Using the HCL Commerce Search service
With HCL Commerce Version 9.1, HCL Commerce introduces a new service for inputting and organizing your data. This new version of HCL Commerce Search is a generic data management system that can be used by other Commerce subsystems, including but not limited to the Elasticsearch engine. Along with the Ingest service that brings in the data, the new Query service provides natural language processing, color recognition and more. For customers who need backwards-compatibility, the previous Apache Solr-based search solution is still available.
The HCL Commerce Search service introduced in HCL Commerce Version 9.1 provides you with improved scaling, simpler administration, and enhanced security. This architecture includes Elasticsearch as the preferred HCL Commerce Version 9.1 Search microservice. HCL Commerce HCL Commerce Version 9.1 search system is backwards-compatible with the one present in HCL Commerce Version 9.0. The search API remains the same regardless of whether you are using Solr or Elasticsearch, which means that most implementations will be able to switch to Elasticsearch with no impact on the storefront. If you have previously customized the indexing configuration or templates, or the Search runtime, then you may need to migrate your customizations.
- Natural language processing (NLP) with Stanford CoreNLP. The NLP system improves search relevance, with models provided for English, Spanish, French, German, Arabic, and Chinese.
- Most CoreNLP language models are capable of performing tokenization, lemmatization, part-of-speech tagging, name-entity-recognition, sentence splitting, and sentiment analysis. They can perform grammatical analysis with constituency, dependency parsing, and coreference.
- An additional NLP processor has been added to provide additional Matchmaking capabilities such as finding similar colors or measurements, and automatic measurement conversion.
- Fully integrated with Elasticsearch as the default core search technology.
- Enhanced multilingual support with over 30 built-in language-specific analyzers for text analysis such as tokenization, stemming, stop words.
- Dynamic index shards allow more nodes to be dynamically added and rebalance data automatically across the cluster with zero downtime.
- Hot-swapping of newly-built indexes using index aliases. Re-indexing has minimal impact on your live index cluster.
- Fast incremental snapshots, which allow you to backup at frequent intervals.
- Data ingestion through indexing pipelines in Apache NiFi.
- The HCL Commerce Search service fully supports multitier marketing and features near-realtime updates.
- Kubernetes-ready deployment interface.
- Seamless service upgrade and version control. Seamless service container upgrade allows new features and bug fixes to be delivered continuously through recurring service packs.
The Docker container stack that runs the microservices is hosted on UBI 8.8, and uses the Spring Boot framework.
The following diagram shows the architecture of HCL Commerce Search. The microservices in the main box were inside the monolithic Search container in HCL Commerce Version 9.0. These services have now been broken out into their own containers and communicate via the Data Environment.
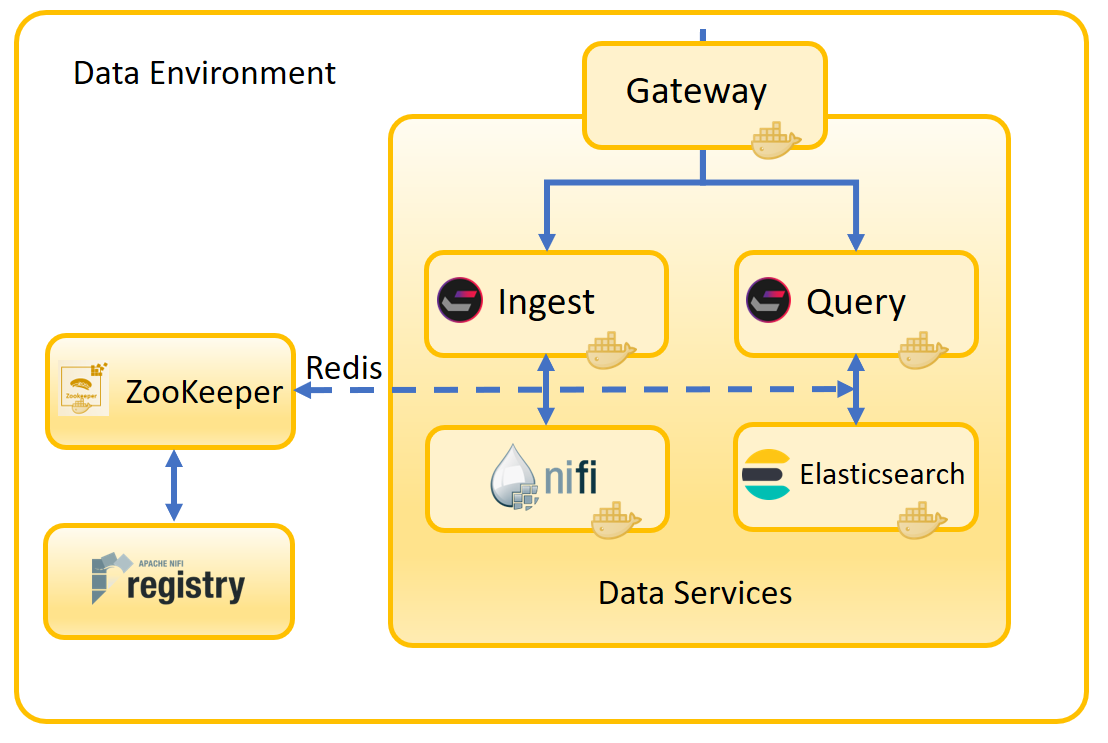
The components of HCL Commerce Search are:
- The Ingest service
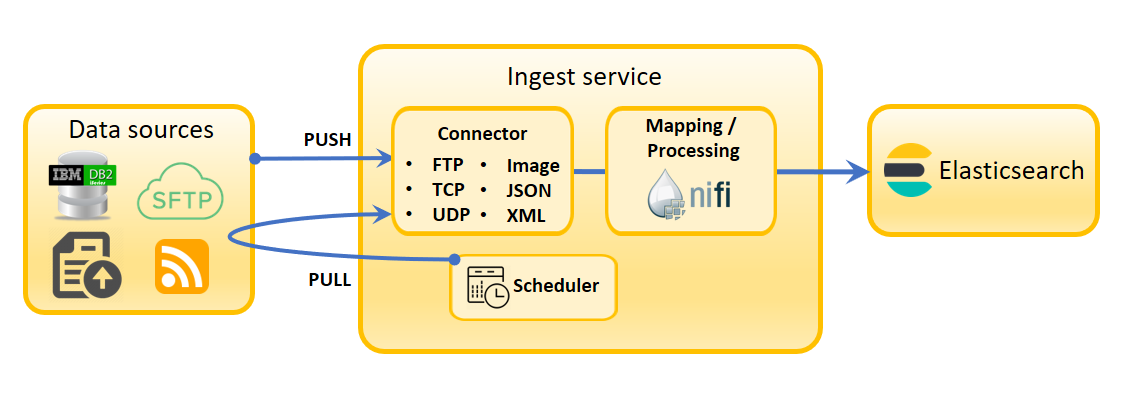
- This microsesrvice manages write operations. It performs the essential Extraction, Transformation and Loading (ETL) operations on business data that make them available to the search index. The business logic behind the indexing lifecycle, which previously resided in the Transaction server, now is managed here.
- The Query service
- The Query service builds the search expressions and then hands the expression to Elasticsearch. It also takes the query results and translates them back into a form that can be used by the storefront. The storefront does not need to know that the response was generated by Elasticsearch rather than Solr.
- Apache NiFi
- NiFi is the indexing pipeline used by the Ingest service. It uses connectors to bring in raw data and convert it into a form that can be used by Elasticsearch. You can use the default NiFi connectors for known data types, or define your own so that NiFi can bring in custom data types. NiFi runs in its own container and is fully extensible.
- Elasticsearch
- The Query service and search profile determine the best way to handle the search query. Elasticsearch uses its high-performance engine to run the search, and then the response is filtered back through the search profile before being handed back to the storefront. Using the search profile to filter the response means that the storefront does not need to know that it is interfacing with Elasticsearch instead of Solr.
- Redis
- Redis is used as the message bus for distributing change events as well as cache invalidation events. For more information, see the Redis project site.
- ZooKeeper
- ZooKeeper is used to store your default and custom configurations, connector descriptors along with custom properties and extensions. It starts with your search profile and Ingest profile already present.
You can use the preconfigured helm charts that come with Version 9.1 to deploy a complete, preconfigured search stack. By editing your own helm charts you can use Kubernetes to deploy a system appropriate to your own business needs.