Customizing Ingest profiles
You can use custom Ingest profiles to override the index schema definition. You can also use them to customize the Extraction, Transformation and Loading (ETL) side-flow of the ingest process, and for bulk services. Java methods exist to make customizing each stage easy.
{
"profileName": "DatabasePriceStage1a",
"provider": [
"com.mycompany.data.ingest.product.providers.ChangeSQL"
],
"preprocessor": [],
"postprocessor": []
} You develop and build the custom Java extensions used by the profile inside the NiFi Toolkit in Eclipse.To activate your binaries, you package them and deploy them to the /lib folder inside the NiFi container.
Customizing index schema definitions
You can customize the index schema definition during the index preparation stage. You define the schema provider using an Ingest profile, and you set that at the connector schema pipe level.
IndexSchemaProvider Java
interface. The method is defined as
follows.public interface IndexSchemaProvider {
public String invoke(final ProcessContext context, final ProcessSession session, final String schema)
throws ProcessException;
}- context
- Provides access to convenience methods for obtaining property values, delaying the scheduling of the pncessor, provides access to Controller Services, etc.
- session
- Provides access to a {@link ProcessSession}, which can be used for accessing FlowFiles, etc.
- schema
- Contains the Elasticsearch index schema setting and mapping definition.
- return
- The modified schema definition.
- throws
- Throws a ProcessExeption if processing did not complete normally.
public class MyProductSchemaProvider implements IndexSchemaProvider {
@override
public String invoke(final ProcessContext context, final ProcessSession session, final String schema) throws ProcessException {
String mySchema = schema;
// TODO: logic for customizing schema definition goes here
return mySchema;
}
}{
"profileName": "MyProductSchema",
"provider": [
"com.mycompany.data.index.product.providers.MyProductSchemaProvider"
]
}Customizing default ETL logic
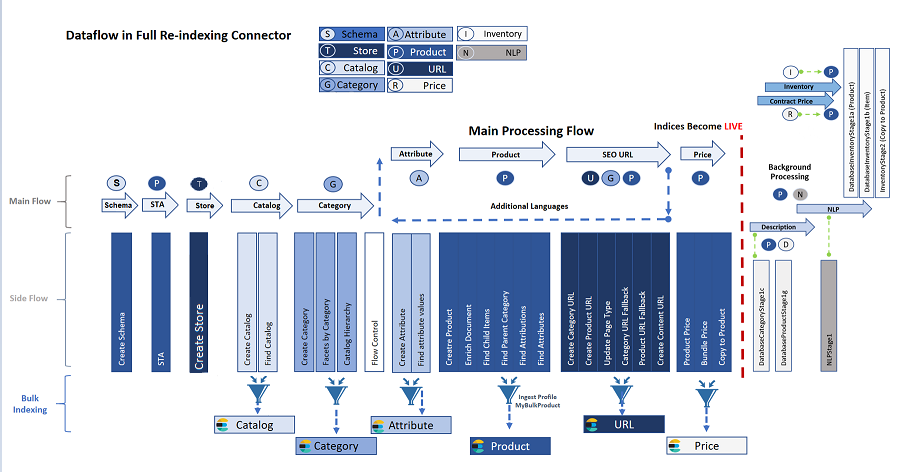
The Ingest service performs the essential Extraction, Transformation and Loading (ETL) operations on business data that make them available to the search index. Each pipe in a connector is responsible for doing one or more ETL operations, and you can add and customize your own pipes.
The indexing pipeline consists of a main flow, where data that the Ingest service knows how to extract moves in a linear way from input to output; and an ETL side-flow, which has several stages whose behavior you can customize. The following diagram shows the design model for the system.
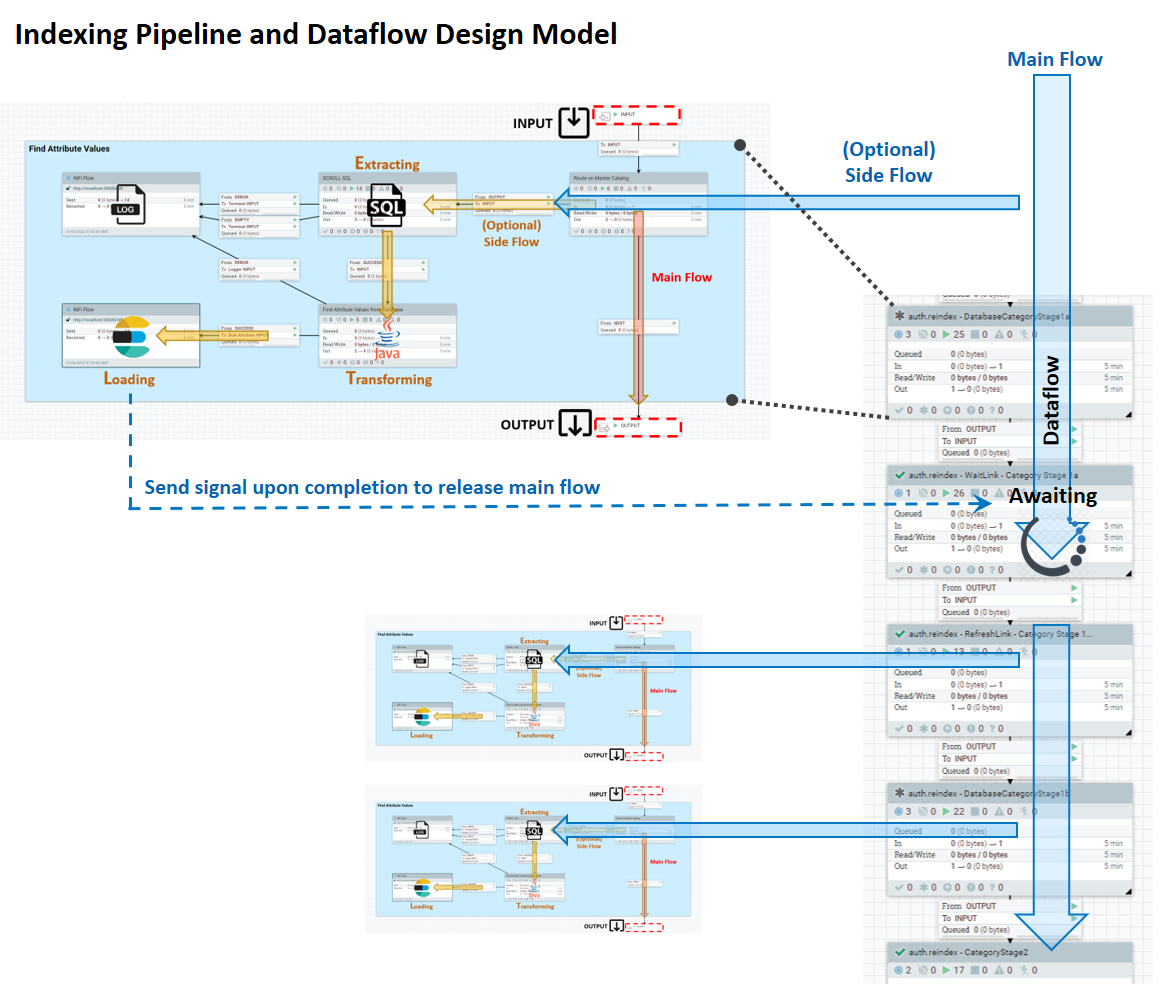
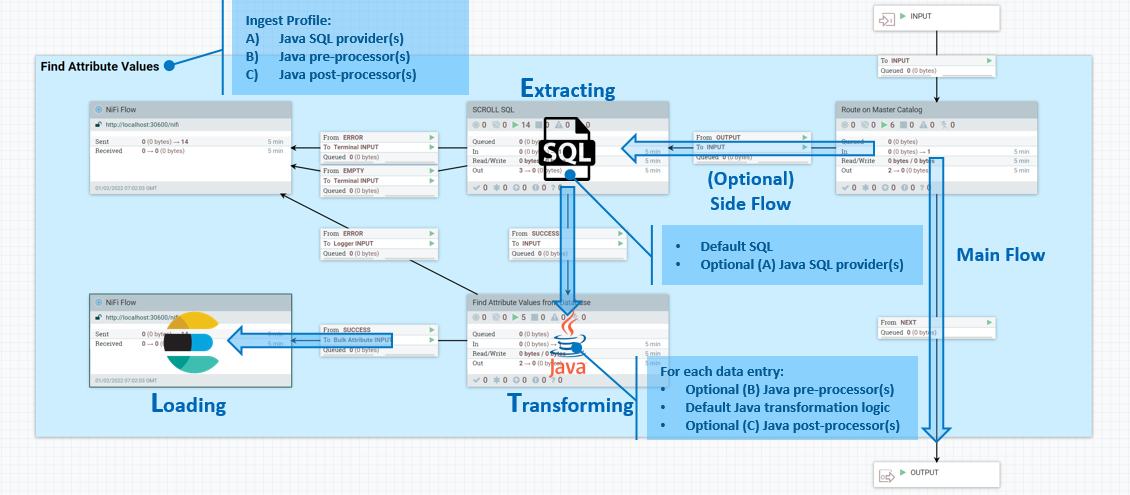
The ETL processes take place in the side flow of data input. In the side flow, extraction is managed by SQL queries, transformation is done using Java expressions, and loading is performed by Elasticsearch. An Ingest profile lets you define additional Java SQL providers for the Extract stage and pre- and post-processors, also in Java.
Extraction stage
IngestExpressionProvider as a custom exit for
customizing ETL. The interface is defined as
follows.public interface IngestExpressionProvider {
public String invoke(final ProcessContext context, final ProcessSession session, final String expression)
throws ProcessException;- context
- Provides access to convenient methods for obtaining property values, delaying the scheduling of the processor, and providing access to controller services, among others.
- session
- Provides access to a
{@link ProcessSession}, which can be used to access FlowFiles and other processes. - expression
- Contains the the database SQL expression to be executed.
- return
- The modified SQL expression.
- throws
ProcessExceptionif processing did not complete normally.
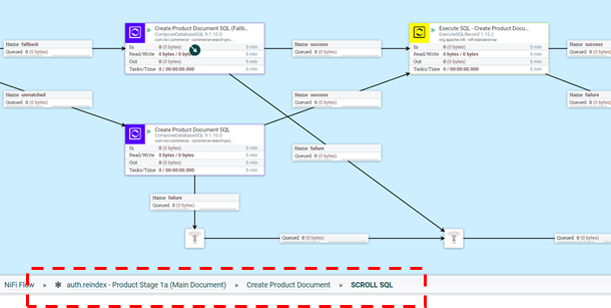
To customize the Extract phase of the ETL process, you can intervene in the logic
inside the SCROLL SQL part of the side flow. The exact location in the NiFi flow is
auth.reindex-Product Stage 1a (Main Document)/Create Product
Document/SCROLL SQL.
public class MyProductStage1aProvider implements IngestExpressionProvider {
@override
public String invoke(final ProcessContext context, final ProcessSession session, final String expression) throws ProcessException {
String myExpression = expression;
//Logic for customizing database SQL expression goes here
return myExpression;
}
} Note:
Note:
Prior to HCL Commerce Search Version 9.1.15, the SQL was kept in the same template schema in the NiFi registry as other customization code. To make it easier for you to customize the SQL by itself, this SQL has been moved out to separate files in a src/main/resources/sql directory under the version-specific NAR and JAR. For example, you could find DatabaseProductStage.sql under commerce-search-processors-nar-9.1.15.0.nar/bundled-dependencies/commerce-search-processors-9.1.15.0.jar/src/main/resources/sql if commerce-search-processors-nar-9.1.15.0.nar was your current version-specific JAR. The previous ComposeDatabaseSQL processor has been replaced with a new processor, GenerateSQL, that is used to retrieve these files. A shell script is used to update the SQL in the comment section of every processor, making it easier for you to access it from anywhere.
Pre-processing stage
IngestFlowPreProcessor to your profile, as a
custom user exit before the flow transform happens at the current stage. The
interface is defined as
follows.public interface IngestFlowPreProcessor {
public Map<String, Object> invoke (final ProcessContent context, final ProcessSession session,
final Map<String, Object> data) throws ProcessException;
}- context
- Provides access to convenient methods for obtaining property values and delaying the scheduling of the processor, and provides access to controller and other services.
- session
- Provides access to a
{@link ProcessSession}, which can be used to access FlowFiles and other services. - data
- Contains an entry from the database result set.
- return
- The modified data for downstream processing.
- throws
ProcessExceptionif processing did not complete properly.
IngestFlowPreProcessor.public class MyProductStage1aPreProcessor implements IngestFlowPreProcessor {
@Override
public Map<String, Object> invoke(final ProcessContext context, final ProcessSession session,
final Map<String, Object> data) throws ProcessException {
// TODO: logic for customizing database result entry goes here
return myData;
}
}
Post-processing
IngestFlowPostProcessor method as a custom user
exit after the Transformation stage and before the Loading stage. The method is
defined as
follows.public interface IngestFlowPostProcessor {
public Map<String, Object> invoke(final ProcessContext context, final ProcessSession session,
final Map<String, Object> data, final Map<String, Object> document) throws ProcessoException;- context
- Provides access to convenient methods for obtaining property values and delaying the scheduling of the processor, and proides access to controller and other services.
- session
- Provides access to a
{@link ProcessSession}, which can be used to access FlowFiles and other services. - data
- Contains an entry from the database result set.
- document
- Contains a Json object representing the final document to be sent to Elasticsearch.
- return
- The modified data for downstream processing.
- throws
ProcessExceptionif processing did not complete properly.
The following screenshot shows an example of code used to extend the post-processing
stage via IngestFlowPostProcessor. Here,
myDocument represents the final Json document that will be sent
on to Elasticsearch.
public class MyProductStage1aPostProcessor implements IngestFlowPostProcessor {
@override
public Map<String, Object> invoke(final ProcessContext context, final ProcessSession session,
final Map<String, Object> data, final Map<String, Object> document) throws ProcessException {
Map<String, Object> myDocument = new HashMap(document);
// TODO: logic for customizing the Json document before sending to Elasticsearch
//
// For example ....
final Map<String, String> x_field1 = new HashMap<String, String>();
// Retrieve value of FIELD1 from database result entry
final String FIELD1 = (String) data.get("FIELD1");
// Insert value of FIELD1 into the resulting document to be sent to Elasticsearch
if (StringUtils.isNotBlank(FIELD1)) {
// Re-use default dynamic keyword field name "*.raw" (can be found from Product index schema)
String field1 = FIELD1.trim();
//
// TODO: perform your own transformation of field1
//
x_field1.put("raw", field1);
// x_field1.raw
myDocument.put("x_field1", x_field1);
}
return myDocument;
}
}Customizing bulk services
The full reindexing flow proceeds as a set of stages with optional side flows. The output of these side flows is funneled through bulk services and into each corresponding index. Each index has a dedicated bulk service and an ingest profile can be bound to this service if there is a need to inject a custom user exit into this dataflow. You can call a pre- and post-processor at this stage as well,before sending the bulk payload to Elasticsearch and after receiving the response from Elasticsearch.
Building customizations
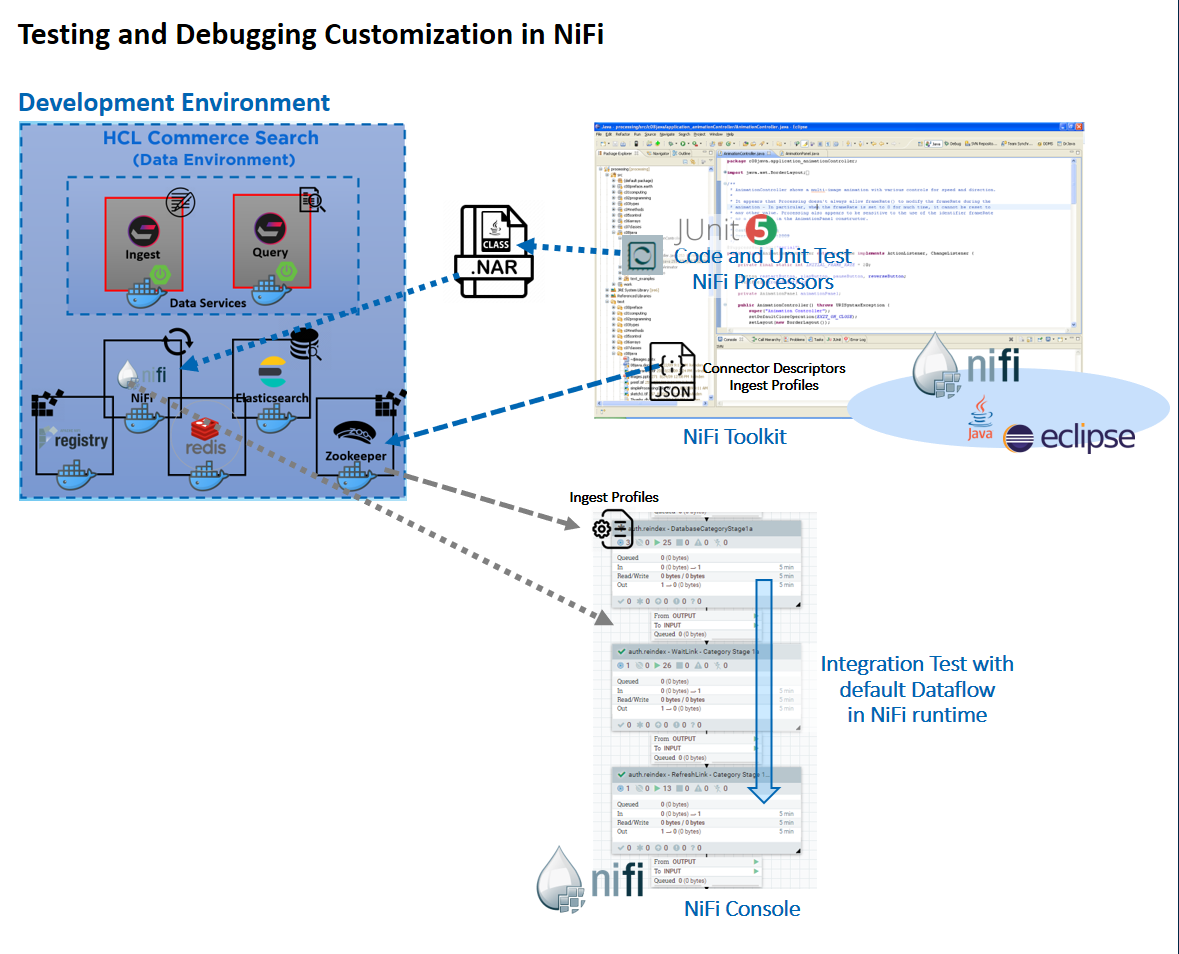
- Set up a NiFi Toolkit development environment. For more information, see Setting up the HCL Commerce Developer Search environment.
- Develop and unit test your Ingest profile custom logics.
- Create your Ingest profile configuration and bind it against a connector pipe in a NiFi runtime environment.
- Deploy your Ingest profile custom extensions to your NiFi runtime environment for further testing.
For a detailed tutorial on how to customize, test and deploy your customizations via Ingest profiles, see Tutorial: Customizing default connectors with Ingest Profile. This tutorial covers topics such as development environment prerequisites, building and transfering custom .jar files into your environment.
Testing and debugging
You can perform coding and unit testing inside of the Eclipse based NiFi Toolkit using mock data, using the JUnit testing option provided by Maven. Two unit test examples are provided for you in the commerce-custom-search-marketplace-seller.zip file. These files are ComposeDatabaseSQLTest.java, and CreateProductDocumentFromDatabaseTest.java.
ChangeSQL is an Ingest profile expression provider. You can use this sample reference to learn how to modify SQL used in the default Extract, Transform, and Load (ETL) stages. ComposeDatabaseSQLTest is the JUnit test that can be used for verifying the code logic inside of ChangeSQL.
ChangeDocument is an Ingest profile
post-processor extension that demonstrates how you can perform further data
manipulation following the default transformation, in one of the Product related
Ingest stages. CreateProductDocumentFromDatabaseTest is the JUnit
test that can be used to verify the code logic inside of
ChangeDocument.
Once custom configurations and Java extension logics are ready, they can be exported into a custom NiFi NAR file and added to the NiFi container. This allows you to test the custom logic with the default data flow in the NiFi runtime.
To run the JUnit test, right-click on the chosen JUnit Test class and choose either Run As... or .