Custom Web Crawler Discovery Service
What is a web crawler?
Web Crawler, also known as ‘Spiders and Robots’, is a type of bot that is typically operated by search engines like Google and Bing. It indexes and downloads the content of websites across the internet so that website can appear in search engine results. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
Search engines don’t magically know what websites exist on the Internet. The programs must crawl and index them before they can deliver the right pages for keyword and phrases, or the words people use to find a useful page.
For example, Think of it like grocery shopping in a new store. You must walk down the aisles and look at the products before you can pick out what you need. In the same way, search engines use web crawler programs as their helpers to browse the Internet for pages before storing that page data to use in future searches.
This analogy also applies to how crawlers travel from link to link on pages. You can’t see what’s behind a can of soup on the grocery store shelf until you’ve lifted the can in front. Search engine crawlers also need a starting place — a link — before they can find the next page and the next link.
How does it work?
When you search using a keyword on a search engine, it goes through trillions of pages to generate a list of results related to that term. How exactly do these search engines have all of these pages on file, know how to look for them, and generate these results within seconds?
So, all this is done by crawlers. These are automated programs (often called “robots” or “bots”) that “crawl” or browse across the web so that they can be added to search engines.
- These robots index websites to create a list of pages that eventually appear in your search results. Crawlers also create and store copies of these pages in the engine’s database, which allows you to make searches almost instantly.
- Website owners can use certain processes to help search engines index their websites, such as uploading a site map. This is a file containing all the links and pages that are part of your website. It’s normally used to indicate what pages you’d like indexed.
- One can restrict the page from getting crawled through robots.txt file. This is a simple text file that dictates to crawlers which web pages to exclude from indexing. It also reduces the website load.
How crawling is used in IBM Watson Discovery?
BigFix AEX works on IBM Watson Discovery Service as depicted in Knowledge Management Console. WDS is an intelligent and text analytics platform. It is a cognitive search and content analytics engine that you can add to applications to identify patterns, trends, and actionable insights to drive better decision-making
IBM Watson Discovery works on two main principles - Collection Building and Search.
Collection Building involves four steps:
- Ingestion
- Conversion
- Enrichment
- Indexing
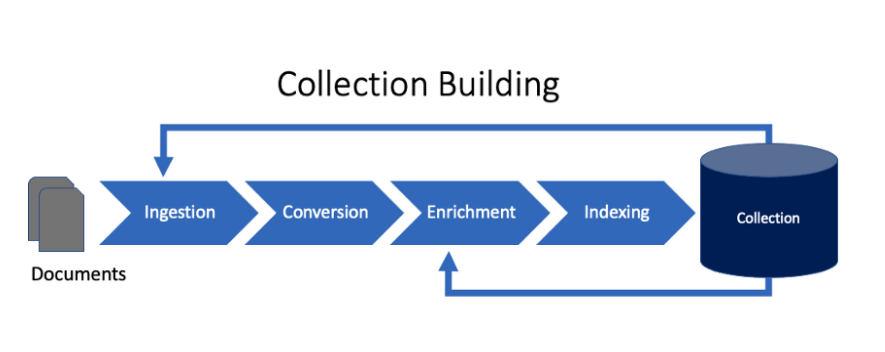
So Crawling is used by its foremost step which is Ingestion. Ingestion is the process of taking documents into the Discovery system. Ingestion can use Connectors to connect to repositories like SharePoint or Salesforce, or a Crawler to download documents and pages from websites or filesystem.
- Select WEB CRAWL from KMS Data Source as shown in the following figure:

- The following screen appears:
Figure 3. Figure 206 – Web Data Source 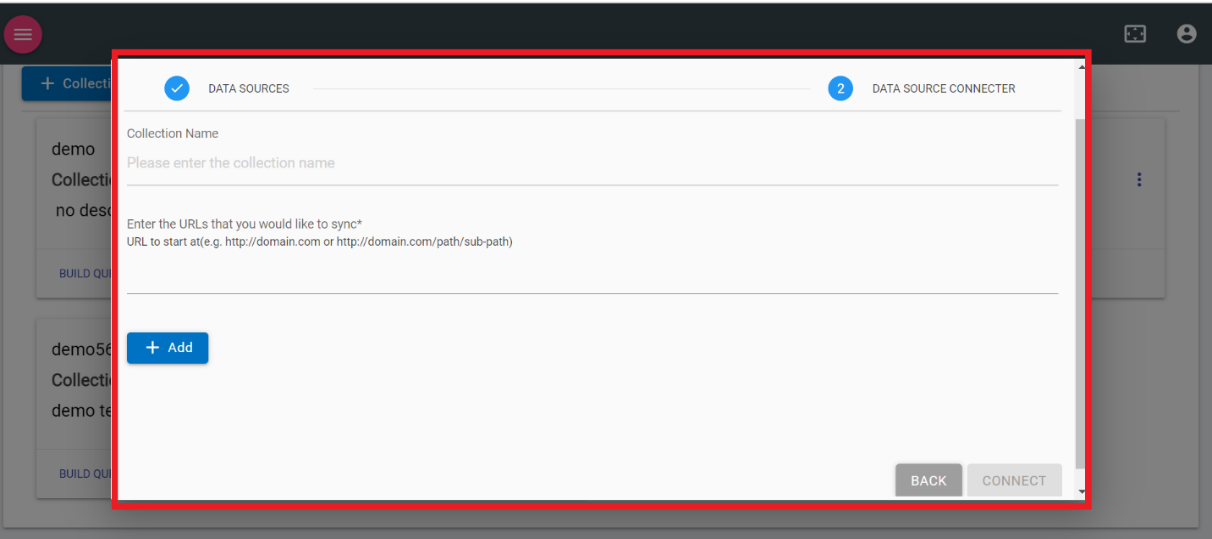
- Provide the URL to read the document/documents and click Connect. Click Back to go back to the previous screen.
Unlike other data sources, Web crawl doesn’t require authentication. It contains only two inputs one is Collection Name which is user defined and the URL that you would like to sync.
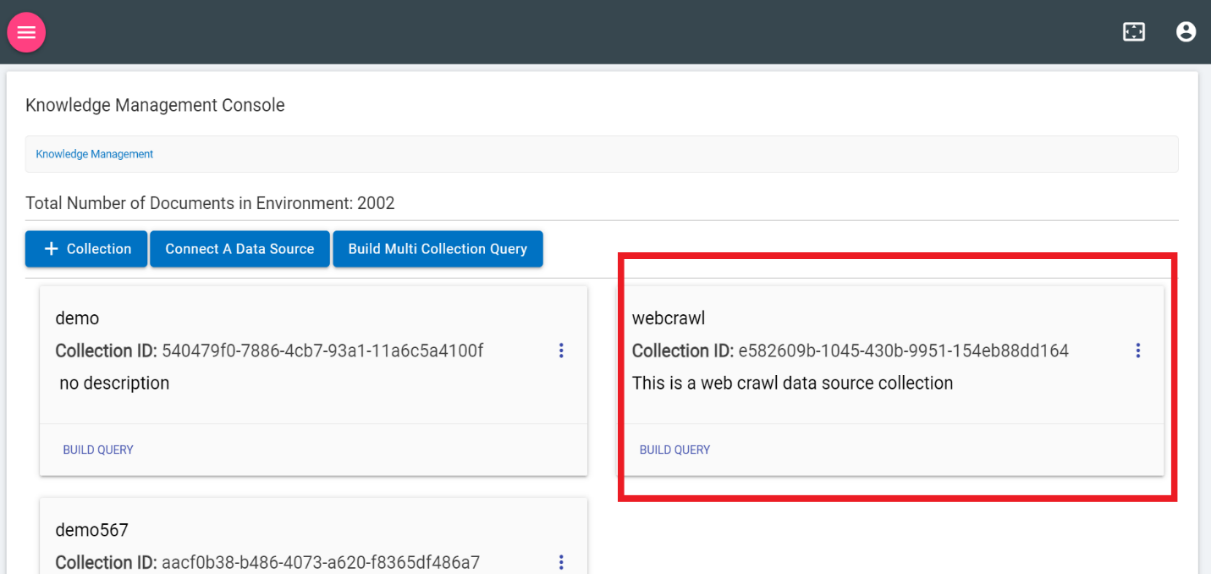
- Once connected it will be added in KMS and ready for building query.
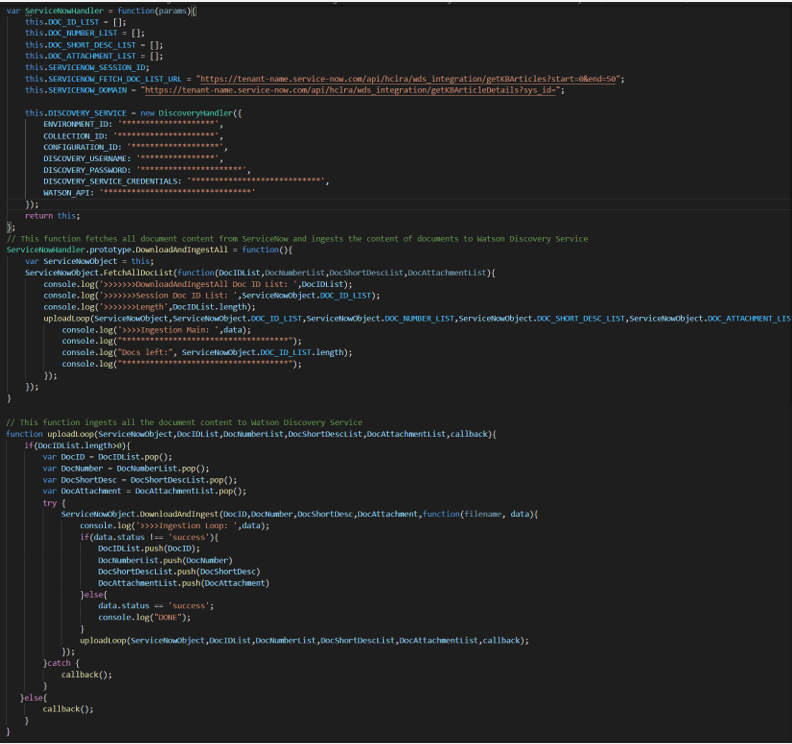
BigFix AEX Crawler Script Sample:
It includes:
- Credentials of the service from where the files will be downloaded.
- APIs which will provide the files list and details of the sys_id.
- Function to Download and Ingest the file.
- Function to upload which will ingest all the document content to Watson Discovery Service.