Merging indexes by shard using multiple JVMs
When indexing takes too long, and further tuning does not seem to help, it could be that your server is approaching its physical limitations. To avoid such a condition, you can distribute the index across two or more Search servers, so that the indexing workload is also distributed. You can distribute your index across multiple Java Virtual Machines.
Before you begin
To distribute an index, you divide it into partitions called shards. Each shard runs on a separate virtual machine, or even in a separate physical node. Once all of the index shards are successfully populated, they can be merged in one optimized index, to be used with your storefront for sorting, faceting and filtering.
In order to perform index sharding with the Search server, first set up your shard environment using the following guidelines.- Determine the number of shards that you will be using, based on the available capacity of your server. At least one CPU core's capacity must be available for each separate index shard.
- Ensure that you have run the SetupSearchIndex command to create the Price index, using the indexSubType option. For detailed instructions on setting up the Price index, see step 2 of Indexing contract prices using Index Load.
- In your authoring environment, create additional Search cluster members for your index shards. See Clustering WebSphere Commerce Search for details. Note that if you are using index replication, do not configure any of your index shards to participate in your index replication network. These shards are only used for index building. The final version of the index should be on the Master server, which should then be replicated to the Repeater and then to the Subordinates.
- Allocate enough heap memory for each of your index shards. Refer to WebSphere Commerce Search performance tuning for recommendations on how to configure the solrconfig.xml configuration file.
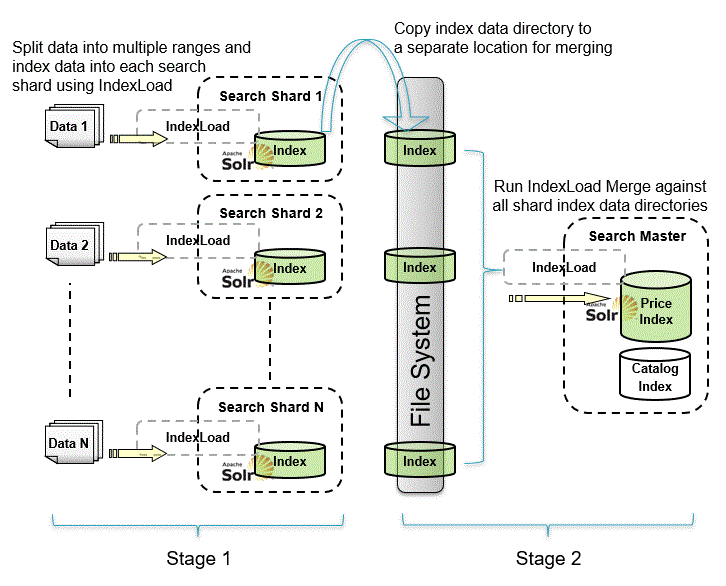
Once you have set up your shard environment, you can then perform indexing to each shard using Index Load. The following diagram shows the two stages involved in sharding and rebuilding the index.
Procedure
-
In the first stage, you prepare the data from the existing indexes.
- Split your business data into equal catentry_id ranges for use with your index shards.
- Set up Index Load configuration files for each of your shards. For detailed instructions, see Index Load configuration files for indexing from database.
- Use Index Load to index your data into each index shard. For more information, see Index Load.
-
In the second stage, copy your index data directory to a separate location and merge the
indexes.
- Once all your shards are ready, copy the index data directory to a separate location on the filesystem.
- You will need merge configuration files that specify your source and target directories. To create these files, follow the instructions in Index Load configuration files for merging indexes.
- Run Index Load Merge against all shard index data directories. Index Load Merge processes your data in two steps, an index merge step and an optimization step.