Parámetros ajustables en la configuración de NiFi y Elasticsearch
Cómo puede modificar los valores para los parámetros ajustables, y algunos valores predeterminados y cómo se pueden mejorar en distintas circunstancias.
Recursos del sistema, espacio de memoria y asignación de CPU
El entorno (recomendado o mínimo) estará constituido por varios nodos que albergarán los pods de NiFi y Elasticsearch. En general, después de la instalación inicial, tendrá tres pods para Elasticsearch y un NiFi.
En la configuración mínima, cada uno de los pods tiene asignadas seis vCPUs y 10 GB de memoria.
En la configuración recomendada, cada uno de los pods tiene asignadas unas vCPUs y un mínimo de GB de memoria.
Es posible realizar ajustes o aumentar los recursos asignados. En estos casos, sin embargo, es necesario realizar pruebas adicionales para validar dichos cambios de configuración, a fin de garantizar la estabilidad y la operatividad.
Espacio en disco por nodo
La cantidad en espacio de disco necesaria depende en gran medida del tamaño de su índice. Puesto que varía mucho entre distintas instalaciones, no hay una sola figura recomendada. Para calcularlo, tenga en cuenta que un índice de un millón de artículos de catálogo que se ejecutan en la configuración del sistema recomendada genera un índice de aproximadamente seis gigabytes de tamaño.
Sin embargo, este número no refleja los requisitos reales. Los archivos de índice están fechados y con el tiempo se acumularán en el disco. Como regla general, prepare al menos diez veces el espacio en disco del tamaño de índice previsto para reflejar esta variabilidad y limpie los archivos de índice antiguos diariamente. En el caso del índice de seis gigabytes, esto significaría asignar al menos sesenta gigabytes y eliminar los archivos obsoletos frecuentemente.
NiFi
La velocidad de procesamiento del conjunto de datos y la velocidad resultante de la creación del índice de búsqueda es el resultado del rendimiento que se puede lograr en el clúster de NiFi y Elasticsearch. Hay varios parámetros que mejorarían y optimizarían el rendimiento para una huella de hardware determinada; hebras de procesadores NiFi y tamaño de cubeta.
Hebras
Cada procesador en NiFi tiene la capacidad de procesar archivos de flujo simultáneamente. Para lograr esto, debe asignar más hebras al procesador o establecer la variable Tareas simultáneas para que sea superior a una. La siguiente captura de pantalla representa un procesador NLP que está establecido para realizar tareas simultáneas iguales al número de VCPUs que están disponibles en el nodo.
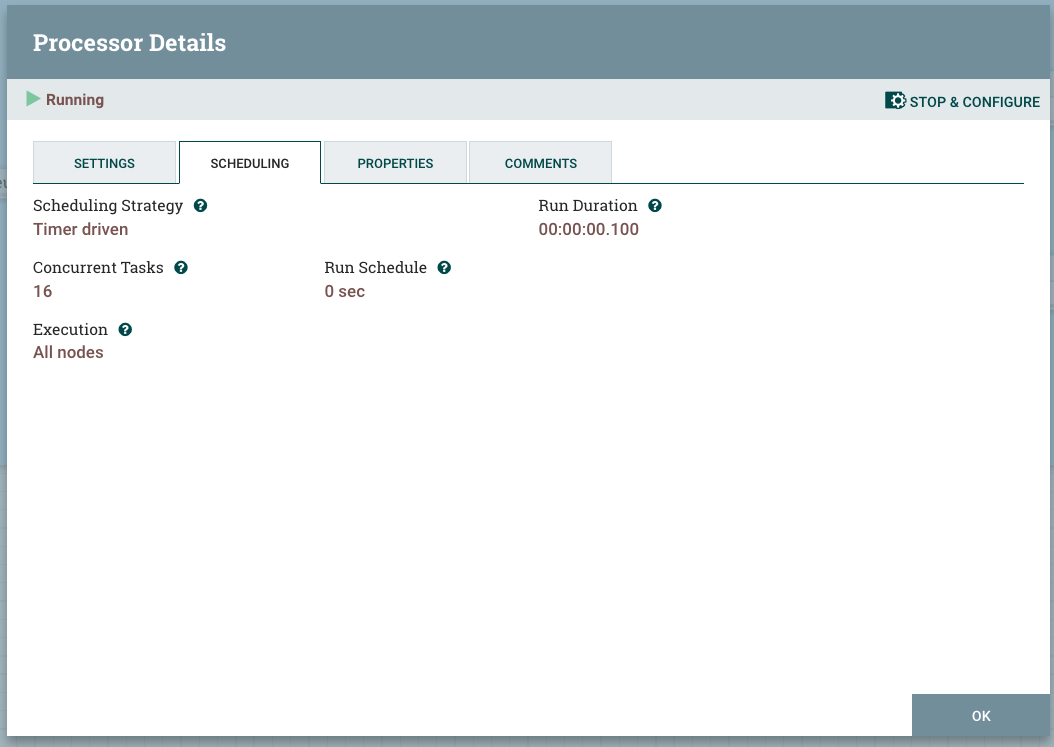
Si aumenta las hebras del procesador, mejorará el rendimiento del procesador. Los subprocesos adicionales aumentarían el ancho de banda del procesador por el factor del número de subprocesos, si el procesador está haciendo procesamiento computacional (es decir, puede experimentar un escalado lineal). En el caso de las operaciones de E/S, el procesador experimentará una cierta mejora que empezaría a disminuir a partir de cierto nivel de subprocesos (es decir, una escalabilidad no lineal que acabaría en saturación).
En el caso del procesador NLP, el procesador es puramente informático y el límite de hebra se considera el mismo número de vCPUs que están disponibles para el pod NiFi.
Tamaño del cubo
El tamaño de grupo (scroll.bucket.size) es otro parámetro que puede cambiar para mejorar el ancho de banda del procesador. Cambia el tamaño del archivo de flujo que se procesa. Al aumentar el tamaño del depósito, aumenta el tamaño de los datos que serán procesados por un solo procesador como grupo.
Los cambios de tamaño de grupo son un poco más difíciles de implementar. La ubicación de la variable está en los parámetros de segundo nivel del grupo de procesadores.
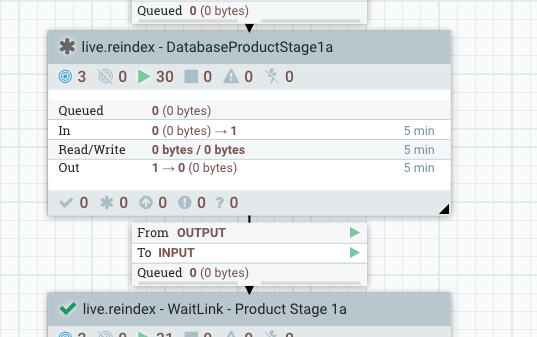
Por ejemplo, para DataBaseProductStage1a:
El nivel superior tiene este aspecto:
Profundice un nivel, pulse con el botón derecho en Crear documento de producto y seleccione las variables.
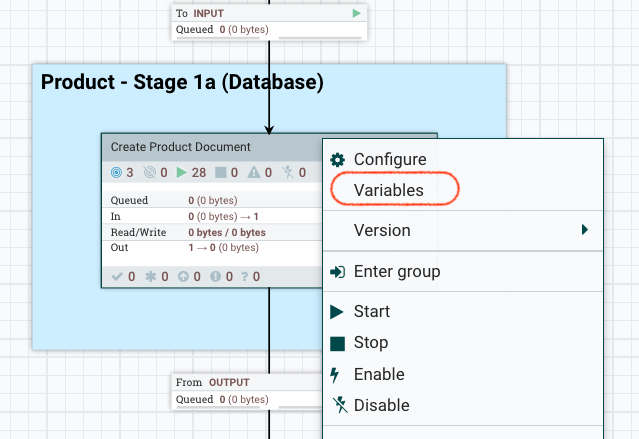
Se abre la ventana Variables. Aquí puede cambiar el valor del tamaño del cubo.
LISTAGG() y Serialize
En la canalización de Ingest, la mayoría de SQL utilizan el agregado para combinar varias filas. Debido a una limitación de la base de datos (especialmente con Oracle) y al tamaño de los datos, LISTAGG puede exceder los límites establecidos durante las compilaciones del índice live.reindex y auth.reindex. Para resolver el problema, podemos inhabilitar LISTAGG.
Puede establecer LISTAGG local o globalmente. Para establecerlo localmente, cambie el atributo flow.database.listagg.
UpdateAttribute, que actualizan los atributos de los archivos de flujo. Por ejemplo, si desea establecer flow.database.listagg="false" para AttributeStage1b en auth.reindex, establézcalo en las Propiedades de la siguiente manera: .- Vaya a .
- Haga doble clic en el procesador Definir desplazamiento y tamaño de página.
- Pulse STOP & CONFIGURE en la esquina superior derecha del procesador para detener el procesador.
- Pulse la pestaña Propiedades del procesador y, a continuación, pulse el icono + para añadir la propiedad
flow.database.listaggy establecer su valor enfalse. - Reinicie el procesador.
 Para las versiones 9.1.11 y posteriores, utilice el siguiente endpoint:
Para las versiones 9.1.11 y posteriores, utilice el siguiente endpoint: https://data-query/search/resources/api/v2/configuration?nodeName=ingest&envType=auth{ "global": { "connector": [ { "name": "attribute", "property": [ { "name": "flow.database.listagg", "value": "false" } ] } ] } }Puede realizar cambios globales utilizando perfiles de Ingest. Para obtener más información y un ejemplo acerca de cómo cambiar LISTAGG mediante un perfil de Ingest, consulte Configuración de Ingest a través de REST.
Cuando el agregado de la lista está deshabilitado, el proceso de SQL devolverá más filas y NiFi utilizará el proceso Serialize para manejar los datos devueltos. En ese caso, la duración del tratamiento de los datos será mucho mayor. Para tenerlo en cuenta, deben aumentarse page.size y bucket.size para el proceso SQL y el número de hebra para el proceso Serialize.
Elasticsearch
La siguiente sección discutirá algunas mejoras que se pueden realizar en la configuración de Elasticsearch para aumentar el rendimiento general y la velocidad de creación de índices.
- Tasa de actualización de los índices
- Por defecto, Elasticsearch actualiza periódicamente los índices cada segundo, pero solo en los índices que han recibido una solicitud de búsqueda o más en los últimos 30 segundos. El esquema de índice de HCL Commerce establece este intervalo en 10 segundos de forma predeterminada.
Sin embargo, si es viable, desactive este comportamiento estableciendo su valor en -1. Si inhabilitar esto no es viable, un intervalo de tiempo más largo, como 60 segundos, también tendrá un impacto. Al aumentar la frecuencia de actualización a periodos más largos, los documentos actualizados del almacenamiento intermedio de memoria se escriben con menos frecuencia en los índices (y finalmente se escriben en el disco). Esto mejora la velocidad de procesamiento en Elasticsearch, ya que con menos eventos de actualización se tendrá más ancho de banda de recursos para recibir datos. Además, siempre es más conveniente realizar actualizaciones masivas en el sistema de archivos. En el otro lado de la ecuación, los intervalos de actualización más largos harán que el búfer de memoria se infle mientras intenta adaptarse a todos los datos entrantes.
Para obtener más información sobre la configuración del intervalo de actualización del índice, consulte la documentación de Elasticsearch.
Para establecer un valor personalizado:Asegúrese de detener el procesador. Seleccione y edite el objeto json, sustituyendo el valor refresh_interval por el valor que desee.
- Tamaño de almacenamiento intermedio de índice
-
Los tamaños de almacenamiento intermedio de indexación ayudarán a acelerar la operación de indexación y mejorará la velocidad de creación de índice general.
El valor se establece en la variable indices.memory.index_buffer_size y, por lo general, se establece en el 10 % del tamaño del montón de forma predeterminada.
Establezca este valor en un valor superior al 20 % del tamaño del almacenamiento dinámico.
- Configuración del embudo de Elasticsearch
- El clúster de Elasticsearch tiene requisitos de embudo complicados. En general, para el uso normal, el clúster de Elasticsearch determinará los tamaños iniciales de los subprocesos en cada servidor de acuerdo con la cantidad de CPU disponibles para ese pod. En términos sencillos, si el pod está configurado para permitir hasta seis CPU, los subprocesos de trabajo también se limitarán al mismo número.
Sin embargo, esto puede no ser suficiente cuando se trata de catálogos grandes y tamaños de cubos grandes. En el caso de la creación de índice, se emite una solicitud de actualización masiva desde NiFi a Elasticsearch. El nodo maestro de Elasticsearch recibe el cuerpo de la solicitud, que se compone de varios documentos, y para cada documento, determina el fragmento en el que debe almacenarse. Se abre una conexión con el nodo/fragmento adecuado para que el documento se pueda procesar.
Por lo tanto, la actualización masiva termina utilizando varias conexiones, y es muy posible que se quede sin hebras y conexiones. Si Elasticsearch se queda sin conexiones, se devuelve un código
429de respuesta. Esto interrumpirá el proceso de creación de índice y la creación del índice fallará.Para adaptarse a las necesidades de más conexiones y hebras, el servidor Elasticsearch se puede configurar para empezar con más hebras y una cola de conexiones más profunda en cada nodo. El siguiente archivo describe las configuraciones clave de Elasticsearch (los contenidos se establecen dentro del archivo de configuraciónes-config.yaml):replicas: 3 minimumMasterNodes: 2 ingress: enabled: true path: / hosts: - es.andon.svt.hcl.com tls: [] volumeClaimTemplate: accessModes: [ "ReadWriteOnce" ] storageClassName: local-storage-es resources: requests: storage: 15Gi esJavaOpts: "-Xmx12g -Xms12g" resources: requests: cpu: 2 memory: "14Gi" limits: cpu: 14 memory: "14Gi" esConfig: elasticsearch.yml: | indices.fielddata.cache.size: "20%" indices.queries.cache.size: "30%" indices.memory.index_buffer_size: "20%" node.processors: 12 thread_pool: search: size: 100 queue_size: 10000 min_queue_size: 100 max_queue_size: 10000 auto_queue_frame_size: 10000 target_response_time: 30s thread_pool: write: size: 100 queue_size: 10000El archivo define dos hebras, escritura y búsqueda.
Para cada cola de hebras, podemos definir los parámetros siguientes:- size: el número de hebras de trabajador por nodo.
- queue_size: el número de conexiones que se pueden recibir y rastrear en la cola de conexiones
- min_queue_size: el tamaño mínimo de la cola de conexiones.
- max_queue_size: el tamaño máximo de cola, más allá de Elasticsearch, que enviará el código de respuesta 429.
Los valores reales deben ser específicos del entorno y de su configuración.
Aumentar los subprocesos de trabajo a 100 y el grupo de conexiones a 10000 será suficiente para catálogos de 1 millón de elementos en un clúster de Elasticsearch de 3 nodos y 3 fragmentos con las configuraciones predeterminadas en su lugar.
Para aplicar los cambios, el clúster de Elasticsearch debe reinstalarse usando el nuevo archivo de configuración.
Los pasos siguientes describen el proceso:- Suprima el clúster Elasticsearch existente.
helm delete -n elastic elasticsearch - Vuelva a instalar el clúster Elasticsearch utilizando el archivo de configuración modificado.
helm install elasticsearch elastic/elasticsearch -f es_es_config.yaml -n elastic
Fragmentación
- Un fragmento de índice no debe superar el 40 % del almacenamiento total disponible de su clúster de nodo.
- Un tamaño de fragmento de índice no debe superar los 50 GB. Generalmente, el índice tiene un mejor rendimiento cuando su tamaño es inferior a 25 GB por fragmento.
- Los recuentos y tamaños de documentos entre fragmentos deberían ser similares.