Natural Language Processing (NLP) in Version 9.1
The HCL Commerce Search service uses an extended version of the Stanford CoreNLP Natural Language Processor. In addition to part-of-speech tagging and other Stanford NLP features, HCL Commerce Search provides a range filter, units of measure and colors. It also supports stemming (plural-to-singular translation).

HCL Commerce Search uses the powerful Stanford CoreNLP language parser. By default, the CoreNLP toolkit provides multilingual support, full grammatical parsing, and extensibility. The enhancements provided by HCL Commerce Search specifically target the needs of online shoppers, giving greater responsiveness and intelligence to the search system.
Ranges and units of measure
Shoppers often want to find products within particular price ranges. If you search in the Aurora Sample Store for shoes over 200, the results will differ depending on whether you are using the Solr search system or the new HCL Commerce Search Query service. Using Solr, the search will return something like the following result (47 matches):
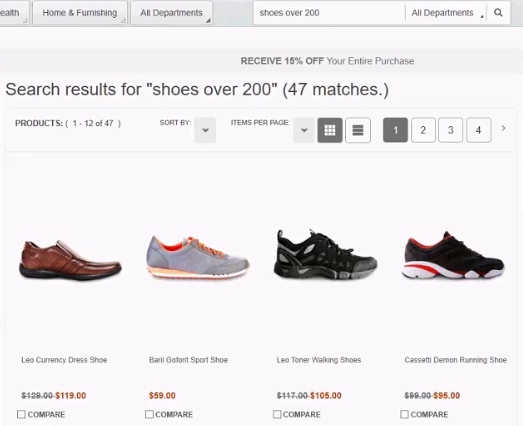
If you do the same search using the HCL Commerce Search Query service, something like the following result (2 matches) will be returned:
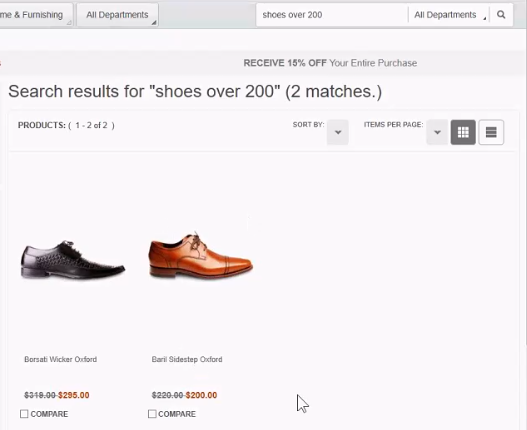
The NLP processor is even more flexible than this, however. If you choose a range, for instance using the search string show me shoes from 50 to 60, the system returns something like:
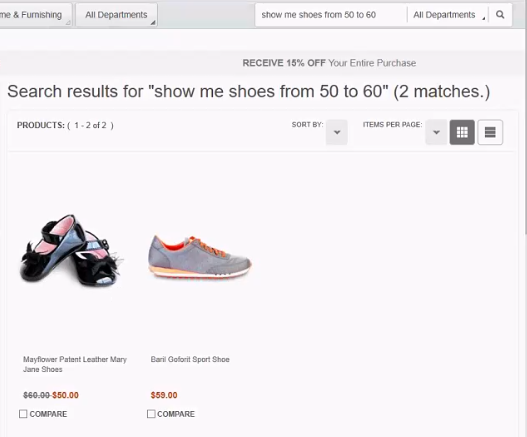
Constructions such as "more than" or "less than," "under," "over," or "from" are easily interpreted by the processor. The actual terms are defined in the Query REST API. You can configure special terms; an example that comes preconfigured is the term "expensive." By default this is set as $100, and the word "cheap" is set at <$50. This means the customer can search using "show me cheap shoes" and will only see results that are under $50 in price.
The NLP processor also understands units of measure. Products in the catalog can be measured in lbs, meters, grams, etc., and searches for quantities (such as foodstuffs or lengths of cloth) will restrict the products returned to those measures.
Matchmakers
The CoreNLP system has also been extended with matchmakers. There are two kinds of matchmakers at present: a color matchmaker, measurement/dimension matchmaker .
The color matchmaker lets you search within color families and not just colors. For example, if you search for the color ivory using the Solr search engine in the Aurora storefront, you might return something like the following:
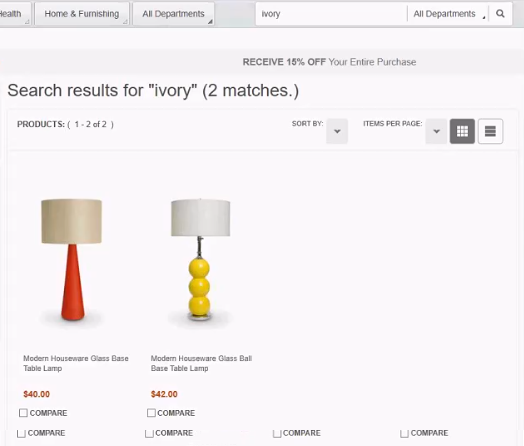
This search returned exactly two items. Both are returned because they explicitly defined in a facet field of the catalog as being "ivory" in color. In other words, searching on colors works, but only when colors are explicitly defined and only for exact matches.
When doing the same search using the HCL Commerce Search Query service, a different result is returned:
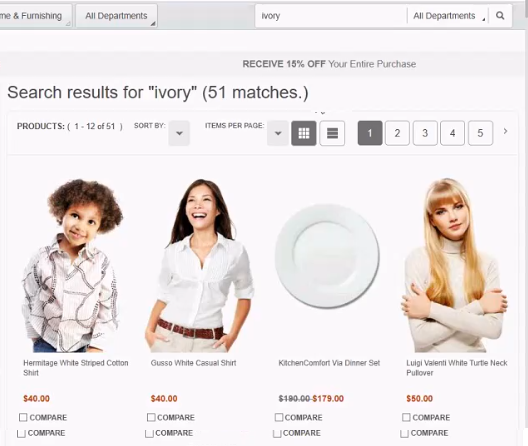
The search returned 51 items, which all share the characteristic of being within the white color family, even though they vary in shading. What makes this possible is a set of over a hundred predefined colors, each of which is given a position in a numeric color space. Colors in this space that are within 20% of your search color can be matched in searches. For instance, "white" is defined as 255. "Beige" is 245.
For information about how to configure color matching, see Configuring Query and Ingest services in ZooKeeper.
The second current class of matchmakers is the measurement matchmaker. Measurements are useful for customers who are looking for products with particular characteristics. For example, suppose that a customer is looking for a laptop with long battery life. If you use the Solr search engine in the Aurora storefront, and search for 3 hour battery life laptop, the search engine will return all the laptops in the catalog.
The same search done using the HCL Commerce Search Query service, exactly one laptop is returned: the one in the catalog that is defined as having a three hour battery life.
Unit of measure conversion is built into the system. If the customer were to use minutes instead of hours, and search for 180 minute battery life laptop, the same catalog item would be found, even though the laptop's battery life is not defined in minutes in the catalog. The Query service automatically converts the units of measure in the query string into their equivalents and searches the catalog for any instances that match under any conversion. It also recognizes short-forms of measures, such as "hr," "lb" or "cm."
In fact the service will return the same result for inexact matches, for instance if the customer has searched for a "150 minute" battery. The Unit of Measure does not need an exact match, but will find products within a specified range of the search number.
In the Management Center, merchandisers can provide length measurement of up to three dimensions. If you use the dimension matchmaker feature, then it enables customers to search for products at the storefront using one or more of these dimensions such as height, width, or length. For example, when the dimension matchmaker is used, a search for "50 inch tall countertop" will be processed differently than one for "50 inch long countertop."
If the Query service is unable to make a match based upon a unit of measurement, it will abandon that approach and match according to any other rules that apply to the search string, up to and including exact word matches.
For information about how to configure measurement matching, see Configuring Query and Ingest services in ZooKeeper.
Memory considerations
For each additional language you use with the matchmaker or NLP service, raise the NiFi mem_reservation and mem_limit parameter values by two gigabytes each.
How NLP works in HCL Commerce Search
- Ingest time NLP
- At indexing time, each product document is analyzed to extract the
following information and to index each document separately. This is so
the information can later be used at query time.
- Name, short description, category name, keywords, manufacturer, and the associated attribute values of a product document is lemmatized by Stanford's CoreNLP runtime. The output of that analysis is categorized and stored in a separate "natural" section of this same index document.
- This "natural" section contains part-of-speech categories such as "noun," "adjective," "name," "category," "color," "measurement," and "dimension."
- Additional measurement conversion to support other unit of measures may be performed during this time.
- Query time NLP
- When a customer performs a text search, either with a simple keyword or
a more complicated natural phrase, the following operations will be
performed through the Authoring or Live Query service:
- The CoreNLP part-of-speech tagger first analyzes the input search phrase to identify what part of speech, (such as noun, adjective, etc) each term belongs to.
- The matchmaker in the Query service scans the PoS types to identify if any special processing is needed for dimension and color. If needed, a specialized query is generated for them and those identified terms will be removed from the search phrase to avoid being processed again later on
- The Query service groups all similar PoS types of the remaining terms and creates a query that constrains them to only search against relevant fields. For example, nouns are only used against names and brands, adjectives against attribute values, and dcardinal number and unit of measures against the measurement natural fields.
Product part number
The CoreNLP system has also been extended with product part number. This feature lets you search using the product part number and SKU part number. The Hero product image should be set up for enabling search using the SKU part number. When the part number is entered in the search box, the NLP processor detects the part number based on the part number pattern provided in the configuration. If the keyword search entered in the search box matches with the provided part number pattern configuration, then the NLP parser avoids the NLP processing and searches for the part number. The Query service returns the product details of the product/SKU having the part number entered in the search box.
- ^[a-zA-Z]+[-]{1}[a-zA-Z]+[-]{1}\d+$
- ^[a-zA-Z]+[-]{1}[a-zA-Z]+[-]{1}\d+[-]{1}\d+$
- ^[a-zA-Z]+[-]{1}[a-zA-Z]+[-]{1}[a-zA-Z]+[-]{1}\d+$
- ^[a-zA-Z]+[-]{1}[a-zA-Z]+[-]{1}[a-zA-Z]+[-]{1}\d+[-]{1}[a-zA-Z]+$
If you want, you can also add a new pattern. For more information on how to add a custom pattern, refer to Adding custom configuration to part number pattern.
When a search term is identified as a part number, then the search is made against
the default.sku.normalized field. This normalized field contains
the product's own part number in addition to any child part numbers. A parent
product part number is also included in the child document.

Partial matches
{
"profileName": "HCL_NLPProfile",
"provider": {
...
"POS_NER": "com.hcl.commerce.search.internal.expression.provider.SearchNLPPOSAndNERProviderHelper",
"Partial_Search": "com.hcl.commerce.search.internal.expression.provider.SearchNLPPartialKeywordSearchProviderHelper",
...Named Entity Recognition (NER)
Name Entity Recognition (NER) is one of the most common text pre-processing techniques used in Natural Language Processing (NLP). NER is used in many fields in Artificial Intelligence (AI) including Natural Language Processing (NLP) and Machine Learning. The HCL Commerce Search provides you the ability to add custom nouns and classifications for NER. For more information on how to add custom nouns and classifications for NER, refer to Adding custom nouns and classifications to NLP Name-Entity-Recognition (NER)