Ingest Service
The Ingest service is responsible for bringing data into HCL Commerce Search. This data, which can be in many different formats, is passed to Apache NiFi, which prepares it for use by Elasticsearch. To administer the Ingest service, you define a data specification to write NiFi descriptors. Each descriptor defines the behavior of a particular connector. Strung together, the connectors manage the data pipeline and that builds your index.
Pipelines
A pipe is a NiFi process group that contains a NiFi input port, a flow made up of a series of NiFi processors, and an output port. Input and output ports can only receive and send, but the NiFi processors they report to can also read and write to the search index, or other persistent data repositories. The process group is stored in a NiFi registry, which is version-managed.
A NiFi pipeline is made up of the total set of NiFi pipes responsible for bringing in a particular type of data. Each default connector pipe uses a boiler-plate template that contains the following ETL (Extraction, Transformation, and Loading ) data ingestion pattern:
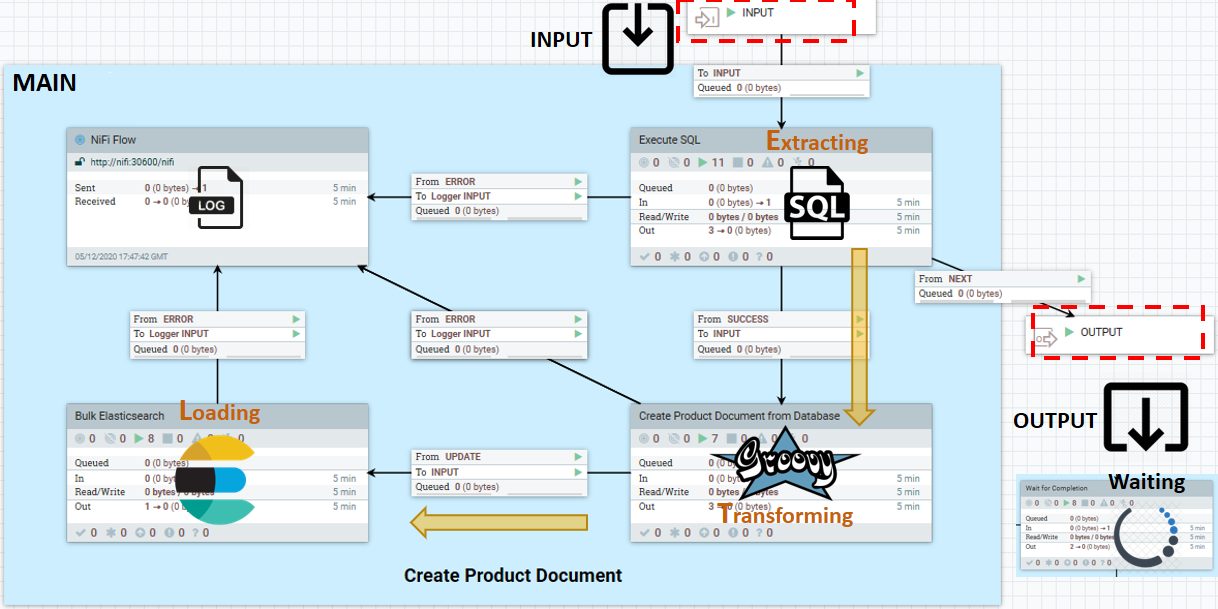
- INPUT
- The port that listens for signals from prior processor successes. Only send trigger signals through this and the output port. Business data should be read in, processed, and written to external data repositories from inside the pipe. This policy prevents dependencies between the pipes.
- MAIN
- ETL processing logic. SQL extraction and transformation is typically
performed using Java. The Groovy ETL is only supported in development
environments. The main component can be anything, however, including
- Read from an external data store
- Process each data entry being read in
- Send one or more processed data document to Elasticsearch
- Wait until entire source data set has been exhausted
- OUTPUT
- Output port used to send a trigger signaling success to downstream pipes.
WaitLink connects one pipe to another pipe or pipeline. It pauses the dataflow until the completion (success, partially successful, or failed) ofthe current stage.
Do not modify these default NiFi process groups or the source code included for reference.
A logging service is provided with the Ingest service. You can use this to track messages and statuses of individual pipes as data flows through the system.
Connectors
A connector is a dataflow pipeline or set of pipelines (NiFi process groups and their connections) that perform data ingestion and transformation tasks to ready the data for the search index. Connectors provide the business and data lifecycle context to pipelines of connected process groups in NiFi. Some examples of the connector context include the data lifecycle (product, category, etc.), whether the dataflow is intended for the live or authoring environment, or whether it is used in near-realtime or full reindexing.
There are master connectors that can build an index (in the case of auth.reindex and live.reindex). Connectors are to be defined as a connector descriptor, created using the Ingest service API and stored in ZooKeeper.
 Note: From Version 9.1.10 on, the Ingest
service automatically synchronizes NiFi with your custom connector descriptors
stored in Zookeeper. The default connector descriptors from earlier releases,
previously stored inside of Zookeeper are no longer needed, except those that are
customized. You maintain your own copy inside of Zookeeper. For more information,
see Release changes to the Ingest service.
Note: From Version 9.1.10 on, the Ingest
service automatically synchronizes NiFi with your custom connector descriptors
stored in Zookeeper. The default connector descriptors from earlier releases,
previously stored inside of Zookeeper are no longer needed, except those that are
customized. You maintain your own copy inside of Zookeeper. For more information,
see Release changes to the Ingest service.http://ElasticSearchhostname:30600/nifi/For more information about using NiFi, see the Apache NiFi User Guide.
Processors
NiFi Processors are the basic building blocks of dataflow pipelines. Processors
perform specific tasks within the pipeline, such as listening for incoming data;
pulling data from external sources; publishing data to external sources; and
routing, transforming, or extracting information from FlowFiles. Processors are
grouped into process groups and connected together to form dataflow
pipelines. Dataflow pipelines are in turn grouped together and given context by
connectors. A special NiFi processor, such as a "link processor" may provide flow
control in a pipeline. For example, a frequently used link processor is a "WaitLink"
that pauses the dataflow until the current stage has completed, with a status of
success, partially successful, or
failed, before allowing transmission of data to the next
process group in the dataflow pipeline.
Process group
A NiFi process group is a network of NiFi processors where each processor is only responsible for processing one simple task. These processors are connected together to manage a more complicated operation. Process groups are further connected, and may be nested, inside NiFi to form dataflow pipelines. As with processors, data enters a process group with one state and comes out of it with another state. Processors and process groups themselves are stateless. NiFi process groups and their connections (represented in JSON as "flows" stored and organized in "buckets") are versioned and maintained in the NiFi Registry.
Data specifications
Each Apache NiFi specification defines the data type and structure of an input document. If you want to build a NiFi pipeline, you generally start with the specification. NiFi natively supports hundreds of different specifications. If one already exists you may be able to use it without modification. If you want to customize your pipeline, NiFi provides a powerful toolkit, including an API that allows you to define your own specifications.