
Paneles de subprocesos activos
Los paneles de grupos de subprocesos muestran información en tiempo real sobre los subprocesos de los trabajadores y sus operaciones en el clúster, con métricas que incluyen el número de tareas en espera de ejecución y el número de subprocesos activos. Comprender el rol de cada grupo de subprocesos, como los grupos genéricos, de búsqueda, en masa, de indexación, GET, de escritura y de análisis, es crucial para resolver problemas y optimizar el rendimiento en Elasticsearch (ES). Además, los datos de campo y las memorias caché de consulta ayudan a acelerar las operaciones de búsqueda, pero es posible que deban borrarse periódicamente, lo que provocará ralentizaciones temporales.
Los paneles de grupos de subprocesos muestran información en tiempo real sobre los subprocesos de los trabajadorea y sobre cómo operan en el clúster. La información se encuentra en el nivel del clúster, pero cada grupo de subprocesos se muestra por nodo ES.
- Operaciones de grupos de subprocesos en cola.
- Subprocesos de grupos de subprocesos activos.
Operaciones de grupos de subprocesos en cola indica el número de tareas en espera de ejecución, mientras que Subprocesos de grupos de subprocesos activos indica el número de subprocesos que están ejecutando tareas. Ambas métricas son esenciales para supervisar el estado y el rendimiento de Elasticsearch.
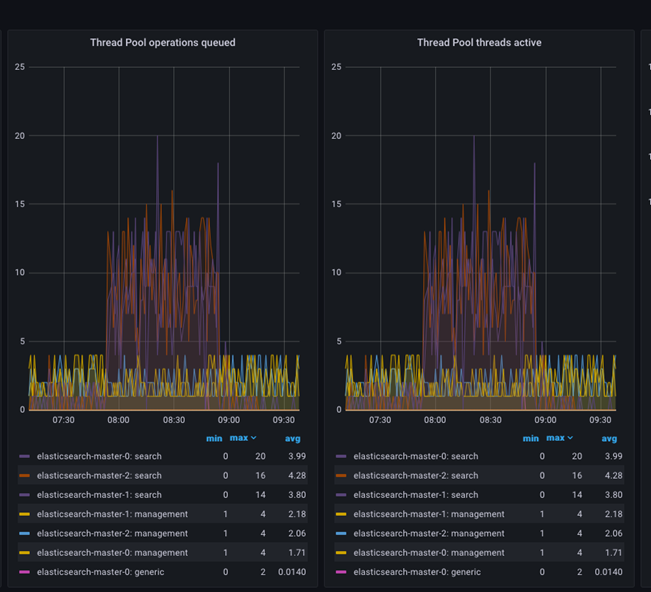
La métrica Operaciones de agrupación de hebras en cola indica el número de tareas en espera de que el grupo de subprocesos las ejecute. Esto puede suceder cuando el número de tareas sometidas al grupo de subprocesos supera el número máximo de subprocesos disponibles para ejecutarlas. Cuando esto sucede, las tareas se colocan en una cola y se ejecutan tan pronto como un subproceso pasa a estar disponible.
La métrica Subprocesos de grupos de subprocesos activos indica el número de subprocesos que están ejecutando tareas de forma activa. Cuando este número es cercano al número máximo de subprocesos disponibles, puede indicar que el sistema tiene demasiada carga y que puede estar experimentando problemas de rendimiento.
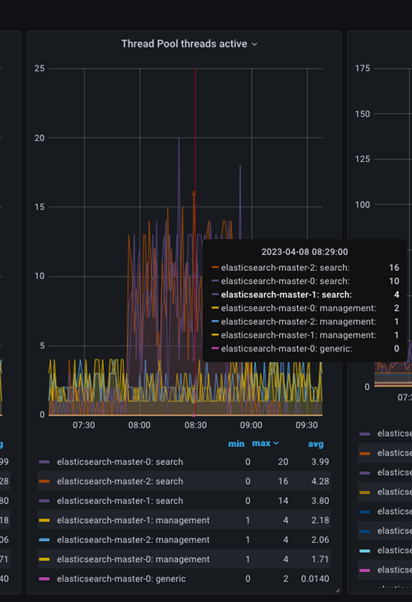
Para inspeccionar los subprocesos activos de forma adicional, coloque el puntero del ratón sobre el gráfico en un momento específico para obtener el recuento de subprocesos activos en dicho momento, tal como se muestra en la siguiente imagen.
- Grupo de subprocesos genérico
- Este grupo de subprocesos ejecuta tareas que no encajan dentro de ningún grupo de subprocesos especializado. El grupo de subprocesos genérico ejecuta tareas internas dentro de Elasticsearch, como enviar y recibir solicitudes de red.
-
- Grupo de subprocesos de búsqueda
- Este grupo de subprocesos se utiliza para ejecutar solicitudes de búsqueda. Se utiliza para gestionar tareas relacionadas con operaciones de búsqueda, como la consulta y filtración de datos. El número de subprocesos del grupo de subprocesos de búsqueda se establecerse generalmente según el número de núcleos de CPU disponibles en el nodo de Elasticsearch.
-
- Grupo de subprocesos en masa
- Este grupo de subprocesos ejecuta solicitudes de indexación en masa. Se encarga de gestionar tareas relacionadas con la indexación de grandes volúmenes de datos.
-
- Grupo de subprocesos de indexación
- Este grupo de subprocesos ejecuta las solicitudes de indexación que no se realizan en masa. Es el grupo responsable de gestionar las tareas relacionadas con la indexación de documentos individuales.
-
- Grupo de subprocesos
GET - Este grupo de subprocesos se utiliza para ejecutar solicitudes
GET. Se ocupa de gestionar las tareas relacionadas con la recuperación de documentos individuales.
- Grupo de subprocesos
-
- Grupo de subprocesos de escritura
- Este grupo de subprocesos ejecuta operaciones relacionadas con la escritura, entre las que se incluye la indexación, actualización y supresión de documentos. Gestiona tareas relacionadas con operaciones de escritura que no pueden ejecutarse en el grupo de subprocesos en masa o en el grupo de subprocesos de indexación.
-
- Grupo de subprocesos de análisis
- Este grupo de subprocesos se utiliza para ejecutar tareas de análisis. Gestiona tareas relacionadas con el análisis de textos, como la tokenización y el filtrado.
-
- Grupo de subprocesos de instantáneas
- Este grupo de subprocesos ejecuta instantáneas y restaura operaciones. Gestiona las tareas relacionadas con las copias de seguridad y la restauración de datos.
Note: El número de subprocesos en los grupos de subprocesos en masa, de indexación, GET, de escritura, de análisis y de instantáneas normalmente se establece con un valor pequeño, como 1 o 2, para evitar que el sistema se sobrecargue.
Cada grupo de subprocesos tiene su configuración, como el número máximo de subprocesos y el tamaño de la cola; estos se pueden configurar para optimizar el rendimiento teniendo en cuenta las necesidades específicas del despliegue de Elasticsearch.
Los grupos de subprocesos de escritura y de solicitudes de búsqueda son los dos subgrupos más importantes, y deben observarse y priorizarse detenidamente. En función del nivel y de la combinación de las cargas de trabajo, es posible que se necesite disponer de la configuración adecuada para cada grupo de subprocesos para poder controlar el flujo de carga de trabajo y mantener el funcionamiento del clúster estable.
Memorias caché internas de Elasticsearch:
-
- Memoria caché de datos de campo
- La memoria caché de datos de campo se utiliza para almacenar valores de campos a los que se accede con frecuencia, y ayuda a acelerar la clasificación de agregaciones y de campos con script. La memoria caché de datos de campo se implementa como una memoria caché de referencia no válida, lo que significa que el recopilador de basura puede borrar la memoria caché cuando la memoria es escasa.
-
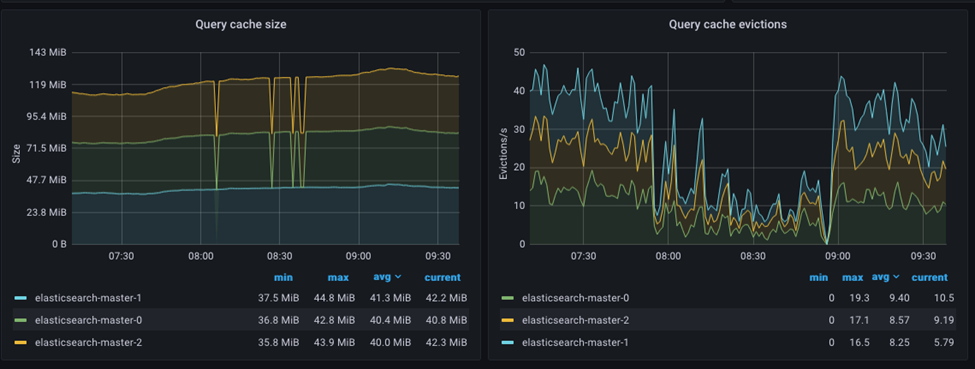
- Memoria caché de consulta
- La memoria caché de consulta se utiliza para almacenar los resultados de consultas ejecutadas con frecuencia, por lo que ayuda a acelerar las operaciones de búsqueda. La memoria caché de consulta se implementa como una memoria caché Least Recently Used (LRU), lo que significa que las consultas ejecutadas menos recientemente se desalojan de la memoria caché cuando esta se llena.
La memoria caché de campo, por ejemplo, se borrará siempre que se lleve a cabo una operación de renovación de índice o fusión de índice, lo que requiere que se carguen nuevos valores de campo desde el disco a la memoria. Siempre que se realiza una operación de reindexación, como cuando se añade o cambia el índice un documento nuevo, la memoria caché de consulta se elimina por completo.
Es importante tener en cuenta que borrar la memoria caché puede provocar que el rendimiento disminuya de forma temporal, ya que la memoria caché tendrá que volver a llenarse con datos nuevos.