
Catalog Asset Store index features
Indexing in the Catalog Asset Store (CAS) model is different from the eSite approach. It also has URL index and Near Real Time (NRT) enhancements that reduce processing load and improve efficiency.
Indexing stages
The legacy eSite indexing process uses the Re-indexing connector flow to index eSite stores. There is a main processing pipeline, and optional side stages where additional data processing can occur.
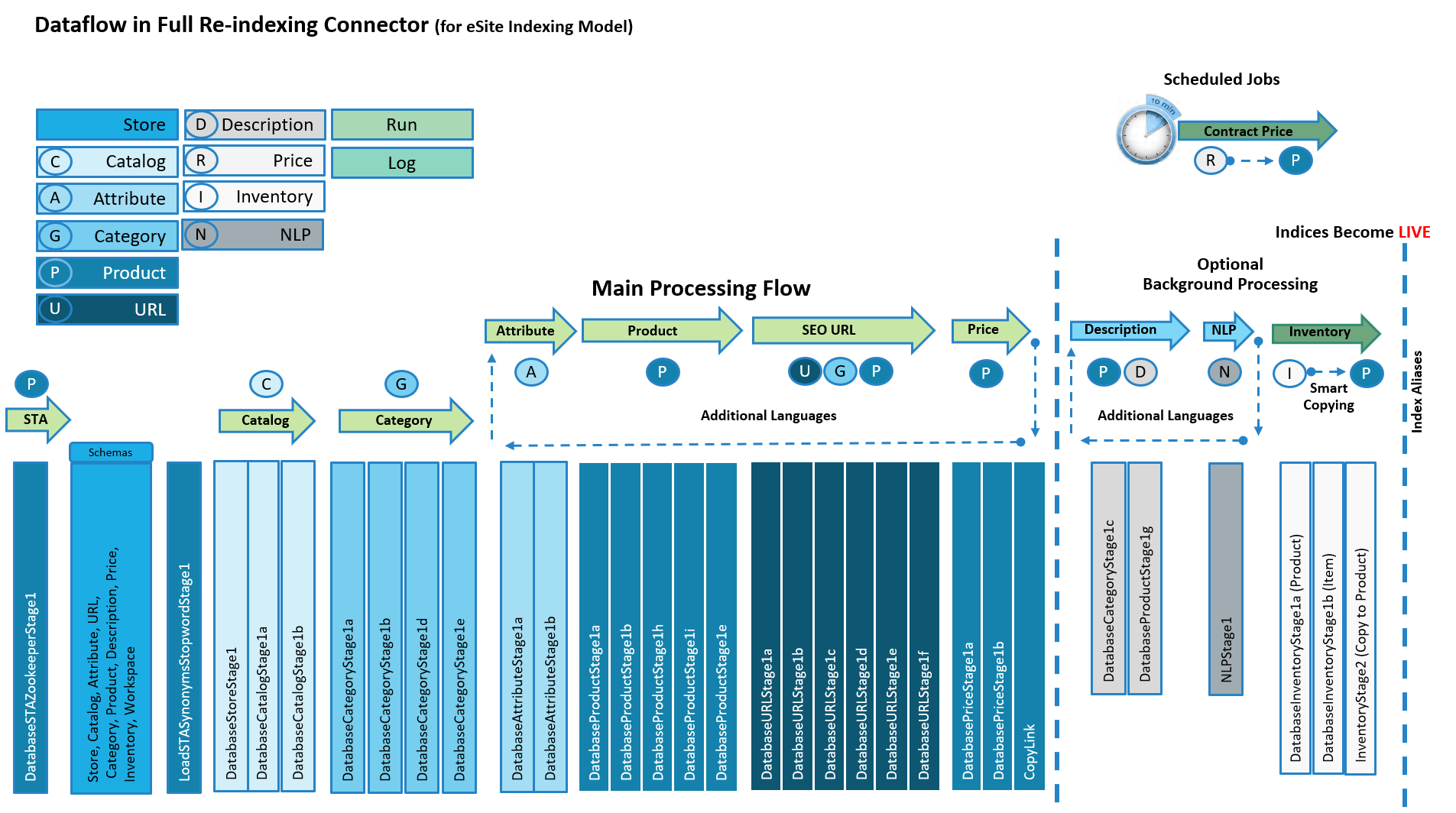
Each processing flow can only manage one store and one language at a time. A flow control component is used to perform recurring internal dataflows to handle additional supported languages.
SEO URL and other related meta data are indexed into a separate URL index for query-time lookup.
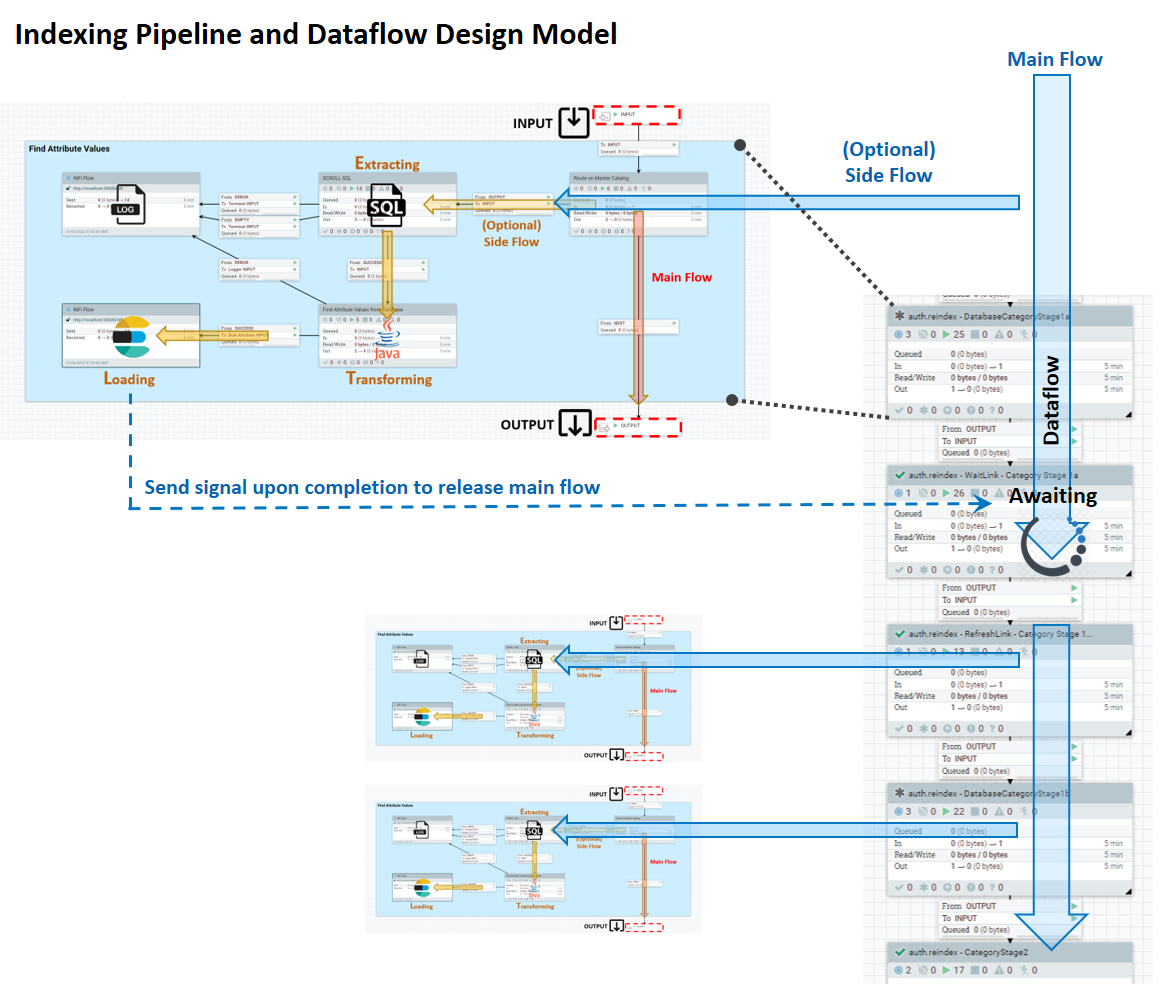
Each side flow stage is constructed in a similar manner from a boilerplate design, with an input module, a main processing module, and an output module. The stage is connected by a link to the next stage, and also invokes a logging process. Within this structure, you can customize the processing according to your business objectives.
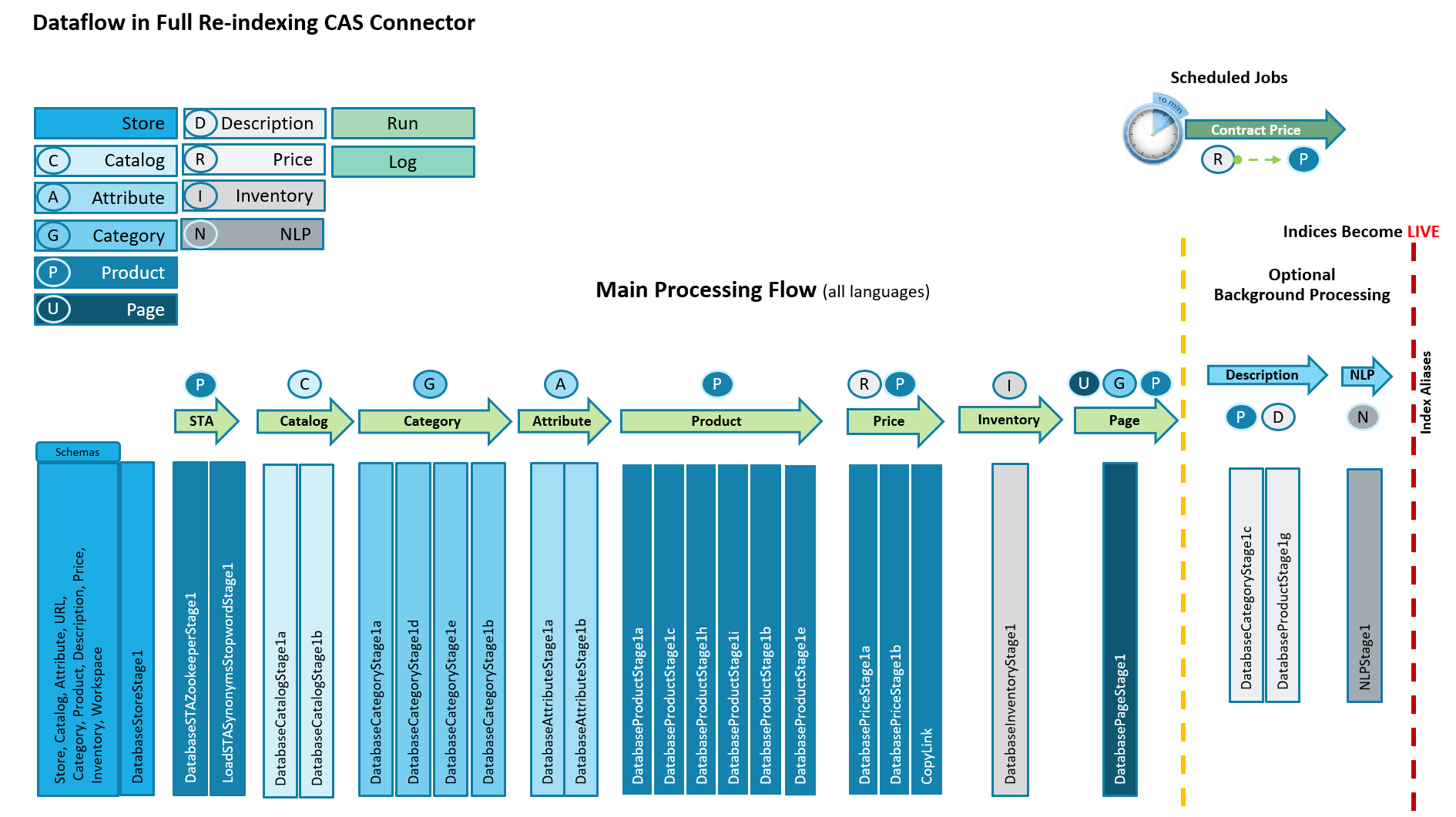
The CAS indexing flow is slightly different. It processes all of the underlying extended sites and all of their supported languages in one single dataflow.
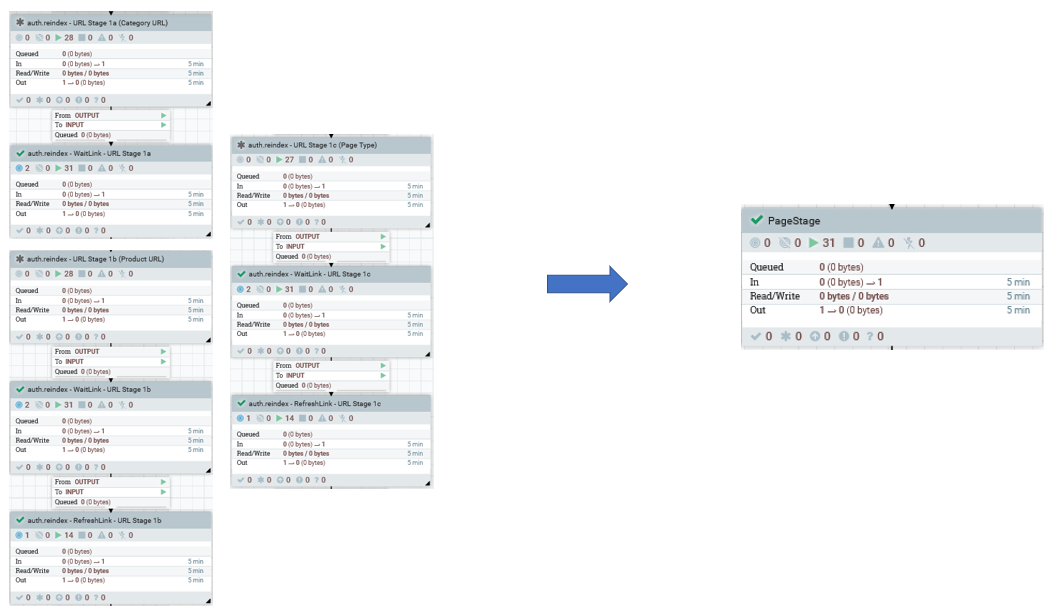
The CAS main processing flow is otherwise very similar to the eSite model, except that the URL stage is now replaced with a Page stage which only indexes SEO template associated with each keyword. For more information, see URL index enhancements, below. SEO URLs are indexed in the Category and Product Index.
The CAS indexing pipeline flow is very similar to the eSite model, but the internal dataflow design is quite different:
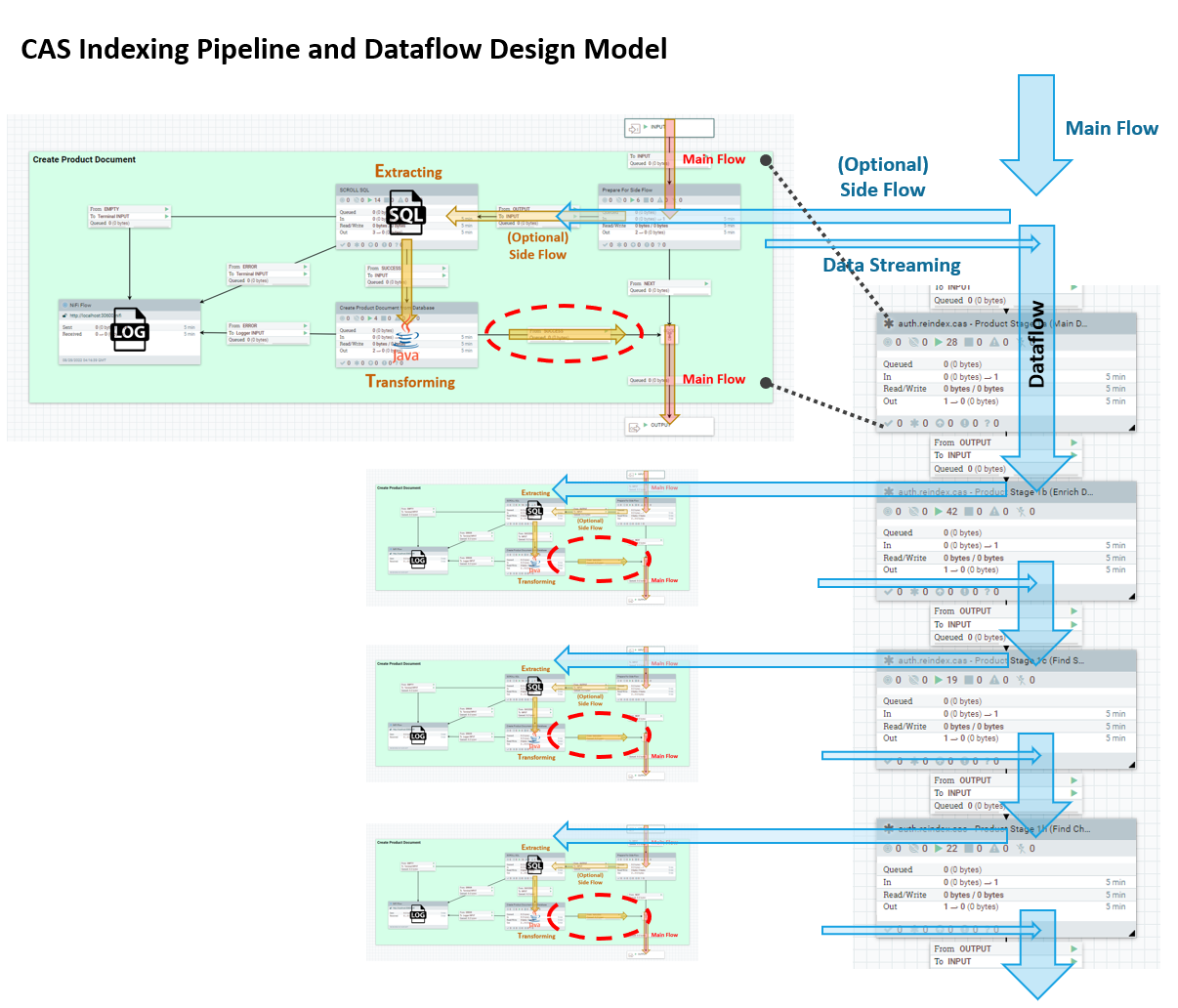
Each stage no longer writes incremental updates to Elasticsearch. Instead, each stage streams the work-in-progress document down to the next stage where additional business data can be merged in. This process repeats until it reaches the end of the indexing pipeline in a final Product pipe.
At the end of each pipeline (i.e., a series of stages and pipes), the work-in-progress document will then be converted into an index-ready document for Elasticsearch. This completed document will be sent to Elasticsearch just once.

Each flowfile is self-contained. It contains all the information and data that was used to assemble its contents. This approach removes the dependency on any external temporary storage in between stages, avoids the need to co-ordinate flowfiles between stages (i.e. WaitLink), and even makes troubleshooting much easier.
SQL for extracting business data from the data source, such as a database, is much simpler. IDs are passed along as flowfile attributes, so downstream stages no longer need to rebuild the context for re-scoping the source dataset.
Customizing Ingest is easier. You do not need to understand how the default documents were constructed. For general customization of any indexing document, all that is needed is to tag on to the end of our default pipeline, and perform the required custom changes before sending to Elasticsearch.
URL index enhancements
- New page index
- The default URL Index, used by the eSite indexing model, includes all products, categories and pages. Most of this information is duplicated in the Product index and Category index. As a result, the URL index is very large and can take a long time to process and synchronize.
- New page stage
- In the eSite indexing model, URL indexing includes three stages that
process products, categories, and pages. In the Asset Store model these
stages are replaced by one Page stage, which processes all three types
together. This greatly simplifies indexing process and improves
performance.
- URL Query service
- A site level flag in the Query service indicates which index model is
being used. At runtime, the URL Query service queries the Page index to
fetch the page template and then queries the Product index or Category
index to retrieve information needed to populate the template. If there
is a long description token in the page template, the URL Query service
also queries the Description index for long descriptions of products or
categories.
The URL Query service then calls the Transaction server for page layout information.
There is a separate profile for the Asset Store index model. The profile can define different classes of provider, pre- and post-processors for the Asset Store index model. In this way, the same Query service process can be used to support both index models.
Near-Realtime (NRT) enhancements
- Reduce number of flows
- In the eSite Store index model, each eSite and language combination
generates an NRT flow. Therefore, the number of flows equals the number
of eSites times the number of languages. When more than a few languages
are being indexed, indexing time increases by a substantial amount.
In the Asset Store index model only one flow builds all eSite stores and all languages. This results in a substantial performance improvement over the eSite model.
- Category hierarchy
- When you change the parent of a category, the category hierarchy is
rebuilt. In the eSite Store model, all category hierarchies are updated,
even if only one category is reparented.
In the Asset Store index model, only the hierarchy of the parent categories, the category that is reparented, and its sub-categories are updated. As a result, fewer updates are sent to the Elasticsearch server.
- No need to update the URL Index
- When you change products or categories under the eSite Store model, the URL index for these products or categories is rebuilt. In total there are six URL index-related stages.
Easy performance tuning
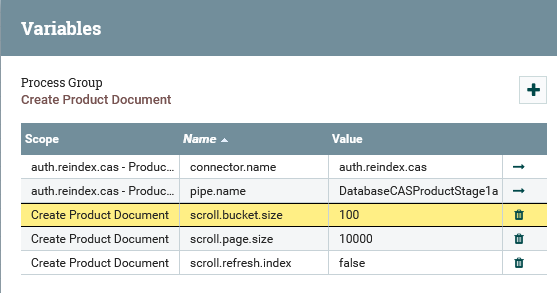
The number of catalog entries in each flow file is controlled by the
scroll.bucket.size variable in stage auth.reindex.cas - Product Stage 1a
(Main Document). You can set a value between 100
and 1000, depending on the size of the catalog. If catalog size
is big, then set the scroll.bucket.size to a smaller number, such as 200.
In addition, the scroll.page.size variable can also be set to a
smaller number, such as 10000.
If you find there are many flows stuck in a particular stage, you can increase the number in the Concurrent Tasks field of the Scheduling tab of the Configure Processor window, and the Max Total Connections under the Properties tab of the Database Connection Pool.


Limitations
- Language Fallback
- Language fallback is not currently supported in the Catalog Asset Store index model. The default value of the flow.language.fallback parameter is "true", and this remains unchanged when you activate CAS despite the limitation. You can leave it set to "true." For more information on how to set flow.language.fallback and related parameters, see Ingest configuration via REST.