Full reindexing connector
This topic describes the dataflow of the default NiFi connector used for full-reindexing of the Elasticsearch search index.

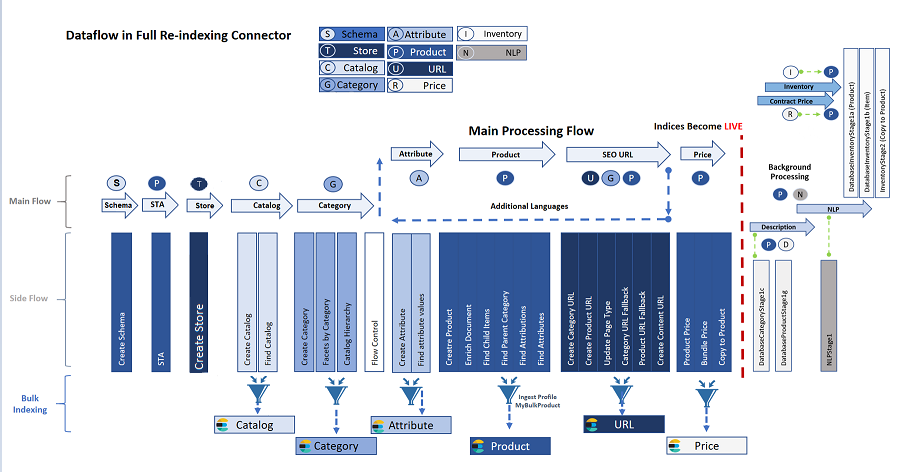
Full reindexing connector dataflow
The reindexing connector rebuilds the Elasticsearch search index. This index consists of the indices Store, Catalog, Category, Attribute, Product, URL, and Price. The indexing process starts with the creation of a schema, the product database, and STA. Data is loaded by drilling progressively down into catalog and then category. Then the main flow loop takes over, processing attributes to products to SEO URLs and finally emerging from that loop, to price.
The following diagram illustrates this dataflow as of HCL Commerce Version 9.1.10. The flow consists of four main stages, each of which contains sub-stages that may repeat. Each stage is further described in Table 1.
|
Full Reindexing Connector Pipeline Dataflow Stages & Pipe/Flow Names |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| LANGUAGE LOOP | ||||||||||
| SCHEMA | STA | STORE | CATALOG | CATEGORY | ATTRIBUTE | PRODUCT | SEO URL | PRICE | BACKGROUND | |
|
Store1 StoreSchema2 |
Zookeeper DatabaseSTAZookeeperStage1 |
Store DatabaseStoreStage1 |
1a (Main Document) DatabaseCatalogStage1a |
1a (Main Document) DatabaseCategoryStage1a |
1a (Main Document) DatabaseAttributeStage1a |
1a (Main Document) DatabaseProductStage1a |
1a (Category URL) DatabaseURLStage1a |
1a (Find Product Prices) DatabasePriceStage1a |
Category Stage 1c (Long
Descriptions) DatabaseCategoryStage1c |
|
| Catalog
CatalogSchema |
Synonym Stopword LoadSTASynonymsStopwordStage1 |
1b (Find Filters) DatabaseCatalogStage1b |
1b (Find Facets) DatabaseCategoryStage1b |
1b (Find Attribute
Values) DatabaseAttributeStage1b |
1b (Enrich Document) DatabaseProductStage1b |
1b (Product URL) DatabaseURLStage1b |
1b (Find Bundle Prices) DatabasePriceStage1b |
Product Stage 1g (Long
Descriptions) DatabaseProductStage1g |
||
| Attribute
AttributeSchema |
1d (Build Hierarchy) DatabaseCategoryStage1d |
1h (Find Child Items) DatabaseProductStage1h |
1c (Page Type) DatabaseURLStage1c |
2 (Copy To Product) CopyLink |
Enrich NLP NLPStage1 |
|||||
| URL URLSchema |
1e (Find Hidden Facets) DatabaseCategoryStage1e |
1i (Find Parent
Category) DatabaseProductStage1i |
1d (Category URL Fallback) DatabaseURLStage1d |
SplitLink – Inventory (Launches separate Inventory Connector:) |
||||||
| Category
CategorySchema |
1e (Find Attributions) DatabaseProductStage1e |
1e (Product URL Fallback) DatabaseURLStage1e |
Inventory Stage 1a (Parent
Inventories) DatabaseInventoryStage1a |
|||||||
| Product
ProductSchema |
1f (Content URL) DatabaseURLStage1f |
Inventory Stage 1b (Child
Inventories) DatabaseInventoryStage1b |
||||||||
| Description
DescriptionSchema |
Inventory Stage 2 (Copy To
Product) InventoryStage2 |
|||||||||
| Price
PriceSchema |
||||||||||
| Inventory
InventorySchema |
||||||||||
| Workspace
WorkspaceSchema |
||||||||||
1Process Group Label
2Pipe Name / Flow Name (use Flow Names in NiFi to find specific Process Groups in a given Stage)

eSite versus Catalog Asset Store reindexing
As described in Choosing your index model, HCL Commerce Search Version 9.1.12 introduces an alternative to the preexisting eSite indexing model. In that model, reindexing for eSite stores uses the process flow described in Full reindexing connector dataflow. Focusing on the main and side flows, the processes are performed in the following sequence:
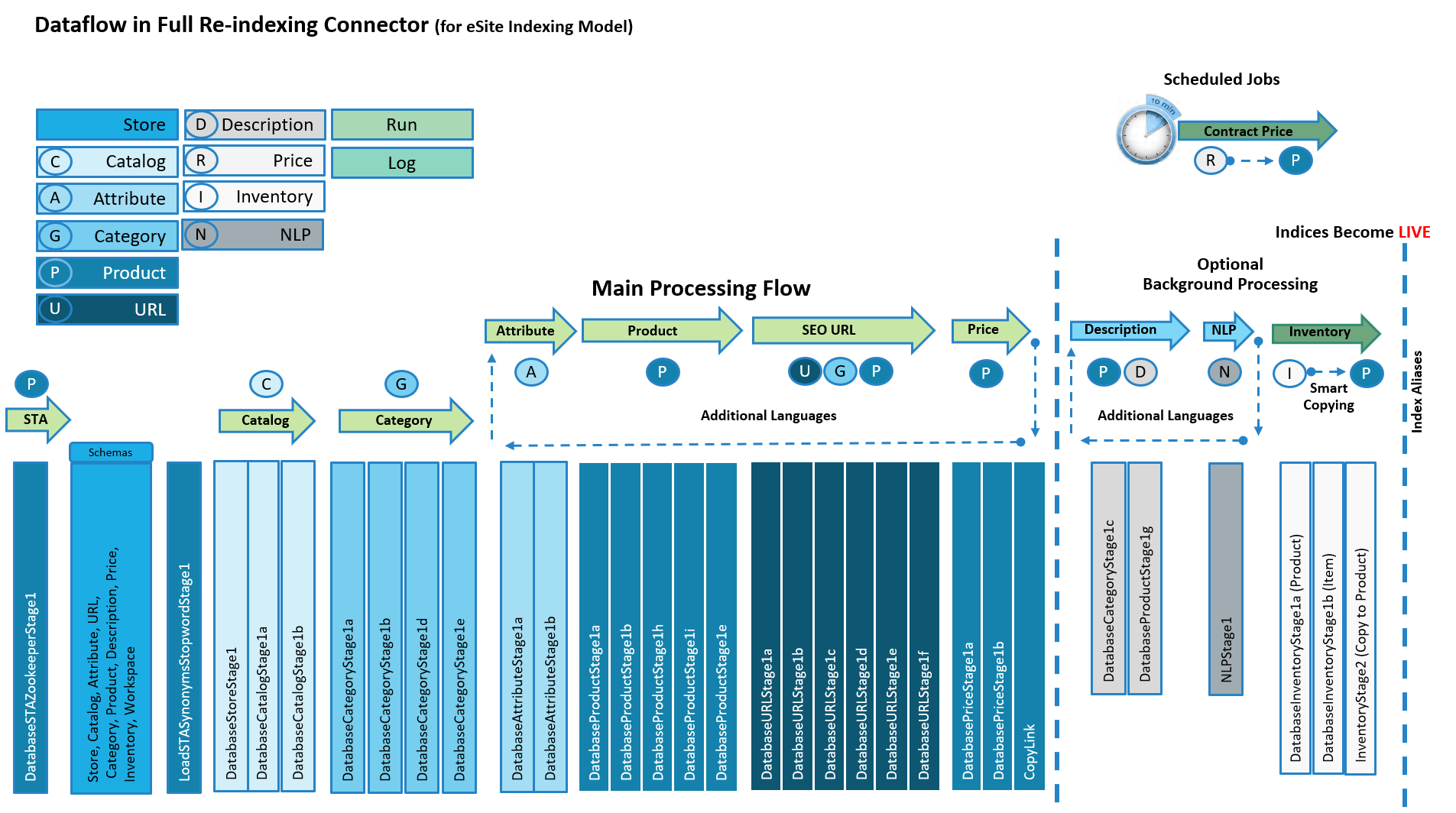
Each processing flow can only accommodate one store and one supported language at a time. A flow control component is used to perform recurring internal dataflows in order to manage additional supported languages. SEO URL and other related metadata are indexed into a separate URL index for query time lookup.
In contrast, the Catalog Asset Store (CAS) indexing approach processes all underlying extended sites and their supported languages in one single dataflow. The processing stages are very similar to the eSite model, except that the URL stage is replaced with a Page stage that only indexes SEO templates associated with each keyword. SEO URL and meta data are no longer indexed and are calculated and cached at query time instead. The resulting process flow is shown in the following diagram.
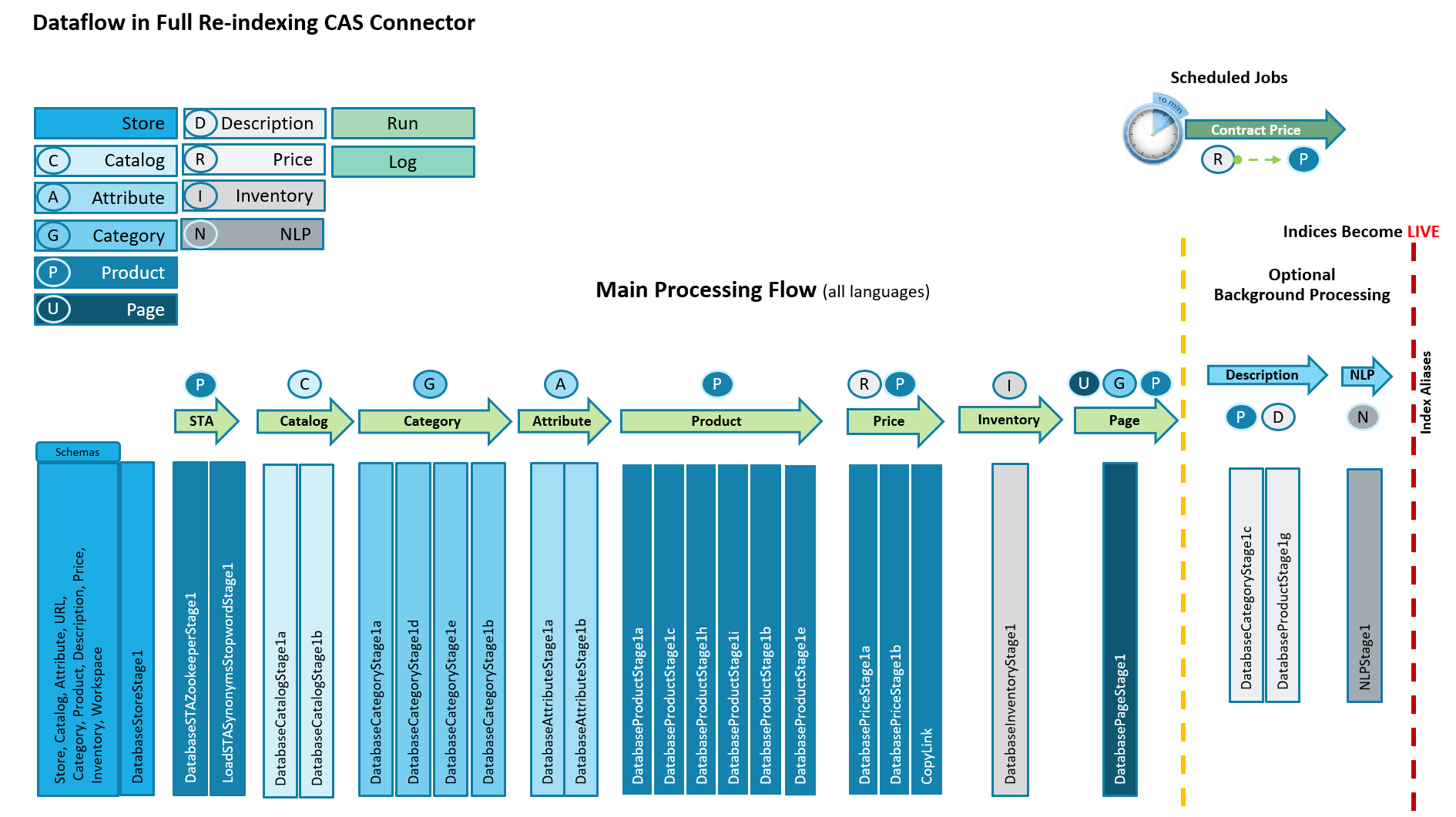
For more information about indexing flow in the CAS indexing model, see Catalog Asset Store index features.