Optimización de la generación de índices y el flujo general
Las optimizaciones reciben construcciones de índice completas y para ajustar los parámetros. No se describen las posibles mejoras que se pueden implementar para las actualizaciones de índices en tiempo casi real (NRT).
Proceso de creación de índice
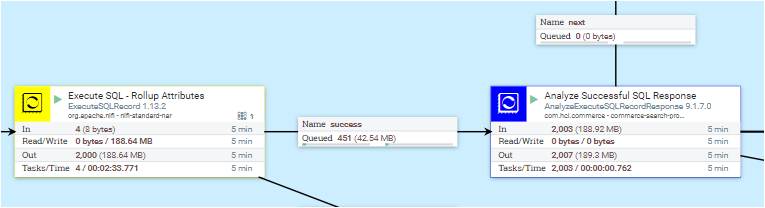
Una creación de índice completa consta de tres pasos principales: recuperar datos, procesar datos y subir datos. Existen varios conectores predefinidos, que constan de varios grupos de procesos para distintos propósitos. Normalmente, cada grupo de procesos contendrá subgrupos de procesos para manejar las etapas de recuperación, procesamiento y carga de datos que están asociadas con el proceso de compilación.
- Recuperación de grupo de datos: Captar datos de la base de datos o Elasticsearch.
- Procesando grupo de datos: Basándose en los datos captados, cree, actualice y/o copie los documentos de índice.
- Subirgrupo de datos: Suba el documento de índice a Elasticsearch. A partir de la versión de HCL Commerce 9.1.3.0, cada índice tiene un grupo asociado.
Ajuste
Generalmente, la configuración predeterminada funcionará para este proceso, pero puede llevar mucho tiempo finalizar el proceso de indexación para un conjunto de datos grande. Dependiendo del tamaño del conjunto de datos y la configuración del hardware (memoria, CPU, disco y red), se pueden realizar mejoras en los subgrupos y grupos de procesos para que los flujos de procesos sean más rápidos y eficientes dentro de los subgrupos y entre los subgrupos conectados.
Recuperación de grupo de datos
En este grupo, hay tres orígenes distintos de los que se pueden recuperar los datos.
- Captado de una base de datos con desplazamiento SQL;
- Captado de una base de datos con SQL sin desplazamiento;
- Captado de Elasticsearch con desplazamiento
- Captar datos de una base de datos con desplazamiento SQL
-
 Ingrese al grupo SCROLL SQL, luego haga clic con el botón derecho en el lienzo base y seleccione las variables.
Ingrese al grupo SCROLL SQL, luego haga clic con el botón derecho en el lienzo base y seleccione las variables.- scroll.page.size es el número de filas captadas de la base de datos por el SQL.
- scroll.bucket.size es el número de filas de los datos captados en cada grupo para su procesamiento. El archivo bucket.size determinará el tamaño de los archivos de flujo (y el número de documentos contenidos en cada archivo).
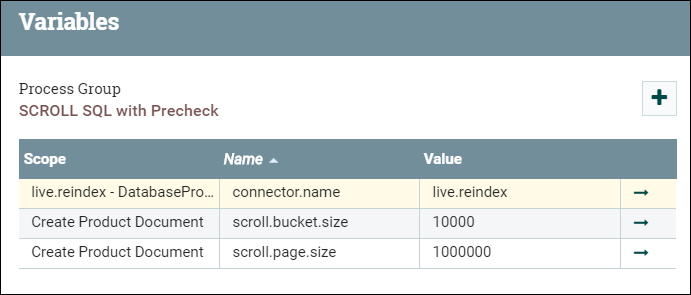
Cambie los valores de scroll.bucket.size y scroll.page.size basándose en las consideraciones siguientes:
- • En función del tamaño del catálogo, el SQL puede tardar mucho tiempo en obtener datos de respuesta a NiFi. El propósito del SQL de desplazamiento es limitar el tamaño de los datos que se pueden procesar en NiFi a la vez, para evitar errores de memoria en catálogos grandes.
- • La configuración de desplazamiento es óptima cuando el tiempo que se tarda en procesar los datos coincide con la cantidad de tiempo que tarda el siguiente desplazamiento de SQL en recibir sus datos. Con esta optimización, se minimiza el proceso innecesario o el retardo de E/S.
- • La salida de un subgrupo se efectúa a la vez que el siguiente subgrupo de proceso conectado. Este proceso se debe auditar para asegurarse de que no haya cuellos de botella que puedan afectar a la eficiencia del proceso global.
- Captar datos de la base de datos con SQL sin desplazamiento
-
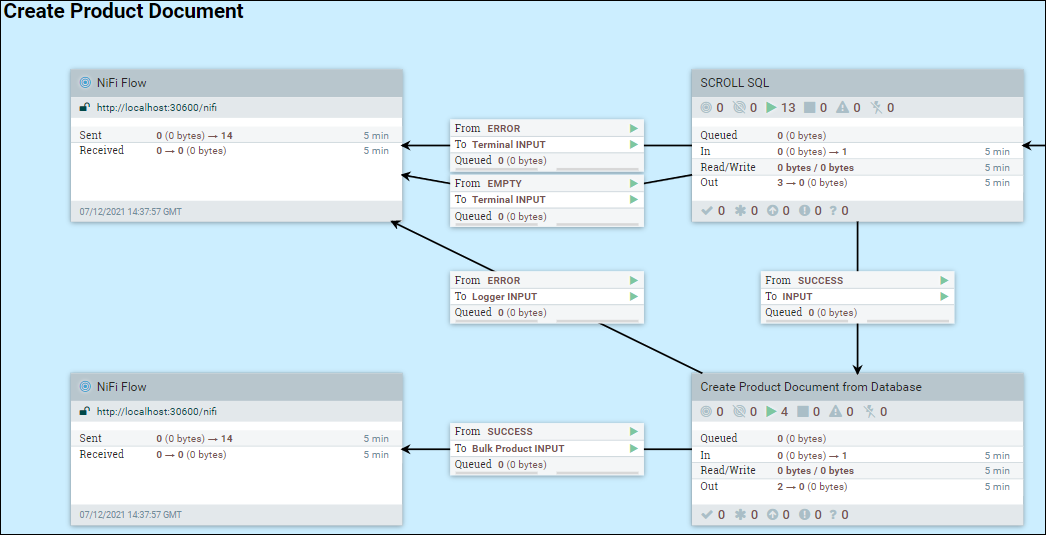
En el grupo de procesos, el conjunto de datos se obtiene de la base de datos utilizando una única secuencia SQL. Por ejemplo, Find Associations en DatabaseProductStage1b.
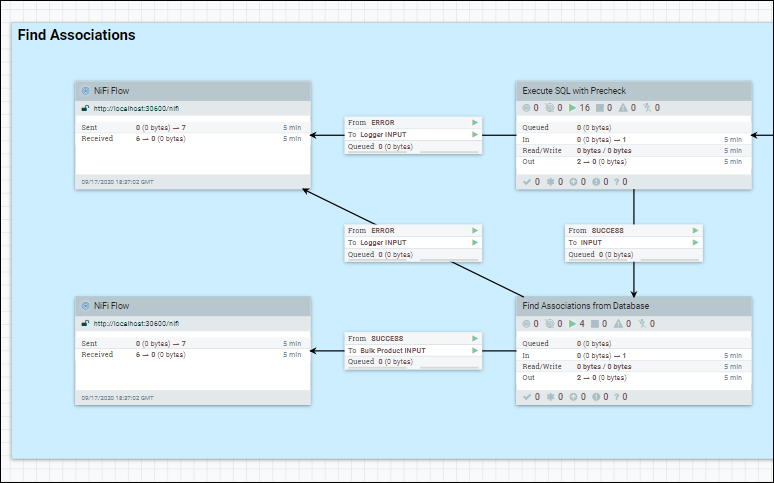
Ingrese al grupo Procesador que estamos optimizando, haga clic derecho en el lienzo base y seleccione variables.
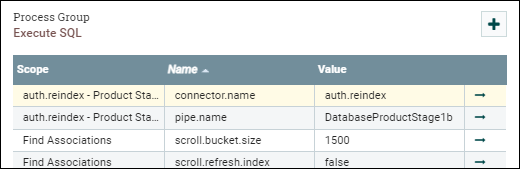
Establezca el parámetro scroll.bucket.size en el número que desee.
El scroll.bucket.size es el número de filas de los datos captados que se colocan en cada grupo para su procesamiento. El archivo bucket.size determinará el tamaño de los archivos de flujo (y el número de documentos contenidos en cada archivo).
- Captar datos de Elasticsearch
-
Puesto que la creación de índice es un proceso por etapas, es posible que se haya añadido cierta información a los documentos de índice existentes. En el caso de, NiFi necesita captar datos de Elasticsearch. Utilicemos el URL de etapa 2 como ejemplo.
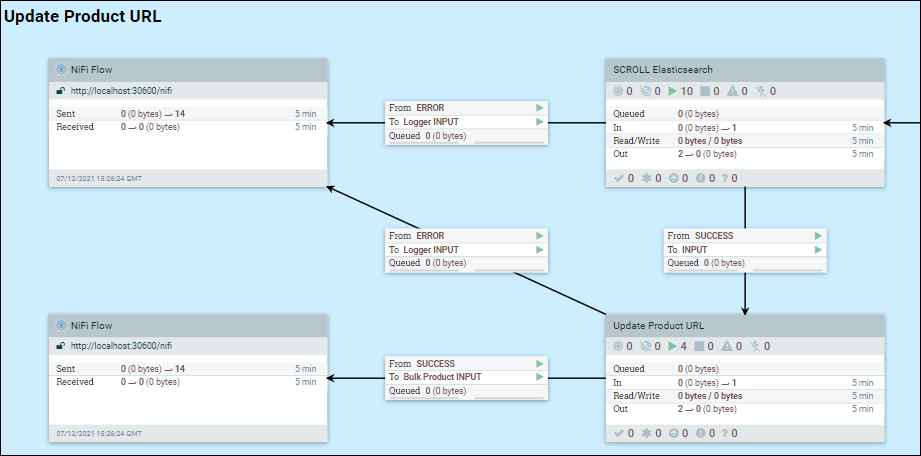
Introduzca al grupo SCROLL Elasticsearch, haga clic con el botón derecho en el lienzo base y seleccione las variables.
Cambie scroll.bucket.size y scroll.page.size por los valores que desee, basándose en las consideraciones siguientes:
scroll.page.size es el número de documentos que se captan de Elasticsearch. Si el número es demasiado pequeño, NiFi debe realizar más conexiones con Elasticsearch.
scroll.bucket.size es el número de documentos de los datos captados en cada grupo para su proceso. El archivo bucket.size determinará el tamaño de los archivos de flujo (y el número de documentos contenidos en cada archivo).
Otro parámetro que es útil para el ajuste es scroll.duration. Este valor define la cantidad de tiempo que Elasticsearch almacenará el conjunto de resultados de la consulta en la memoria. Este parámetro es útil cuando se trata de muchas tiendas e idiomas que se ejecutan en paralelo, donde se puede encontrar un error de desplazamiento sin salida. Este error indica que se está quedando sin espacio de desplazamiento y la reducción de la duración del desplazamiento obligará a Elasticsearch a liberar búferes más antiguos u obsoletos más rápido. A la inversa, aumentar la duración del desplazamiento en Elasticsearch para ese índice proporcionará tiempo adicional para completar las operaciones de procesamiento.
- Procesando grupo de datos
-
En el ejemplo siguiente, se utiliza el grupo de procesos DatabaseProductStage 1a.
Introduzca Crear documento de producto desde la base de datos, haga clic con el botón derecho en Crear documento de producto desde la base de datos y seleccione configurar. En la pestaña SCHEDULING, actualice el valor Tareas simultáneas para establecer el número de hebras que se utilizarán para el grupo de procesos. Al aumentar el número de tareas simultáneas, el uso de memoria para el grupo de procesos también aumenta en consecuencia. Por lo tanto, establecer este valor en un número mayor que el número de CPU asignadas al pod, o más allá de la cantidad de memoria asignada al pod, puede no tener sentido y puede tener un impacto negativo en el rendimiento.
- Subiendo grupo de documentos
-
Especifique el grupo Bulk Elasticsearch. Se visualizan varios procesos. Pulse con el botón derecho en cada proceso y seleccione configurar En la pestaña SCHEDULING, actualice los valores de Tareas simultáneas a uno que tenga sentido para su entorno.
El Post Bulk Elasticsearch processor envía los documentos de índice creados a Elasticsearch. De forma predeterminada, Elasticsearch utilizará el mismo número de CPU que el número de conexiones. Teniendo en cuenta la posible demora o grupos, el número que se establece para el Post Bulk Elasticsearch processor puede ser mayor que el número de CPU asignadas al pod Elasticsearch.
Es una buena regla general considerar todos los procesos de un grupo juntos. En general, es mejor intentar que los procesos posteriores se completen más rápidamente que los anteriores. De lo contrario, los objetos en cola consumirán memoria adicional y ralentizarán la eficiencia de proceso global.
Consideraciones generales para el ajuste
- Tareas/hebras simultáneas
- Aumentar el número de subprocesos que se procesan puede ayudar a mejorar el rendimiento de un grupo de procesamiento, sin embargo, esto debe evaluarse con cuidado.
- Tamaño del depósito/tamaño del archivo de flujo
- Al aumentar el tamaño del depósito, aumenta el tamaño del archivo de flujo, es decir, el número de documentos que se procesan como un grupo en NiFi. Cuanto mayor sea el archivo de flujo, mejor será la eficacia. Sin embargo, los recursos limitados del sistema operativo limitarán el tamaño máximo del archivo de flujo.
- El ajuste del tamaño del archivo de flujo es muy visible y tiene un gran impacto en el sistema.
- Los archivos de flujo grandes tienen varios efectos secundarios negativos:
- Exigen una gran cantidad de memoria para NiFi.
- Requieren un embudo coincidente en Elasticsearch para aceptar los datos a medida que llegan.
- La sobrecarga de NiFi GC puede llegar a ser prohibitivamente alta, o NiFi puede quedarse sin espacio de pila con un error
Out of Memory.
- Contrapresión en los vínculos entre procesos, grupos de procesos y subgrupos de procesos
- En la canalización, hay muchos enlaces entre pasos. Cada enlace tiene su propia cola para los objetos resultantes (elementos en cola) para procesar en el siguiente paso.
-
-