Execute a user-defined aggregate in parallel queries
- The INIT support function initializes execution in the parallel thread.
- For each aggregate argument in the subset, the ITER support function merges the aggregate argument into a partial result.
The database server then calls the COMBINE support function to merge the partial states, two at a time, into a final state. For example, for the AVG built-in aggregate, the COMBINE function would add the two partial sums and adds the two partial counts. Finally, the database server calls the FINAL support function on the final state to generate the aggregate result.
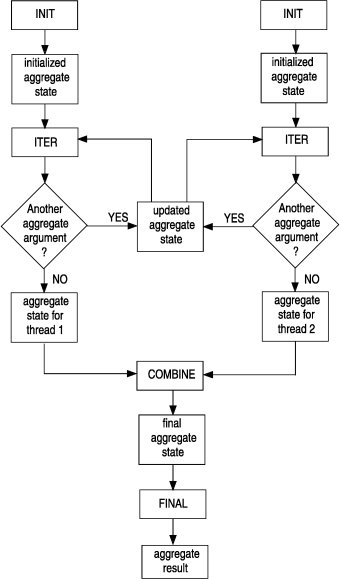
The preceding figure shows how the COMBINE function is used to execute a user-defined aggregate with two parallel threads. For more than two parallel threads, the database server calls COMBINE on two thread states to obtain one, combines this state with another thread state, and so on until it has processed all parallel threads. The database server makes the decision whether to parallelize execution of a user-defined aggregate and the degree of such parallelism. However, these decisions are invisible to the end user.
Parallel aggregation must give the same results as an aggregate that is not computed in parallel. Therefore, you must write the COMBINE function so that the result of aggregating over the entire group of selected rows is the same as aggregating over two partitions of the group separately and then combining the results.
For an example of COMBINE functions in user-defined aggregates, see Sample user-defined aggregates.