Guía de aprendizaje: Introducción de archivos de Elasticsearch
Datos no estructurados de Ingest para MS Word .docx, PDF, Excel.xlsx, archivos CSV, archivos .txt y archivos HTML, incluidos los metadatos de medios.
About this task
Procedure
-
En el contenedor de Elasticsearch, habilite el adjunto docker.elastic.co/elasticsearch/elasticsearch:7.x.0 de soporte (plugin).
- Desde la ventana de terminal, ejecute el mandato siguiente:
docker exec -it -u 0 commerce_elasticsearch_1 bash - Desde el terminal de contenedor bash, ejecute el mandato siguiente:
elasticsearch-plugin install ingest-attachment - Reinicie el Docker de Elasticsearch:
docker restart commerce_elasticsearch_1 - Después de añadir el mandato del adjunto al dockerfile, cree una nueva imagen de Elasticsearch a partir de la imagen base.
- Desde la ventana de terminal, ejecute el mandato siguiente:
-
Cree el directorio commerce/search-nifi-app:9.1.x.0. en el contenedor NiFi usando los siguientes mandatos:
-docker exec -it -u 0 commerce_nifi_1 bash -mkdir /opt/nifi/extDocs/ chown nifi:nifi /opt/nifi/extDocsPara copiar los archivos en el directorio que desea introducir en Elasticsearch, ejecute el mandato siguiente en la línea de mandatos:
En este ejemplo se utilizarán los archivos siguientes: SampleDocs-travel-laptop.docx y SampleDocs-office-laptop.ppt.docker cp /home/ingestfiles/. commerce_nifi_1:/opt/nifi/extDocs/. -
Importe los conectores siguientes al registro de NiFi commerce/search-registry-app:9.1.x.0.
-
docker cp custom-UnstructuredIndexSchemaUpdateConnector-attachment.json commerce_registry_1:/opt/nifi-registry/flows/.
Para obtener más información, consulte custom-UnstructuredIndexSchemaUpdateConnector-attachment.json.
-
docker cp custom-UnstructuredIndexSchemaUpdate.json commerce_registry_1:/opt/nifi-registry/flows/.
Para obtener más información, consulte custom-UnstructuredIndexSchemaUpdate.json.
-
docker cp custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.json commerce_registry_1:/opt/nifi-registry/flows/.
Para obtener más información, consulte custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.json.
Abra el contenedor de registro de NiFi y ejecute el mandato siguiente:docker exec -it -u 0 commerce_registry_1 bashEjecute los mandatos siguientes desde el terminal de registro.- /opt/nifi-registry/scripts/import_flow.sh custom-UnstructuredIndexSchemaUpdateConnector-attachment /opt/nifi-registry/flows/custom-UnstructuredIndexSchemaUpdateConnector-attachment.json
- /opt/nifi-registry/scripts/import_flow.sh custom-UnstructuredIndexSchemaUpdate /opt/nifi-registry/flows/custom-UnstructuredIndexSchemaUpdate.json
- /opt/nifi-registry/scripts/import_flow.sh custom-UnstructuredIndexDatabaseConnectorPipe-Attachment /opt/nifi-registry/flows/custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.json
-
docker cp custom-UnstructuredIndexSchemaUpdateConnector-attachment.json commerce_registry_1:/opt/nifi-registry/flows/.
-
Utilizando Postman, cree un conector de introducción. Para obtener más información, consulte UI de Swagger.
Abra Postman e introduzca los siguientes detalles:
- URL - http://localhost:30800/connectors
- Método = POST
- Cuerpo = el siguiente cuerpo json:
{ "name": "auth.unstructured", "description": "This is the connector for the unstructured processing", "pipes": [ { "name": "custom-UnstructuredIndexSchemaUpdate" }, { "name": "custom-UnstructuredIndexSchemaUpdateConnector-attachment" }, { "name": "custom-UnstructuredIndexDatabaseConnectorPipe-Attachment", "properties": [ { "name": "Database Driver Location(s)", "value": "${AUTH_JDBC_DRIVER_LOCATION}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Database Connection URL", "value": "${AUTH_JDBC_URL}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Database User", "value": "${AUTH_JDBC_USER_NAME}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } }, { "name": "Password", "value": "${AUTH_JDBC_USER_PASSWORD}", "scope": { "name": "Database Connection Pool", "type": "CONTROLLER_SERVICE" } } ] }, { "name": "Terminal" } ] }
-
Añada el grupo de procesos a la interfaz de usuario de NiFi y enlace los puertos de entrada/salida tal como se muestra en la imagen siguiente. Cuatro canalizaciones de grupos de procesos estarán disponibles en NiFi después de ejecutar el conector:

- a) custom-UnstructuredIndexSchemaUpdate
- Este grupo de procesos lo utiliza Elasticsearch para habilitar la configuración de los adjuntos. Si la configuración de los adjuntos ya está habilitado, se omitirá. Cambie el nombre de índice en el archivo de propiedades de nombre de esquemas para utilizar un esquema existente.
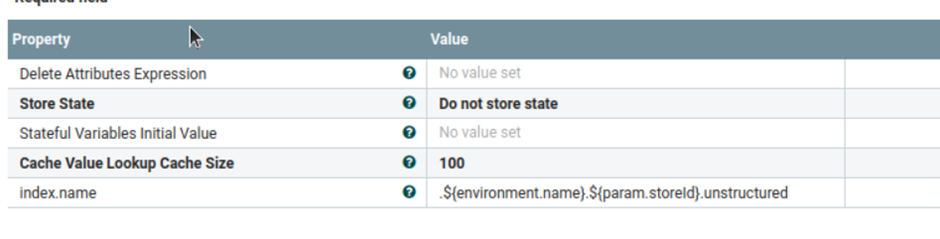
- b) custom-UnstructuredIndexSchemaUpdateConnector-attachment
- Este grupo de procesos lo utiliza Elasticsearch para habilitar la configuración de los adjuntos. Si la configuración de los adjuntos ya es accesible, se omitirá. La siguiente configuración se utiliza de forma predeterminada, pero puede actualizarla para que coincida con los requisitos. En Establecer procesador de adjunto no estructurado, se puede acceder a param.attach.
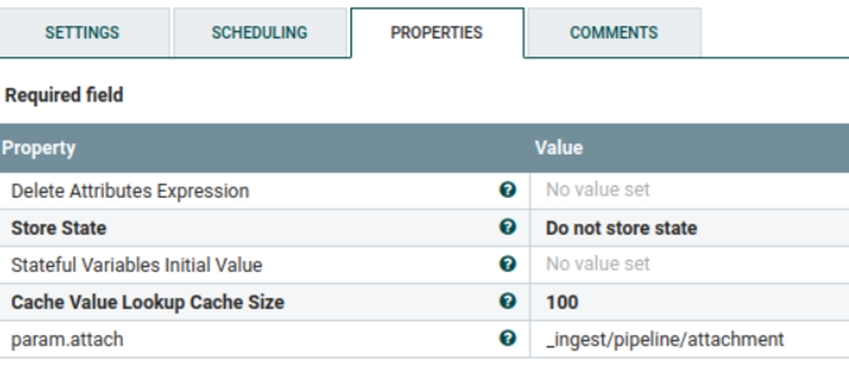 El código siguiente de json está disponible en el procesador Rellenar esquema de índice no estructurado. Aquí puede añadir o actualizar una palabra clave. Esta palabra clave se utilizará para introducir y buscar datos no estructurados.
El código siguiente de json está disponible en el procesador Rellenar esquema de índice no estructurado. Aquí puede añadir o actualizar una palabra clave. Esta palabra clave se utilizará para introducir y buscar datos no estructurados.{ "description" : "Extract attachment information", "processors" : [ { "attachment" : { "field" : "data", "indexed_chars_field" : "max_size", "properties": [ "content", "title", "keywords", "content_type", "content_length" ] } } ] } - c) custom-UnstructuredIndexDatabaseConnectorPipe-Attachment
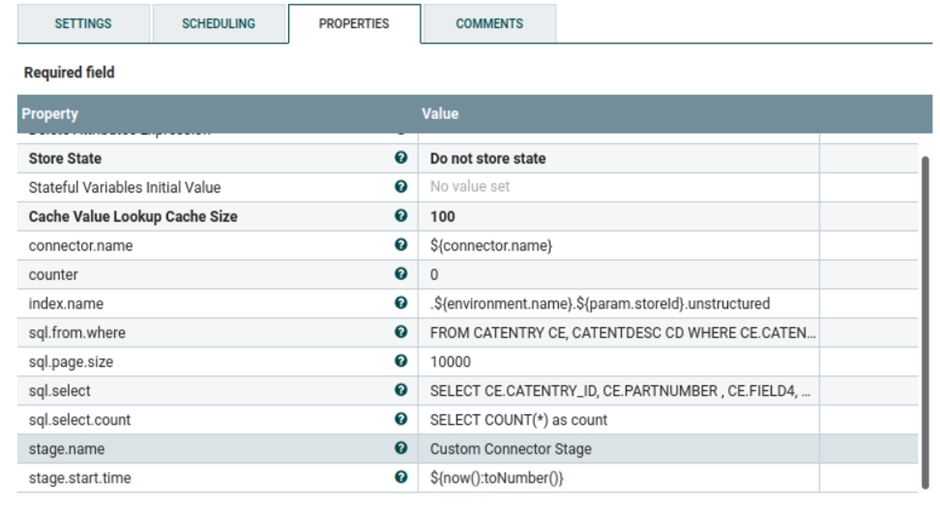
- Este grupo de procesos es responsable de captar las ubicaciones de archivos de la base de datos, leer el contenido del archivo del directorio especificado de la base de datos, codificarlo en base64 e introducirlo en Elasticsearch. Este grupo de procesos utiliza varios procesadores para importar archivos en Elasticsearch.
El procesador Establecer atributo se utiliza para especificar el parámetro que se utilizará para procesar el archivo, que puede cambiar según sea necesario.
- d) Terminal
- Este grupo de procesos completa el flujo de proceso y es responsable de finalizar la salida del proceso anterior.
-
Ejecute las consultas siguientes para establecer la ubicación del archivo en Catentry.field4 (esta tabla se está utilizando actualmente en el grupo de procesos). Puede modificar la consulta y añadir varias transacciones según sea necesario para establecer la ubicación del archivo para las entradas de catálogo.
UPDATE catentry SET FIELD4 = '/opt/nifi/extDocs/SampleDocs-travel-laptop.docx' WHERE PARTNUMBER = 'CLA022_2203' UPDATE catentry SET FIELD4 = '/opt/nifi/extDocs/SampleDocs-office-laptop.ppt' WHERE PARTNUMBER = 'CLA022_2205'Note: Si desea establecer la ubicación del archivo en una tabla diferente, tendrá que modificar las propiedades siguientes en el procesador Establecer atributo bajo custom-UnstructuredIndexDatabaseConnectorPipe-Attachment. Actualmente se están utilizando las consultas siguientes. Puede actualizarlas o modificarlas según sea necesario.
Actualmente se están utilizando las consultas siguientes. Puede actualizarlas o modificarlas según sea necesario.SELECT COUNT(*) as count FROM CATENTRY CE, CATENTDESC CD WHERE CE.CATENTRY_ID = CD.CATENTRY_ID AND CD.LANGUAGE_ID =-1 AND CE.MARKFORDELETE =0 AND CE.BUYABLE =1 AND CD.PUBLISHED =1 AND ce.FIELD4 IS not NULL AND CE.CATENTRY_ID IN (SELECT C.CATENTRY_ID FROM CATGPENREL R, CATENTRY C WHERE R.CATALOG_ID IN (SELECT CATALOG_ID FROM STORECAT WHERE STOREENT_ID IN (SELECT RELATEDSTORE_ID FROM STOREREL WHERE STATE = 1 AND STRELTYP_ID = -4 AND STORE_ID = ${param.storeId})) AND R.CATENTRY_ID = C.CATENTRY_ID AND C.MARKFORDELETE = 0 AND C.CATENTTYPE_ID <> 'ItemBean') SELECT CE.CATENTRY_ID, CE.PARTNUMBER , CE.FIELD4, CD.NAME, CD.SHORTDESCRIPTION , CD.PUBLISHED FROM CATENTRY CE, CATENTDESC CD WHERE CE.CATENTRY_ID = CD.CATENTRY_ID AND CD.LANGUAGE_ID =-1 AND CE.MARKFORDELETE =0 AND CE.BUYABLE =1 AND CD.PUBLISHED =1 AND ce.FIELD4 IS not NULL AND CE.CATENTRY_ID IN (SELECT C.CATENTRY_ID FROM CATGPENREL R, CATENTRY C WHERE R.CATALOG_ID IN (SELECT CATALOG_ID FROM STORECAT WHERE STOREENT_ID IN (SELECT RELATEDSTORE_ID FROM STOREREL WHERE STATE = 1 AND STRELTYP_ID = -4 AND STORE_ID = ${param.storeId})) AND R.CATENTRY_ID = C.CATENTRY_ID AND C.MARKFORDELETE = 0 AND C.CATENTTYPE_ID <> 'ItemBean')Note: Si desea actualizar el nombre del esquema en el que se introducirá el archivo adjunto, modifique las propiedades siguientes en el procesador Establecer atributo en custom-UnstructuredIndexDatabaseConnectorPipe-Attachment.
-
Conecte el grupo de procesos auth.unstructured - custom-UnstructuredIndexSchemaUpdate con el grupo de procesos Servicio de direccionamiento con INPUT establecido en auth.unstructured.
Note: Si se sigue el procedimiento de conexión, este proceso ya debería estar enlazado al servicio de direccionamiento. Asegúrese de que la ruta auth.unstructured funciona.
-
Vaya al siguiente grupo de procesos.

- Seleccione el procesador Ejecutar SQL.
- Haga clic derecho y seleccione Ver configuración.
- Seleccione el botón Flecha en el lado derecho de la propiedad siguiente.

- Asegúrese de que el servicio de agrupación de conexiones de base de datos esté habilitado.

-
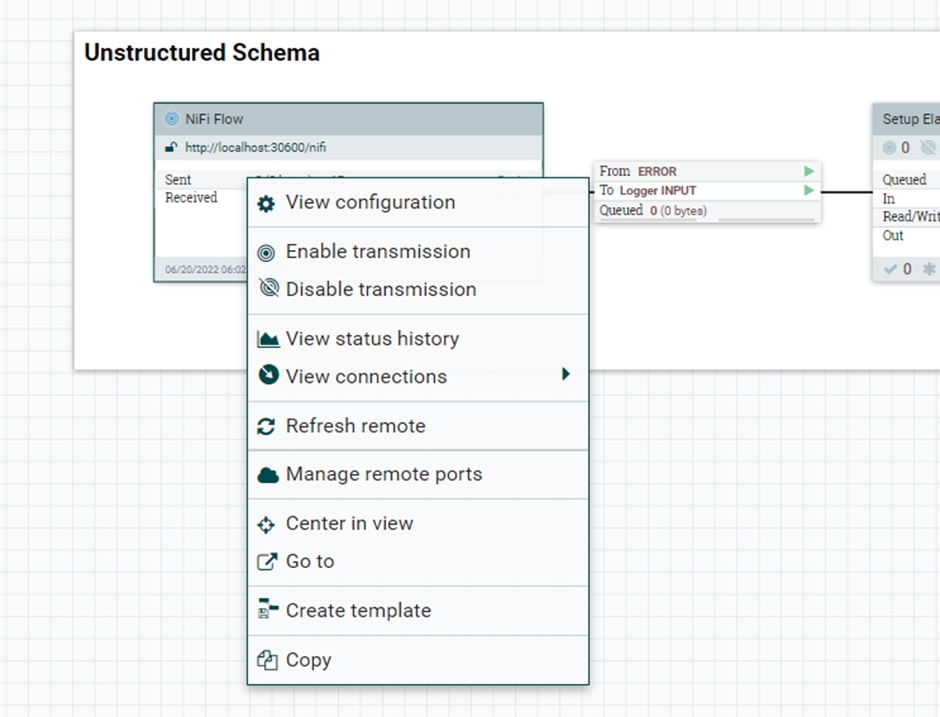
Inicie cada uno de los cuatro grupos de procesos, luego vaya dentro de cada uno de ellos, haga clic con el botón derecho en el flujo de NiFi y, a continuación, seleccione Habilitar transmisión.
Note: Es posible que las transmisiones ya se hayan activado.
-
Después de iniciar el grupo de procesos, ejecute la URL siguiente desde Postman.
POST- https://localhost:5443/wcs/resources/admin/index/dataImport/build?connectorId=auth.unstructured&storeId=1Para comprobar el estado:GET- https://localhost:5443/wcs/resources/admin/index/dataImport/status?jobStatusId=1036 -
Ahora puede validar datos no estructurados indexados y pasar la palabra clave que ha especificado al configurar el adjunto:
POST - localhost:30200/.auth.1.unstructured/_searchCuerpo: Con contenido disponible en el archivo.{ "query": { "bool": { "must": [ { "query_string": { "query": "lightweight" } } ] } } }Cuerpo: con SKU (número de pieza).{ "query": { "bool": { "must": [ { "query_string": { "query": "CLA022_2205" } } ] } } }Cuerpo: con extensión de archivo.{ "query": { "bool": { "must": [ { "query_string": { "query": "docx" } } ] } } }