Collecting job logs with Output collector
An overview on the mechanism that automatically retrieves the logs of jobs and dynamic jobs run on HCL Workload Automation Agents and copies them to the JES spool so that they can be processed by an external output management product.
The standard log management process for jobs running in the z-centric environment is to be requested manually, with an exception for the logs of jobs that ended in error that can be received semi-automatically. In addition to this, or as an alternative, you can activate the Output collector started task, which automatically retrieves the log of every job run in the z-centric environment and sends it to the JES spool so that it can be processed by an external output management product.
Every time a job or a dynamic job completes or terminates on an HCL Workload Automation Agent, the Output collector started task receives an event from the HCL Workload Automation for Z controller (which manages all communication with the agents and the dynamic domain managers in the z-centric environment). The event contains the information necessary for Output collector to identify the job and where it run. The output collector then retrieves the job log from the agent, or the dynamic domain manager if the job is dynamic, and copies it to a SYSOUT in JES (using a specific SYSOUT class) to make it available to an output management product.
Activation of this feature is optional. If you activate it, it automatically collects the logs of all jobs run in the z-centric environment, regardless of whether they complete successfully or terminate in error. If you do not activate it, you can still configure your system to either request logs manually or to receive those of jobs ended in error.
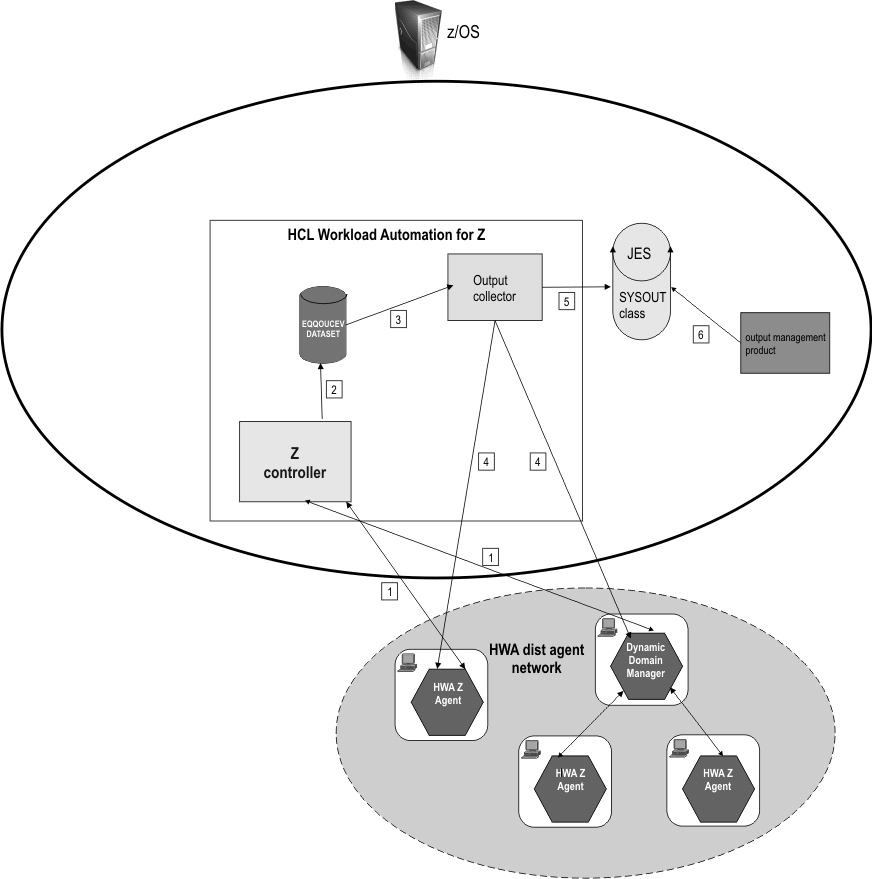
- The controller submits and tracks jobs and gets the job logs upon request.
- Every time a job completes or terminates, the controller writes an event in the EQQOUCEV data set. The event contains identification of the job and the name of the agent that ran it.
- Output collector reads the event in EQQOUCEV.
- Based on the information found in the event record, Output collector retrieves the job log from the agent (or the dynamic domain manager if the job is dynamic).
- Output collector copies the job log to a SYSOUT in JES using a specific SYSOUT class.
- The external output management product can get the job log for analysis, accounting, and other operations.
The controller and Output collector use the EQQOUCEV and EQQOUCKP data sets to share the information concerning completed or terminated jobs. The communication process is based upon events. Every time a job completes or terminates, the controller queues an event for Output collector with the information necessary to identify the job and the agent that run it in a new record in EQQOUCEV. Output collector reads the record, checkpoints it in EQQOUCKP, dispatches it to the proper thread, and marks the event as processed moving to the next-to-read index in the data set header. EQQOUCKP is used to checkpoint the incoming requests to prevent their loss in case of unplanned closures.
To write a job log in the JES spool, Output collector allocates a SYSOUT data set with DDNAME equal to the job name, writes the job log in it, and then closes it. This implies that all the SYSOUTS will have the started task job name and job id and will differ only in the DDNAME and job log header.