Search index verification
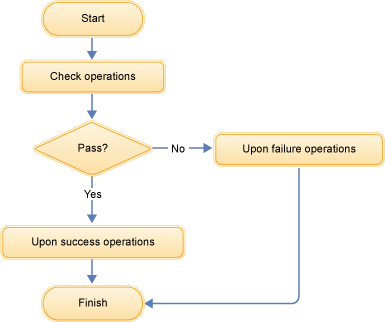
- Check operations verify the integrity of the search index by validating the data integrity of the index, or by validating the index files integrity.
- Optional: Upon success operations are run if all of the check operations return a success status. Typical upon success operations include tasks such as creating an index backup, or cache invalidation.
- Optional: Upon failure operations are run if any of the check operations return a failure status. Typical upon failure operations include tasks such as restoring an index backup, or sending error notifications to the site administrator.
Check operations can be configured with the replication handler so that every time replication occurs the check operations logic is called. Alternatively, upon success or upon failure operations can be configured with their own handler to be called directly if needed. The default operations are configured by using the /operation? handler.
Example
- A check operation is configured to run on a repeater or on a subordinate server against the search index.
- The check operation runs automatically against the newly replicated index to validate the
replicated index.
Check operations can be a set of Solr queries against the index to verify the catalog data, or a sophisticated operation to validate the index segment files that verifies every indexed document. Check operations must return either a true or false status, which is then used to determine any further actions.
- If all check operations succeed, you might want to run upon success operations that create an
index backup, trigger cache invalidation, or raise any other relevant events.
Alternatively, if one of the check operations report a problem with the newly replicated index, you might want to run upon failure operations that rebuild the index, or restore an earlier backup, or refetch the index from the master server. In most failure cases, you might want to have upon failure operations that notify the site administrator of the problem.
You can configure check, upon success, and upon failure operations to suit your business needs. The complexity of the operations depends on the available resources, and any time constraints of the running operations.