Determine required aggregate support functions
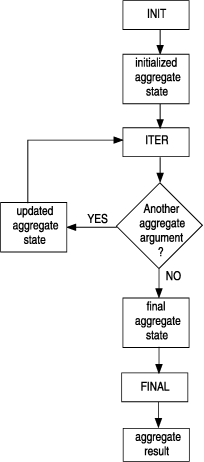
For information about how to execute a user-defined aggregate in parallel queries, see Execute a user-defined aggregate in parallel queries.
These aggregate support functions use the aggregate state to pass shared information between themselves.
As you design your aggregate algorithm, you must determine which of the support functions the algorithm requires. As a minimum, the user-defined aggregate must have an ITER function. It is the ITER function that performs a single iteration of the aggregate on one aggregate argument. Although Execution of a nonparallel user-defined aggregate shows the execution of both the INIT and FINAL support functions, these functions are optional for a user-defined aggregate. In addition, the COMBINE function, though required, often does not require separate code; it can simply call the ITER function.
| Design decision | Aggregate support functions involved | More information |
|---|---|---|
| Does the algorithm require initialization or clean-up tasks? | INIT and FINAL | Aggregate support functions that the algorithm requires |
| Does the aggregate have a simple aggregate state? | INIT, COMBINE, and FINAL | Yes: Handling a simple state |
| Does the aggregate have a setup argument? | INIT | Implement a setup argument |
| Does the aggregate return a value whose data type is different from the aggregate state? | FINAL | Return an aggregate result different from the aggregate state |
| Does the aggregate have special needs to run in a parallel query? | COMBINE | Execute a user-defined aggregate in parallel queries |
You can overload the aggregate support functions to provide support for different data types. Any overloaded version of the UDA, however, cannot omit any of the aggregate support functions that the CREATE AGGREGATE statement has listed or use any support function that CREATE AGGREGATE has not specified.
When the database server executes a UDA (regardless of the data type of the aggregate argument), the database expects to find all the aggregate support functions that the CREATE AGGREGATE statement has registered. Therefore, if you omit a support function for one of the reasons in the preceding table, all versions of the aggregate for all data types must be able to execute using only the aggregate support functions that CREATE AGGREGATE specifies.