Extending the Ingest service
The Version 9.1 HCL Commerce Search service includes Ingest and Elasticsearch, which together form a distributed, scalable search and analytics engine. You can chain together the Ingest service's rule-based aggregations to boost relevancy for hero SKUs or certain facets, and use sophisticated metrics to analyze your search performance.
HCL Commerce Search provides real-time search and analytics. As a distributed document store that uses both structured and unstructued data, it can be used for many purposes in addition to site searches. In HCL Commerce, the primary client for Ingest is the Elasticsearch high-performance search system. Ingest itself uses a configurable technology called NiFi, and its custom connector pipes.
Indexing dataflow
The indexing pipeline consists of a main flow, where data that the Ingest service knows how to extract moves in a linear way from input to output; and an ETL side-flow, which has several stages whose behavior you can customize. The following diagram shows the design model for the system.
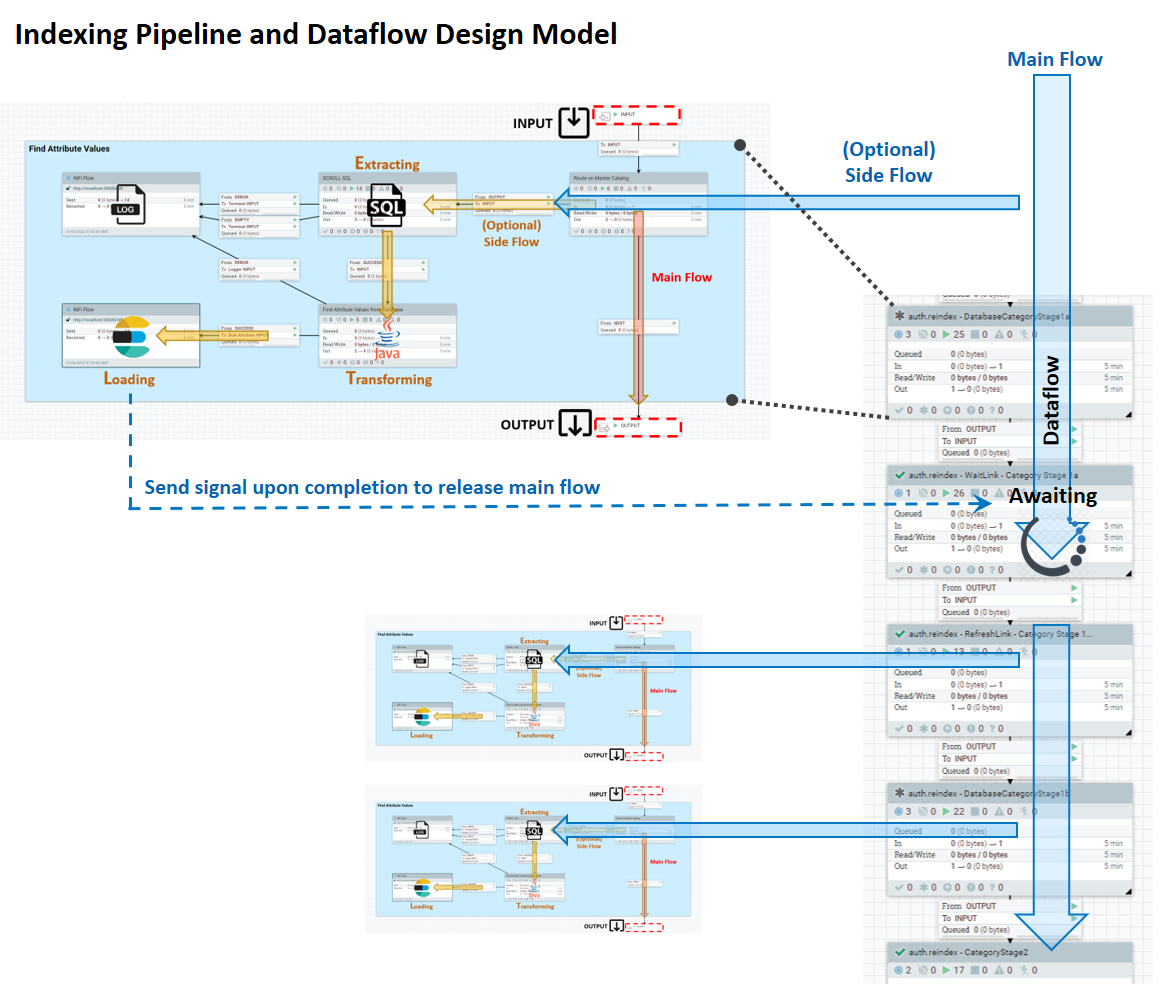
- INPUT: input port from prior success flow
- MAIN: ETL processing logic, for example:
- Read from an external data store
- Process each data entry being read in
- Send one or more processed (indexing ready) data document to Elasticsearch
- OUTPUT – output port to next pipe.
A link connects one pipe to another pipe or pipeline. A frequently used link
is a WaitLink. This link pauses the dataflow until the current
stage has completed, with either a successful, partially successful, or failed
state.
A logging service is provided with Ingest for tracking messages and statuses of individual pipe as data flows through the system.
Deploying NiFi customizations
You can extend the default dataflow by creating a new connector or modifying an existing default connector to include custom pipes. These can later be stored and versioned into a separate custom NiFi Registry.
You create custom connector pipes (also referred to as NiFi Process Groups) within your development environment. These pipes can be tested in a local NiFi, or an integrated Commerce development and test environment. Once your custom pipes are ready, they can be promoted to higher environments for further testing and deployment. To learn how to make your own connectors, see Creating a NiFi service connector.
Use a separate source version control system as the master repository for maintaining your own custom pipes. The NiFi Registry is only used to coordinate the release of versions to the pipeline that are in operation, and cannot be used as a permanent storage of custom connector pipes.
Elasticsearch clusters in HCL Commerce
- Master node
- The master node is chosen automatically by the cluster, and controls its behaviour. If a master node goes down, the cluster will elect another in its place. Master nodes are mandatory in Elasticsearch clusters.
- Data nodes
- These nodes contain business data, and use Apache Lucene to perform Create, Read, Update and Delete operations on the data. Data nodes recognize two types of data, hot and warm; hot, or frequently used data is cached, preferably in an SSD environment.
- Coordinating node
- Coordinating nodes transfer search results between the data nodes.
- Ingest nodes
- HCL Commerce Search with Elasticsearch uses Apache NIFI nodes as an intake pipeline. This pipeline transforms and enriches incoming documents before they are indexed. It has a persistent queue for guaranteed delivery.
Indexes and shards
The Elasticsearch index is a logical namespace that maps to instances of the Apache Lucene search engine running inside the data nodes. The Elasticsearch index is similar in function to a table in a relational database. For a complete description of the Elasticsearch index fields, see Elasticsearch index field types.
The Lucene engines are known as shards. The HCL Commerce implementation of Elasticsearch uses two kinds of shard: a primary shard that can perform both read and write operations, and replica shards that are optimized for read operations only.