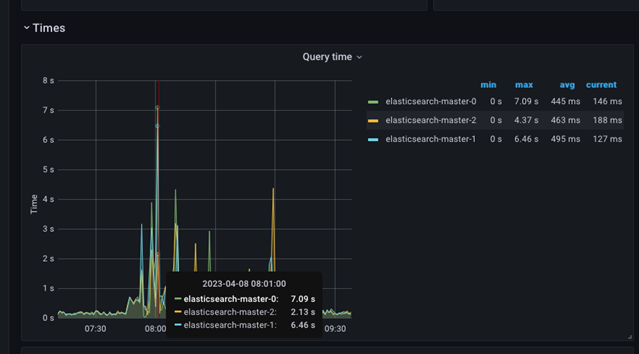
Para ver los valores reales de ese intervalo de tiempo, mueva el cursor del ratón sobre la imagen.
- Utilización de la CPU
- Este panel es fundamental, ya que puede alertarle sobre un comportamiento inusual o una dificultad del sistema para hacer frente a la carga de trabajo actual.
Consumo de recursos
El grupo de consumo de recursos muestra información detallada sobre las operaciones del clúster de Elasticsearch y la disponibilidad de recursos. Debe entenderse bien cómo mantener estable el estado de la operación, y cualquier desviación del estado que provoque que no sea estable debería presentar una alerta de amenazas potenciales o inestabilidad en el sistema que deberá investigarse.
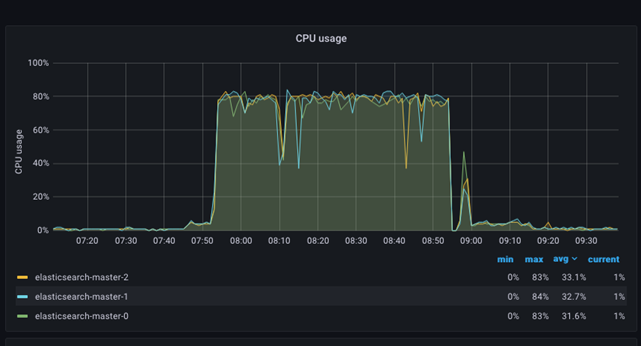
Utilización de la CPU
El gráfico de edad de la CPU es relativamente simple. El gráfico presenta cada nodo de ES como un color separado y, al mismo tiempo, muestra una tabla con los valores mínimo, máximo y promedio de cada nodo en el clúster de ES. Es sencillo detectar situaciones en las que la CPU es muy alta (hambruna) o baja (contención y ralentización en la tasa de procesamiento). La siguiente imagen muestra cómo la utilización de la CPU salta al 80 %+ mientras el tráfico y la indexación se llevan a cabo en el sitio.
Red
Los gráficos de recursos de red son relativamente simples, pero proporcionarán datos adicionales y una resolución fácil si un exceso de volumen de solicitudes está afectando a las operaciones.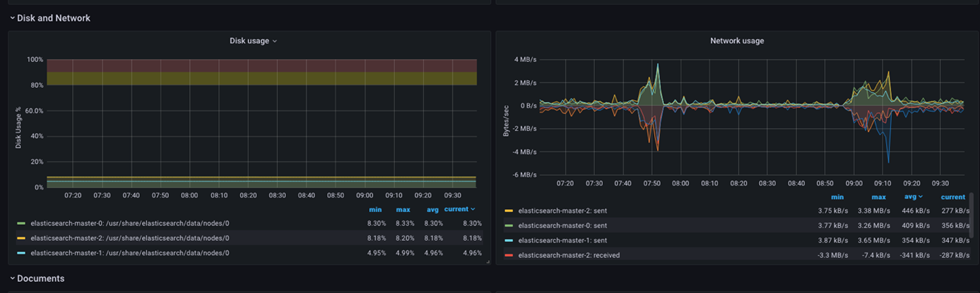
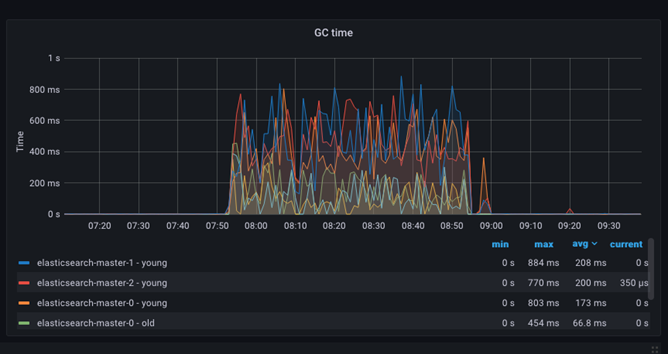
Operaciones de recogida de basura (GC): momento de la GC
Se puede realizar un seguimiento del almacenamiento dinámico JVM y de la programación de la recogida de basura (GC) mediante el panel de hora de la GC. Este panel muestra la cantidad de tiempo utilizada para borrar el almacenamiento dinámico JVM de los objetos bloqueados para hacer espacio para nuevas asignaciones. La operación representa normalmente una sobrecarga del 10 %, y su efecto es insignificante.
Utilización de la memoria JVM
El panel de control de edad de la memoria puede realizar un seguimiento de la asignación de la memoria y de la expansión del espacio de almacenamiento dinámico en la JVM (Java Virtual Machine). En el siguiente gráfico siguiente se muestra un ejemplo:
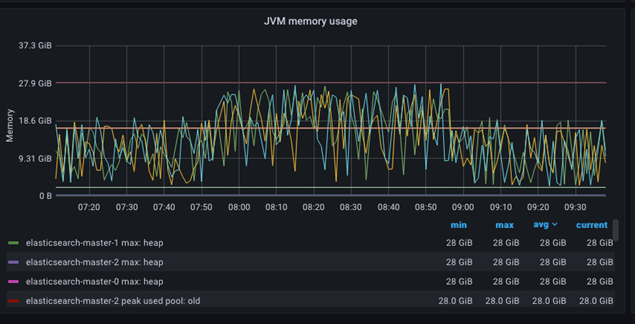
El espacio de almacenamiento dinámico total está documentado en exceso y puede resultar confuso. Se notifican varias métricas, pero debido a la configuración del almacenamiento dinámico de ES (min=max), solo se visualiza el almacenamiento dinámico Elasticsearch-master-NNN utilizado.
La expectativa general es que las métricas de almacenamiento dinámico utilizadas estarán por debajo de las métricas máximas de almacenamiento dinámico, mientras que el gráfico de utilización de la CPU representará el consumo de recursos normal y constante. El gráfico de las horas de la GC debe mostrar una sobrecarga baja y un tiempo empleado en realizar la recogida de basura corto.
Sin embargo, si la métrica de almacenamiento dinámico utilizada es máxima de forma frecuente y se muestra cercana a la métrica de almacenamiento dinámico máximo, la operación seguirá siendo estable. Esto indica que el almacenamiento dinámico global en ES no es suficiente y que debe aumentarse.