
Elasticsearch with dedicated Auth and Live nodes
For production environments, Elasticsearch is recommended in a clustered configuration for high availability and scalability considerations.
An Elasticsearch cluster consists of nodes that have different node roles, including a master-eligible node, data node, ingest node, remote-eligible node and machine learning node. The master-eligible node is responsible for cluster-wide operation such as index creation and deletion, node tracking and shard allocation. It is crucial to have a stable Master node to maintain the cluster health.
In the default HCL Commerce Elasticsearch cluster implementation, all nodes have all the node roles. If one node is busy on data operations and under resource constraints while it also has the master role, it can affect the cluster health, which in turn impacts data availability. Elasticsearch in particular can demand high CPU usage in the Auth environment when doing ingest operations, which would adversely impact the data queries in the production environment.
With the default clustered deployment, Elasticsearch automatically distributes the primary and replica shards to the available nodes (pods). In an HCL Commerce deployment, with authoring and live configurations, ingest operations could create periods of heavy activity on Elasticsearch, that stress resources such as memory and CPU. If an Elasticsearch node hosts both authoring and live indices, ingest operations could impact query performance and affect the availability of the live storefront.
This documentation describes a sample configuration that defines dedicated Elasticsearch node groups for authoring and live. By separating authoring and live indices into two different node groups, we can prevent reindexing from impacting the live site.
Elasticsearch installation
To setup Elasticsearch with dedicated node groups, each group is installed as a separate Helm release. This enables the use of different configurations for each group. When each node group is started, they join a single Elasticsearch cluster.
The configuration presented here is a sample. You will need to adjust the node configurations such as memory and CPU, and the number of nodes to meet your requirements. Depending on your load requirements, you might need additional live nodes. You can also change the pod configurations to better match your available infrastructure.
The values files for each release are available here:
The installation is done using Helm:
helm repo add elastic https://helm.elastic.co
kubectl create ns elastic
helm install es-master elastic/elasticsearch -f master.yaml -n elastic --version 7
helm install es-auth elastic/elasticsearch -f auth.yaml -n elastic --version 7
helm install es-live elastic/elasticsearch -f live.yaml -n elastic --version 7Elasticsearch pods
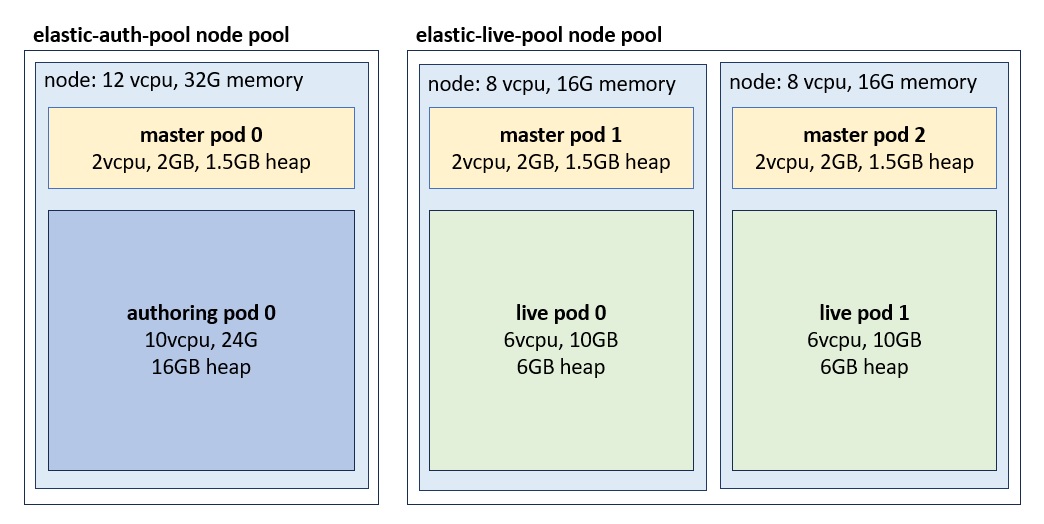
In Elasticsearch terminology, an Elasticsearch node refers to an instance of Elasticsearch. In Kubernetes, Elasticsearch nodes are deployed as stateful sets and run as pods. The sample deploys pods with the following configurations and limits:
| group | pods | vcpu | memory | heap |
|---|---|---|---|---|
| master | 3 | 2 | 2G | 1.5G |
| auth | 1 | 10 | 24G | 16G |
| live | 2 | 6 | 10G | 6G |
Kubernetes node groups
The Elasticsearch node groups, that are installed as separate Helm releases, can be configured with different node affinity rules. For example, Elasticsearch live nodes (pods) can be deployed within a particular Kubernetes node pool.
This sample from Google Cloud, defines affinity rules so the pods are only deployed within nodes that belong to the elastic-live-pool node pool:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.google.com/gke-nodepool
operator: In
values:
- elastic-live-poolWhile it is possible to deploy Auth and Live to the same node pool, using separate node pools has the avantage that each pool can be configured with different Kubernetes node characteristics. For example, the authoring node pool can be configured with a machine with more memory than the live pool.
The sample is deployed in Google Cloud (GKE) using the following node configurations:
| pools | nodes | vcpu | memory |
|---|---|---|---|
| elastic-auth-pool | 1 | 12 | 32G |
| elastic-live-pool | 2 | 8 | 16G |
If your cluster is not currently configured with multiple node pools, all other deployments must have affinity rules added, as otherwise they could deploy to any pool including the Elasticsearch pools. If a non-Elasticsearch pod (for example, Redis or Vault) deploys to the Elasticsearch node pools, the node might not be left with enough resources to start the Elasticsearch pods.
Master node groups
Besides the node groups for authoring and live, the sample configuration defines a group of dedicated master nodes. These nodes do not handle traffic or maintain indices. Instead, their only responsability is to manage the cluster state. In production environments, it is recommended to have dedicated master nodes, as data nodes might become overwhelmed and unresponsive, and this could lead to cluster state synchronization problems.
The dedicated master nodes typically require few resources. The sample configures the limits to 2 vcpu, memory to 2G and Java Heap to 1.5G. Monitoring should be used to confirm these resources are sufficient.
In our example, master nodes can run within either the elastic-auth-pool or the elastic-live-pool node pools:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.google.com/gke-nodepool
operator: In
values:
- elastic-auth-pool
- elastic-live-poolIndex affinity rules
The charts use lifecycle/postStart to automate required routing and
sharding configurations. index.routing.allocation.require.env must
match the node attribute node.attr.env configured in the same
chart. Authoring is configured with 1 shard and no replicas. Live is also configured
with 1 shard, but the number of replicas is configured to the number of nodes minus
one. This ensures all live nodes maintain copies of all indices. In the example
configuration, with two live nodes, one live node runs the primary shard, while the
other runs a replica shard. If your configuration runs with more live pods,
number_of_replicas must be updated.
- Authoring index configuration
- Index pattern configuration for authoring indexes:
{ "index_patterns": [".auth*", "auth*", "log", "nlp", "run","live*"], "settings": { "index.routing.allocation.require.env": "auth", "number_of_replicas": 0, "number_of_shards": 1 } }The inclusion of the
live*index pattern (as opposed to.live*which is used in the live group) is to include a set of indices that must be kept within the authoring group.The
live.master.*indices are copies of the production ready data which are kept within the authoring group, and are copied into the.live.*indices duringpush-to-live. Price and inventory data for the live environment is ingested into thelive.priceandlive.inventoryindices. These indices are copied into master indices and then propagated into the live environment.The
live.storeindex is used during ingest while the.live.store.yyyymmddHHmmindex is a copy kept within the live group. This allows ingest and live operations to remain available even if the other Elasticsearch node group is unreacheable. - Live index configuration
-
Index pattern configuration for live indexes:
{ "index_patterns": [".live*"], "settings": { "index.routing.allocation.require.env": "live", "number_of_replicas": 1, "number_of_shards": 1 } }
Configuring NiFi
Additional configurations are required for NiFi to support the dual node group setup. The following example uses curl to apply the configurations using the shard queryapp server:
curl -XPATCH -v -u spiuser:<password> 'localhost:30900/search/resources/api/v2/configuration?nodeName=ingest&envType=auth' -H 'Content-Type: application/json' -H 'Accept: application/json' -d@split.jsonsplit.json:
{
"global": {
"connector": [
{
"name": "attribute",
"property": [
{
"name": "flow.inventory.copy",
"value": "auth,live"
},
{
"name": "flow.price.copy",
"value": "auth"
},
{
"name": "alias.keep.backup",
"value": "0"
},
{
"name": "cluster.index.nodegroup",
"value": "dual"
}
]
}
]
}
}Connecting to Elasticsearch
Each Elasticsearch release generates its own set of services. While all the nodes can handle requests for any index, there is additional overhead if the node handling the request does not locally manage the index.
kubectl get services -n elastic
elasticsearch-auth ClusterIP 10.244.8.225 <none> 9200/TCP,9300/TCP 109m
elasticsearch-auth-headless ClusterIP None <none> 9200/TCP,9300/TCP 109m
elasticsearch-live ClusterIP 10.244.7.235 <none> 9200/TCP,9300/TCP 109m
elasticsearch-live-headless ClusterIP None <none> 9200/TCP,9300/TCP 109m
elasticsearch-master ClusterIP 10.244.6.29 <none> 9200/TCP,9300/TCP 109m
elasticsearch-master-headless ClusterIP None <none> 9200/TCP,9300/TCP 109mThe recommended configuration is to have the live servers use the live service
elasticsearch-live.elastic.svc.cluster.local, while the rest
can connect directly to the authoring node via the authoring service
(elasticsearch-auth.elastic.svc.cluster.local). The master
nodes do not own indices and should never be used to connect to the cluster.
To use this configuration in Vault, define the elasticSearchHost,
elasticSearchPort and elasticSearchScheme keys
under the "live" branch, referencing the live service.
svt/qa/live/elasticSearchHost value="elasticsearch-live.elastic.svc.cluster.local"
svt/qa/live/elasticSearchPort value="9200"
svt/qa/live/elasticSearchScheme value="http"The authoring service is referenced under the environment level. It is used when not running in live:
svt/qa/elasticSearchHost value="elasticsearch-auth.elastic.svc.cluster.local"Validating the environment
Once the installation of all the helm releases is complete (es-master, es-auth and
es-live) and the statefulsets are started, all pods should form a single
Elasticsearch cluster. This can be validated by executing the
/_cat/nodes API as follows:
curl "localhost:9200/_cat/nodes?v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
1.1.1.0 12 89 0 0.06 0.11 0.10 m - elasticsearch-master-0
1.1.1.1 37 89 0 0.02 0.11 0.17 m - elasticsearch-master-1
1.1.1.2 43 90 0 0.00 0.14 0.14 m * elasticsearch-master-2
1.1.2.0 7 73 0 0.00 0.14 0.14 cdfhirstw - elasticsearch-auth-0
1.1.3.0 21 56 0 0.06 0.11 0.10 cdfhirstw - elasticsearch-live-0
1.1.3.1 13 56 0 0.66 1.13 0.71 cdfhirstw - elasticsearch-live-1After reindexing is complete, use the _cat/indices API to verify the
indices' health is 'green.' If the primary shard cannot be allocated, the index
health will be 'red'. If a replica shard is not allocated, the index health is
'yellow'. If there are indices that are not green, there could be a problem with the
Elasticsearch or NiFi configurations. The Elasticsearch Cluster allocation explain API can
describe reasons why the cluster is unable to allocate a shard.
curl "localhost:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .auth.12001.attribute.202312012227 R-Te5iRhS1CFXY0OZv0wKg 1 0 43 0 44.1kb 44.1kb
green open .auth.12001.catalog.202312012227 MAkWPxKhSfyHuxyEqFkFRA 1 0 3 0 10.5kb 10.5kb
green open .auth.12001.category.202312012227 HOoMtbyVRt6Ow8FPPUco6Q 1 0 54 0 70.7kb 70.7kb
green open .auth.12001.description.202312012227 JWGHyUevTaK8vszHvBfVUg 1 0 327 0 106.9kb 106.9kb
green open .auth.12001.page.202312012227 EOZXi76ITeiQdC3iUFXmog 1 0 10 0 13.4kb 13.4kb
...Similarly, the /_cat/shards API shows the nodes on which each index
is allocated. This is used to verify that the affinity for Auth and Live indices is
working correctly.
curl "localhost:9200/_cat/shards?v"
index shard prirep state docs store ip node
.auth.12001.category.202312051630 0 p STARTED 928 1.3mb 1.1.1.1 elasticsearch-auth-0
.auth.12001.description.202312051630 0 p STARTED 697064 494.7mb 1.1.1.1 elasticsearch-auth-0
...
.live.12001.category.202312011848 0 r STARTED 928 1.3mb 1.1.2.0 elasticsearch-live-0
.live.12001.category.202312011848 0 p STARTED 928 1.3mb 1.1.2.1 elasticsearch-live-1
.live.12001.description.202312011848 0 r STARTED 697064 508mb 1.1.2.0 elasticsearch-live-0
.live.12001.description.202312011848 0 p STARTED 697064 508mb 1.1.2.1 elasticsearch-live-1
...