Deploying HCL DX 9.5 Container artifact updates with minimal operations downtime
This topic provides guidance to update artifacts in HCL Digital Experience container deployments while minimizing operations downtime.
Introduction
In a Kubernetes environment, how can one achieve zero downtime deployments of new artifacts?
In a “traditional” HCL Digital Experience deployment to on-premises platforms such as Windows, AIX, or Linux OS, adding new components such as a new theme, new portlets, new pages, new PZN rules, etc. is typically achieved by first validating these new artifacts in lower “non-production” cells prior to introduction to the production cell or cells. When referring to a “traditional” deployment, that refers to a single cluster in a single cell as depicted in the HCL DX Roadmap: Production and delivery environment.
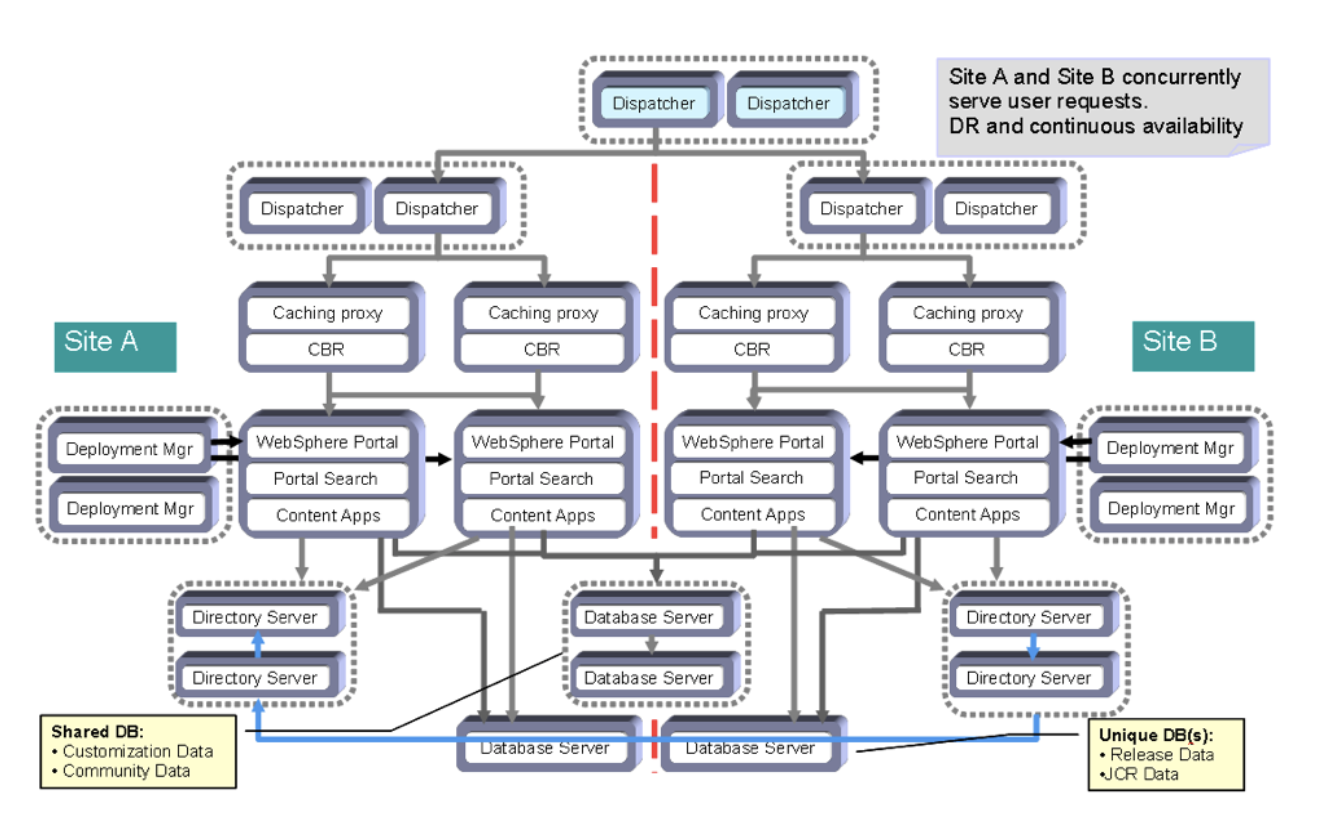
One could always take more risk and not employ a two-cell HA environment for production. Rather, one could assume that if the new artifacts were proven in several lower environments, the risk of failure in a single cell production environment was very low.
Kubernetes – Two Views
There are two ways to view deployment to a supported Kubernetes environment. The first is purely from a tooling point of view. In other words, what processes and tooling does one use to get new artifacts into a Kubernetes system? Are these processes and tools different than one would use in a non-Kubernetes HCL Digital Experience platform deployment?
The second view, as discussed in the introduction, is how to achieve deployment while minimizing operations downtime?
Difference and Similarities Between Traditional and Kubernetes DX Deployments
To properly understand zero downtime deployment, it is helpful to understand how a traditional Digital Experience Portal cluster is similar and different than a multi-pod Kubernetes deployment.
A “traditional” HCL Digital Experience cluster is based on an IBM WebSphere Application Server (WAS) Network Deployment (ND) cell. One or more HCL DX Servers are in the same WAS cell. They share a common database. Each of the HCL DX Server cluster members produce exactly the same HTTP response as the other members of the cell. When deploying new binary artifacts (e.g. new portlets, themes, etc.), the IBM WAS Deployment Manager (DMgr) in this topology owns the “master” copy of the binary. It “syncs” that binary out to each of the cluster members when updated. There are many other features of a WAS ND cell that HCL DX deployments takes advantage of in this topology as well.
It is important to note that in this WAS ND topology, regardless of which HCL DX cluster member provides the role of DX administration, all cluster members and the database are properly updated when portlets, themes and configuration changes occur.
In a Kubernetes deployment, each HCL DX POD is a standalone WAS entity. These DX PODs have no knowledge of other PODs running DX. All the PODs do share a common database like in the WAS ND cluster case, however. In addition, each POD has a “volume mount” for the WAS profile governing the configuration of that HCL DX deployment. This profile is also shared between all the PODs to ensure that each POD provides the same response to an inbound HTTP request.
In either topology (on-premises OS, or Kubernetes), the union of the WAS profile and the database provide all the configuration required. If the HCL DX Kubernetes PODs all share the same database as well as the same profile, then their responses will be the same for inbound HTTP requests. Also note that no configuration changes are reflected in the HCL DX container (e.g. a Docker “commit” command is not used). All configuration changes are reflected in the WAS profile.
One important difference is that when a configuration change takes place in a Kubernetes environment, typically it is recommended that only one HCL DX POD is active. In that case, the profile and database are updated with any WAS or HCL DX changes. As new PODs are then spawned, they also inherit these changes.
Single Kubernetes Cluster Versus Multiple Kubernetes Cluster
Just like in the “traditional” WAS ND cluster, the lowest risk topology for deployment of new artifacts into a Kubernetes cluster is to maintain two independent Kubernetes clusters. Just like in the traditional WAS ND cluster, one would deploy all changes to the “off-line” cluster, validate that cluster and then switch that cluster at the load balancer to be active. One could then apply the same processes to the down-level Kubernetes cluster, which is now out of the active load balancer.
Processes and Tooling to Deploy Artifacts to Kubernetes
The main difference between deploying HCL DX with WAS ND services to Kubernetes and traditional on-premises platforms is that it is recommended to only allow a single POD of HCL DX to be active in Kubernetes while any configuration changes takes place. The process to deploy new artifacts to a Kubernetes environment mirrors the processes used to deploy those same artifacts to a traditional WAS ND based cluster. All existing deployment tooling is still present and available in the Kubernetes case.
The reason one only wants one POD of the DX deployment active is due to the fact that the (shared) database might reflect differences with existing (older) PODs if multiple PODs were allowed to be active. Once all changes are complete, one can allow autoscaling of the number of HCL DX PODs back to the “production” number. For DX container autoscaling guidance, see Customizing the Container Deployment.
Note that during this process, this single HCL DX POD node can remain in the active load balance if one is running a single Kubernetes cluster.