
Ingest endpoint for updating the tuning parameters in NiFi
You can use a REST API endpoint to upgrade, analyze and reassign the tuning values in individual NiFi pipelines. This endpoint is described and examples given of connecting to it using the Swagger interface.
The following Ingest endpoint is intended specifically for updating tuning parameters in NiFi. It provides an upgrade-friendly configuration target for your NiFi tuning parameters. Using this API you can analyze historical Ingest data, calculate new tuning values and assign new tuning values to the appropriate ingest pipelines.
Calling the API
/connectors/connectorName/pipes/pipeName- connectorName
- This value corresponds to the pipeline name for the pipeline you are targeting.
- pipeName
- This value corresponds to the pipe/ stage name. In the NiFi interface, these look similar to the following examples:
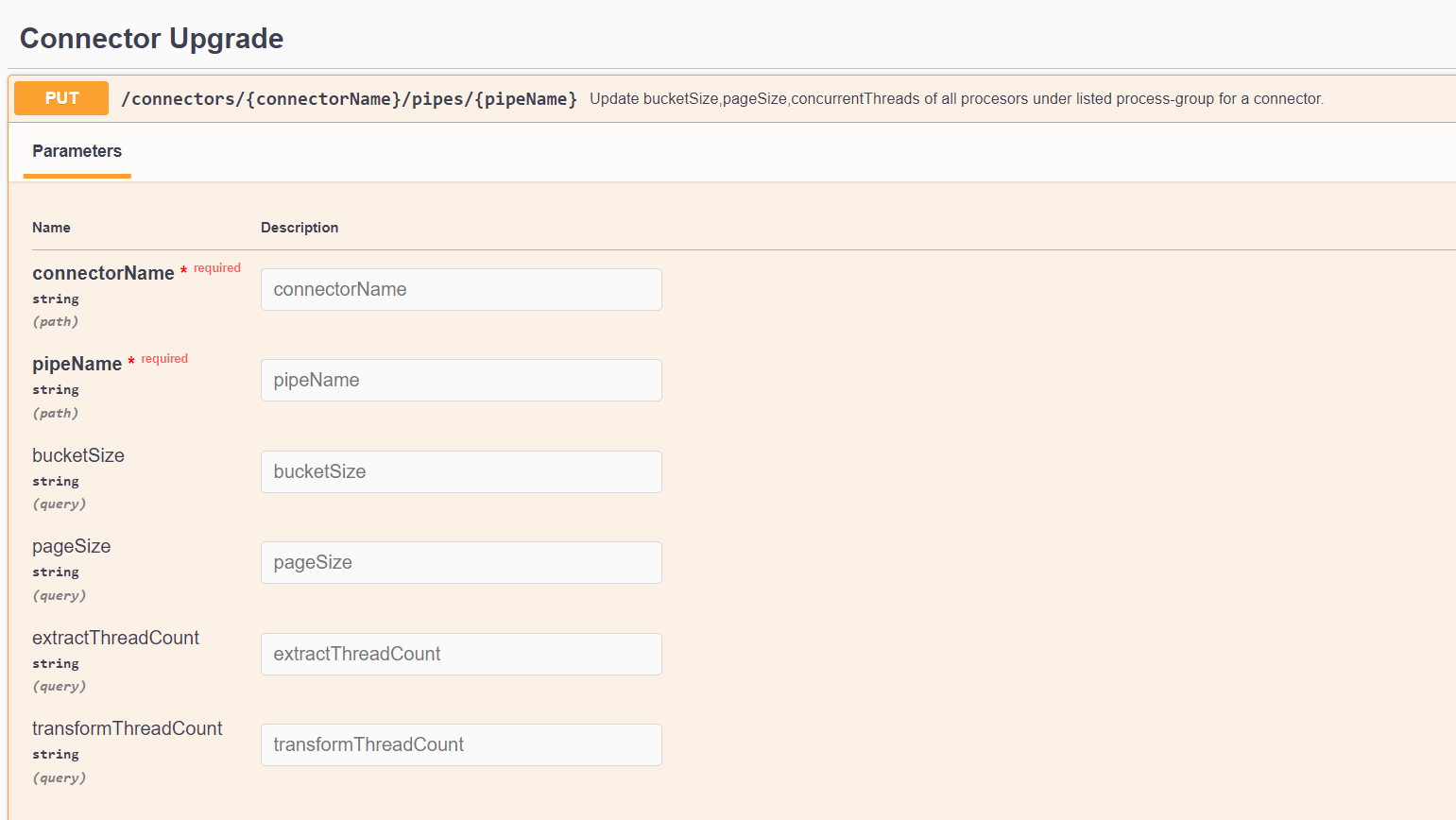
Use the same convention for connectorName and
pipeName used in NIFI-UI and NIFI-Registry, respectively.
For example, use connectorName as auth.reindex
for the reindex pipeline. Different pipelines have different names.
You can use the Swagger interface to call the Connector Upgrade API to tune any pipe in any of the pipeline having tunable parameters.
This is dataload.category pipeline so use the
connectorName as dataload.category.
Examples of pipe/ stage name:
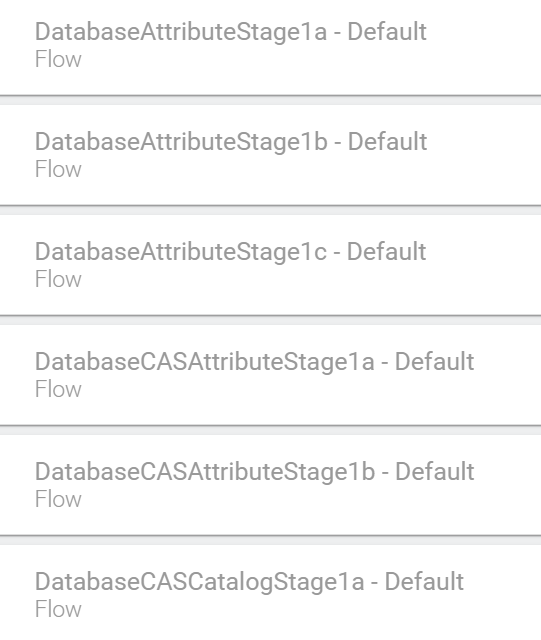
This API works only when the connector contains that stage or when there is no
spelling mistake, and the convention is correct. Otherwise, this would give an error
with status code 400. 
In the case of the CAS pipeline, use connectorName ending with
.cas, and accordingly, pipeName must
contain CAS in the pipe/ stage name. If it does not, it will change the name of the
stage name that you are calling.
For example, in the dataload.product.cas pipeline, if you want to
tune Product Stage 1g, use the pipeName as
DatabaseCASProductStage1g, not as
DatabaseCASProductStage1g else the request will change the
name of the stage in the .cas pipeline
If not, a 400 status code error would be displayed.
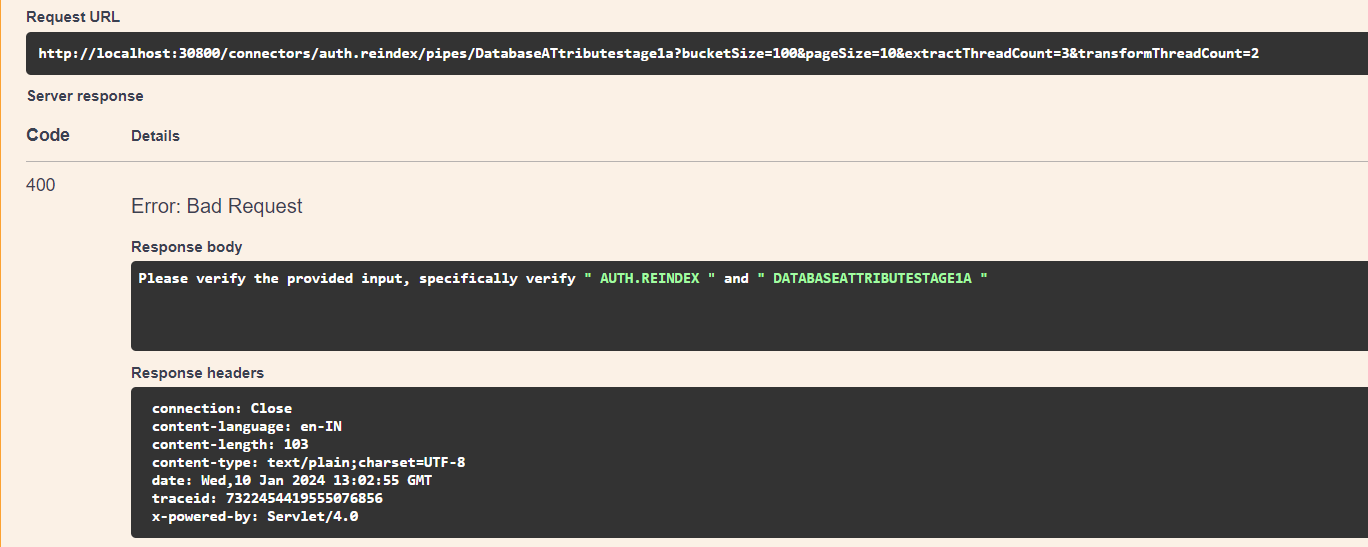
- Correct convention
-
If connectorName ends with
.cas, then the stage name should also end with.cas.
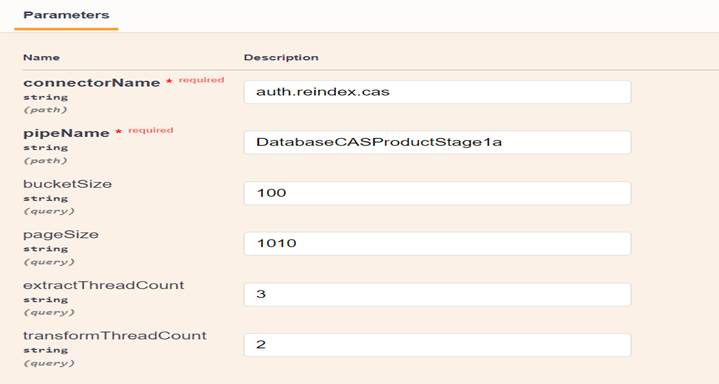
- In bucketSize, pageSize, extractThreadCount, and transformThreadCount, always use positive integral value for valid requests.
- In case of null value for extractThreadCount and transformThreadCount, then take the previously assigned value of thread count.
- Upon satisfying the above conditions, the request will be successful, the value will be changed in the NiFi user interface, and you will get status code 204.
- extractThreadCount is used for changing the concurrent task of the Execute SQL processor in the Execute and SCROLL SQL process group
- transformThreadCount is used for changing the concurrent task of the Transform Document processor in the Transform process group.
- Product stages 1a,1b,1e,1g,1h,1i (both)
- Attribute stages 1a,1b,1c (both)
- Catalog Stage 1a,1b (both)
- Category Stage 1a,1b,1c (both)
- Inventory Stage 1 (cas only)
- Page Stage 1 (cas only)
- Price stage 1a, 1b (both)
- URL stage 1a,1b,1c,1d,1e,1f (Esite only)
- Inventory Stage 1a,1b (both)
- CASSTA stage
- BULK SERVICES (BulkAttribute, BulkCatalog, BulkCategory, BulkDataload, BulkDescription, BulkInventory, BulkPrice, BulkProduct, BulkStore, BulkURL)
- How to customize to add more JSONs
- Create the JSON template by using the pre-existing JSON templates as an example. All four parameters should have the same name. Replace the stage name with the file name in the resources\deployments\tuningparameters folder.
- How to tune BULK SERVICE
-
connectorName should always be used as the basis for bulk service customization. Utilize the stageName that appears in the NiFi registry. Since bucket and page sizes are not available for bulk services, leave those fields empty (NULL). Additionally, the value of transformThreadCount is not necessary, therefore leave that field empty (NULL). Use extractThreadCount just to POST Bulk Elasticsearch to the same set value, examine bulk response, and alter concurrent tasks in Track Bulk request.
