Perform cognitive search on static webpages
Follow the instructions in this tutorial to perform cognitive search on static webpages.
In this tutorial, you'll learn how to:
- Web scrap a static webpage and mine the content and PDF files
- Test cognitive search
Prerequisites
Before you start upload and train the documents for cognitive search, make sure have the following:
- Access to Cognitive search feature
- Static webpages with content and PDF or Word documents
Web scarp static web page
To begin with, create a new project and navigate to the Settings page, and perform the following:
-
In the Knowledge Mining page, enter the static webpage and include keywords, which are to be included and excluded for mining the urls. For example, if you are looking out for Google's cloud product, you can enter "https://cloud.google.com/products" urls, and set the parameters to level "1", and enter "Natural Language AI" keyword in include keywords.
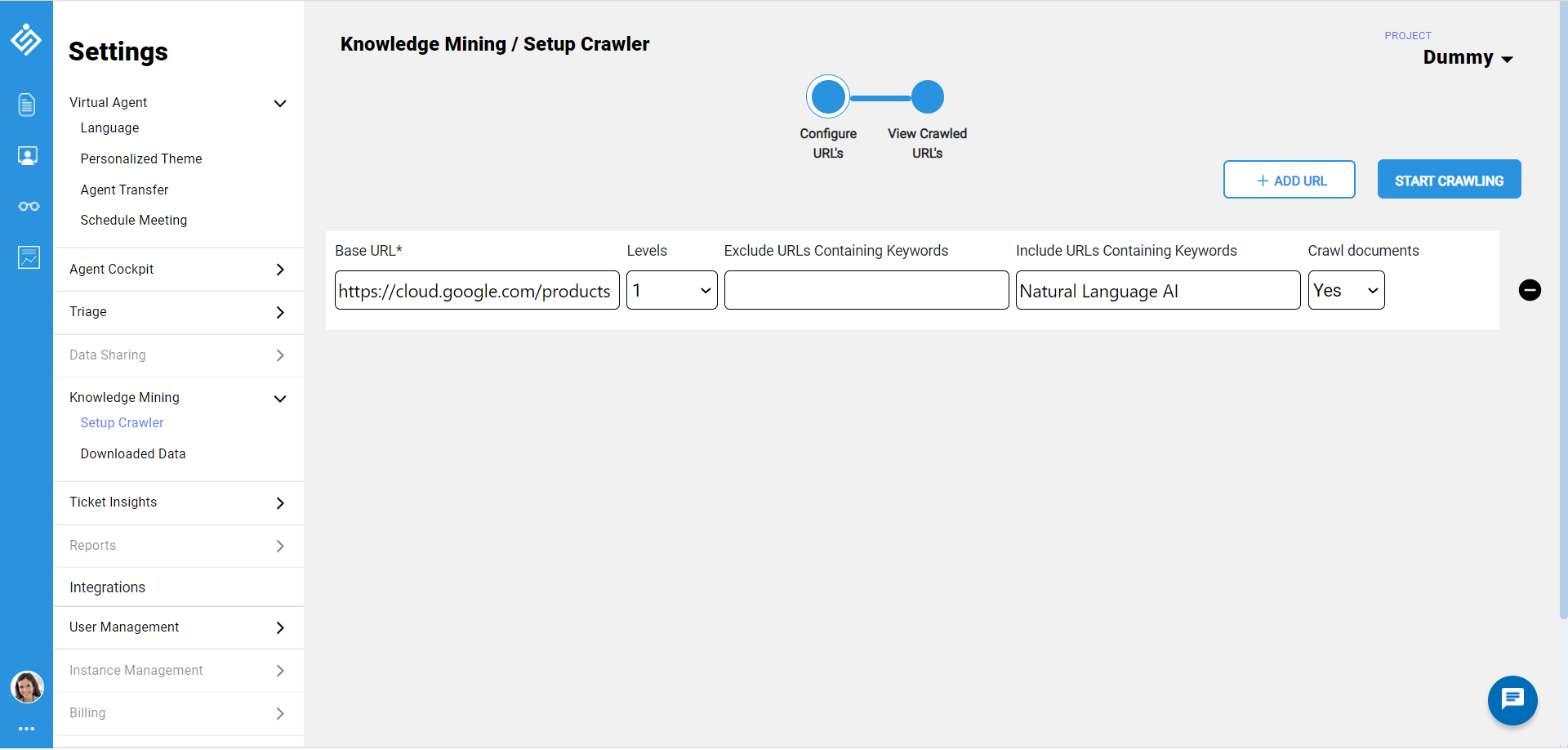
- Leave the default setting of Crawl documents to Yes, to include the pdf files available in the static pages.
-
In case, if you want to crawl second level pages from static webpage, select appropriate Levels option.Note: Make sure the number of urls in the second level does not exceed above 200 urls.
- Click the Start Crawling button to start web url mining. As a result, the system will mine and list all the urls containing the keywords from first level.
-
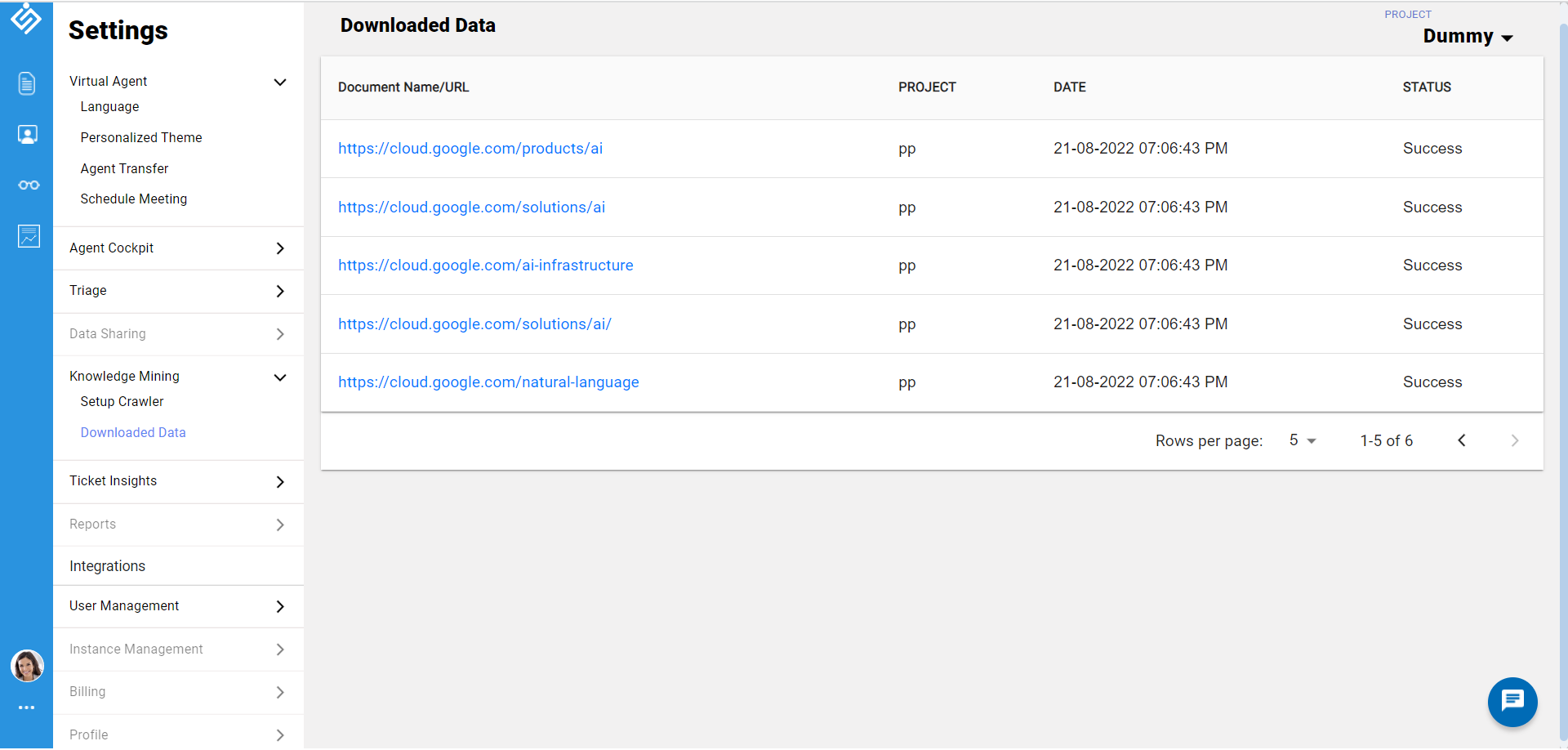
You can either select required urls or simply click the Download data button to scrap the web content and pdf files from the mined url. For our example, the system downloaded approximately six urls without any PDF files for the static base url as shown below.
Test cognitive search
After web scraping the webpage content, prepare few questionnaires like "I am
looking for cloud product". In the cognitive search page, you can directly enter
those questions. Based on the entered questions, the context based results will
be listed in the groups. For our example, lists out seven matching context
results from the "https://cloud.google.com/products/ai" page, which is web mined
from the base static url "https://cloud.google.com/products". Sample screenshot
of the results is provided for reference.
