Stand-alone product discovery
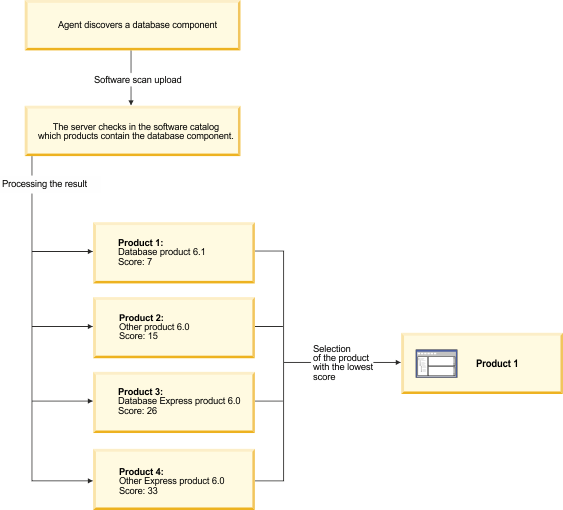
Stand-alone product discovery is a rule that identifies components that have more than one default component to product relation. For each relation, it compares the name of the component with the name of the product and calculates the Levenshtein distance. During the calculation, production components are assigned to production products, and non-production components such as trial, demonstration, limited, or express versions are assigned to non-production products. The algorithm does not favor shorter names, but names that have more letters in common. Based on the calculations, the product-component relation with the shortest distance (represented by the lowest score) is selected. If a few relations have the same score, they are ordered alphabetically.
Example