
Elasticsearch performance tuning
You have numerous options when tuning the performance of NiFi and Elasticsearch. The following guide introduces tools for monitoring performance and validating key tuning parameters, and provides a performance tuning strategy that you can use with the component.
The NiFi and Elasticsearch component may be perceived as relatively slow in processing speed. This may appear to be the case if you are testing the default configuration, which has not been modified or tuned to improve processing performance. This default configuration includes a mostly single threaded configuration of NiFi, and a minimal configuration of the Elasticsearch cluster. This setup can result in performance issues when building the search index. However, the performance of the solution is not only due to the default configuration.
It is also important to choose an optimal hardware configuration when testing. While CPU and memory resources are not critical, the I/O bandwidth of the disk subsystem on the Elasticsearch cluster emerges as a critical factor. Thus, careful selection of the environment from the start can avoid several simple performance pitfalls.
- A minimal configuration, that is applicable for use with a minimal hardware specification, and
- A recommended configuration, that should be applied on the recommended hardware specification.
Background information
Multiple factors influence the performance of the search index build, including hardware footprint, catalog size, and attribute dictionary richness. Understanding the bottlenecks and how they express themselves across the whole process is crucial to fine-tuning the search solution.
- Data retrieval.
- Data processing or Transformation.
- Data uploading.
- Retrieving data group
- Fetch data from database or Elasticsearch.
- Processing data group
- For the fetched data: build, update, or copy the index documents.
- Uploading data group
- Upload the index document to Elasticsearch.
Each group has an influence on the index building process's speed and efficiency. The retrieving data group, for example, would be in control of the flow file size (bucket size) and query execution frequency (scroll page size). You can optimise the payload and retrieval cost from the database, as the chunk of data NiFi processes as a unit, by altering these variables. The size of the flow file affects Elasticsearch upload performance. Complicated and large structures can take longer time for Elasticsearch to parse, resulting in poor scalability.
The processing data group controls the amount of work NiFi can do. For example, you can regulate how many flow files may be processed concurrently by controlling the processor's thread count. This increases the processing speed of a typical processor, potentially improving flow file pileup in front of the processor. The NLP processor, for example, is a typical processor that benefits significantly from additional threads. You can control how many connections to Elasticsearch you make concurrently using the more specialised bulk update type processor, allowing you to import more data to Elasticsearch.
These scenarios will be examined in further detail in Interpreting patterns and tuning search solution, using real-world examples and data.
Infrastructure requirements
HCL Commerce's infrastructure requirements are well defined, and while NiFi and Elasticsearch may function on a reduced footprint, performance may suffer if you reduce their resource allocation. Good I/O bandwidth is necessary for both NiFi and Elasticsearch infrastructures, enough memory for Java heap and Java native memory allocation, and preferably, enough memory for file caching. The latter may need to be specified in the pod since it ensures that the operating system has enough additional RAM for the service.
Key Tunable Variables
The following key tunable variables can be adjusted to improve overall processing time:
Processor thread count (Concurrent Tasks)
The default processor runs a single thread at a time, processing one flow file at a time. If concurrent processing is desired, the number of concurrent tasks that it can do can be adjusted. Set the number of threads for the process group by changing the processor Concurrent Tasks value (under Processor configuration or SCHEDULING tab).
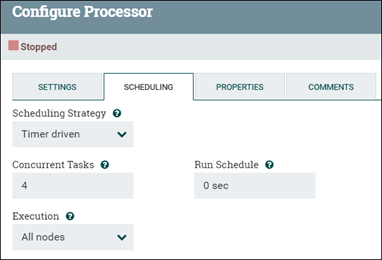
Throughput can be improved if a CPU is able to multitask by increasing the number of threads it employs. Two such examples are the transformation processor (as in NLP) and the Bulk update processor (sends data to Elasticsearch). This update does not help every processor. Most processors come with an default configuration that takes this variable into account and does not need to be altered. When performance testing reveals a bottleneck in front of the processors, the default configuration may benefit from further tuning.
When the processor can process flow files at the same rate as they come, the Concurrent Tasks value is ideal, preventing large pileups of flow files in the processor's wait queue. Because such a balance may not always be feasible, the best configuration focuses on reducing the flow file pileup in the waiting queue.