Performance tuning the Ingest service
You can tune search performance at data ingest time by adjusting your NiFi settings, or at runtime by changing the memory options for Elasticsearch.
Tuning Apache NiFi
To maximize performance, NiFi divides incoming data using a zero-master clustering approach. Data is divided into chunks and each node in the cluster performs the same operation on the chunk it receives. ZooKeeper elects one node as the Cluster Coordinator, and all other nodes send heartbeat data to it. The Coordinator is responsible for disconnecting nodes that do not report on time, or connecting new nodes that prove they have the same configuration as the other nodes in the cluster.
| Setting | Description | Default | Range/options |
|---|---|---|---|
| Memory (Bootstrap.conf file settings) | |||
| JVM memory | Minimum and maximum heap memory. note that a very large heap may slow down garbage collection. | 512mb | Set to 4 to 8 Gb, for example:
|
| Garbage collector: XX:+UseG1GC | Java 8 has issues when using the recommended
writeAheadProvenance implementation
introduced in Apache NIFi 1.2.0 (HDF 3.0.0). |
||
| Java 8 or later (nifi.properties file settings) | |||
| XX:ReservedCodeCacheSize | NiFi stores its data on disk while processing it. Under conditions of high throughput the default CodeCache settings may prove inadequate. | Varies according to Java version; can be as low as 32mb | 256Mb |
| XX:CodeCacheMinimumFreeSpace | Uncomment in nifi.properties to use. | 10mb | |
| XX:+UseCodeCacheFlushing | Sets threshold for flushing cache. | ||
| Filesystem storage for NiFi internal repositories | |||
| Flow file | |||
| Database | |||
| Content | |||
| Provenance | |||
| Tuning (per NiFi node) | |||
| Threads | Number of threads for timer driven threads. Do not use event-driven threads. | 2 to 4 times number of cores on host | |
Tuning Elasticsearch
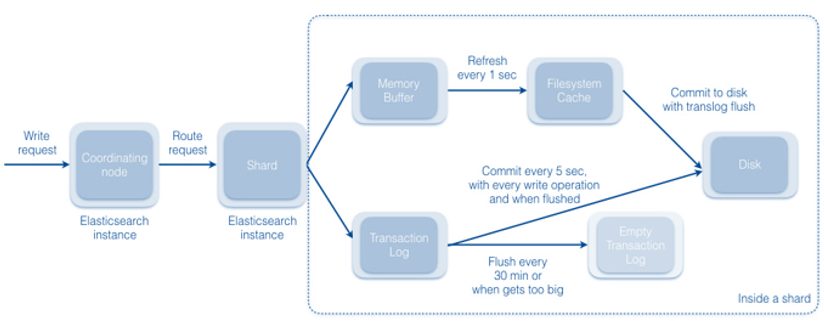
Elasticsearch uses the same zero-master clusering approach as NiFi. The coordinating node receives write requests and allocates routing requests to other cluster instances (shards). By default each shard refreshes its filesystem cache once per second and commits every five seconds. The shard keeps a transaction log and flushes the log every thirty minutes.
In the query phase of the search process, the coordinating node takes incoming searches and sends them to all the shards. Each shard performs its own search, locally. The shard prioritizes the results and returns information about the top fifty documents to the coordinating node. In the fetch phase the coordinating node determines the top ten documents from each shard's list, and requests that each shard send it those documents.
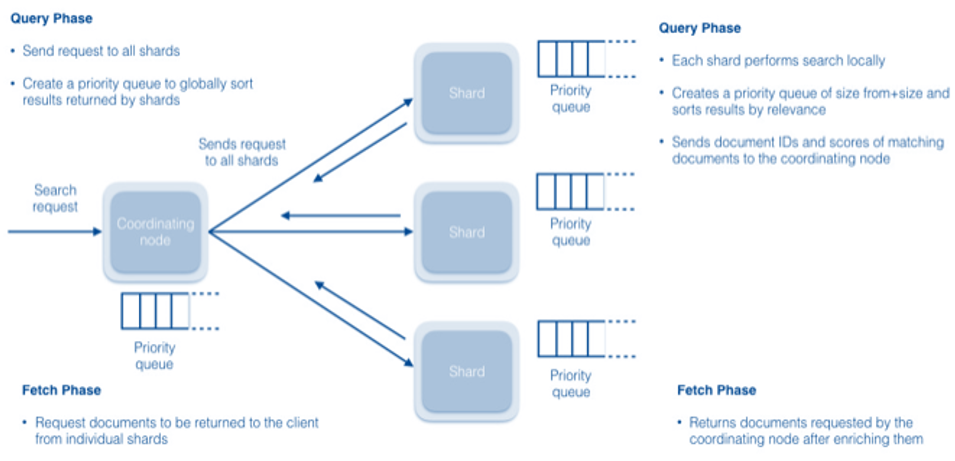
The query phase will usually take significantly longer than the fetch phase, because during Query the shards have to match the search to a potentially long list of documents, and determine a score for each. In contrast, the fetch can complete quickly because the coordinating server requests a subset of the documents using direct addresses.
The primary way of improving Elasticsearch performance is to increase the refresh interval. When you do this, Elasticsearch will create a new Lucene segment and merge it later, increasing the total segment count. In addition, avoid swapping if at all possible. Set bootstrap.memory_lock=true to facilitate this.
Adjust the following specific settings to improve optimize Elasticsearch working environment.
| Setting | Description | Default | Range/options |
|---|---|---|---|
| Memory | |||
| JVM heap | Minimum and maximum heap memory. |
|
|
| Garbage collector | XX:+UseG1GC | Use the Java 8 Garbage First collector for heap sizes below 4 GB. | |
| Index buffer size | 10% of heap size. | ||
| Filesystem cache |
|
50% of Elasticsearch memory size | |
| LRU cache | |||
| Node query cache | Set with indices.queries.cache.size parameter | 10% of heap size | |
| Shar query cache | Used for aggregation | ||
| Field data cache | Set with indices.fielddata.cache.size parameter | Limited to 30% of heap size | |
| General settings | |||
| Threadpool | generic, index, get, bulk |
||