Canalizaciones de índice de sinónimos de Ingest
Correlación de campos de índice de sinónimos de la especificación de datos
El diagrama siguiente ilustra la canalización de indexación de sinónimos implementada en Apache NiFi. El flujo consta principalmente de tres etapas:
- Genere documentos de Diccionario de sinónimos para Elasticsearch basándose en el sinónimo de entrada por idioma.
- (IF POST) Extraiga los sinónimos actuales en el Diccionario de índice de productos y añádalos al documento generado desde la etapa uno.
- Actualice los diccionarios específicos del idioma del producto con el documento de sinónimos generado desde la etapa uno y dos.
- Inicial
- Llamada PUT o POST REST: http://<Hostname>:30700/connectors/JsonSynonym/data
{ "synonyms": { "english": { "synonyms": [ "coff => coffee", "driveway, road, street" ] }, "french": { "synonyms": [ "coff => coffee", "driveway, road, street" ] } } } - 1. Generar documento de Diccionario de sinónimos t
- En el siguiente flujo de datos se describe cómo los datos de sinónimos específicos del idioma se pueden transformar utilizando el script Groovy CreateSynonymBodyPart1.
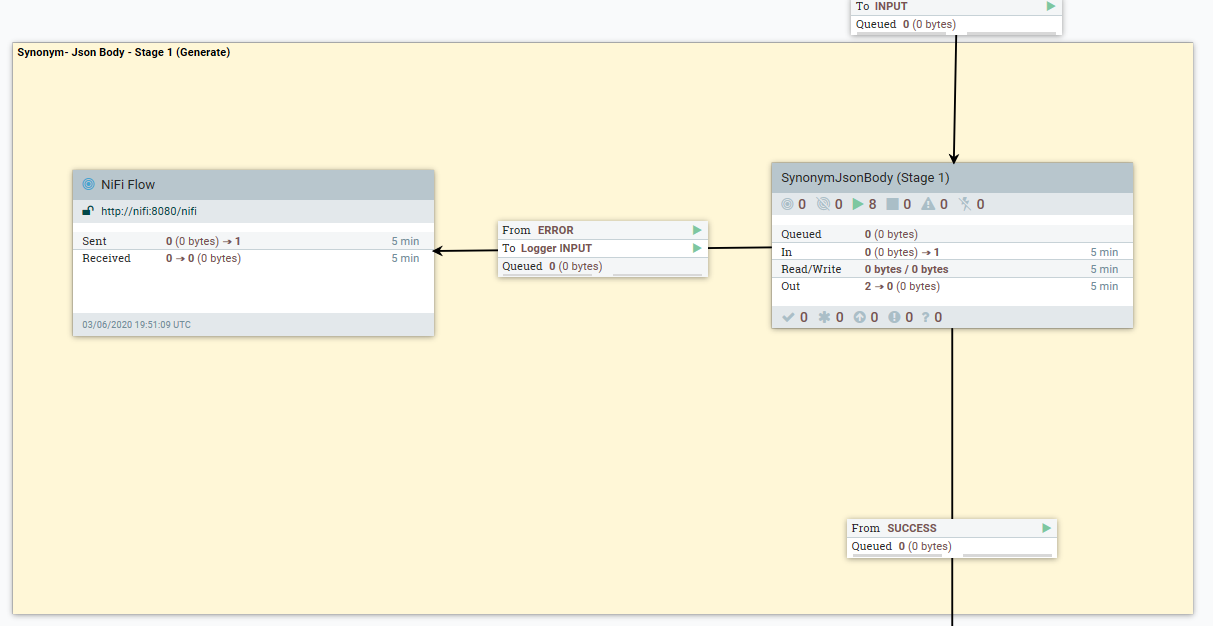
- 2. (IF POST) Extrae los sinónimos actuales del Diccionario de índice de productos y los añade al documento generado
- El flujo de información siguiente describe lo que sucede cuando el usuario realiza una solicitud POST*:
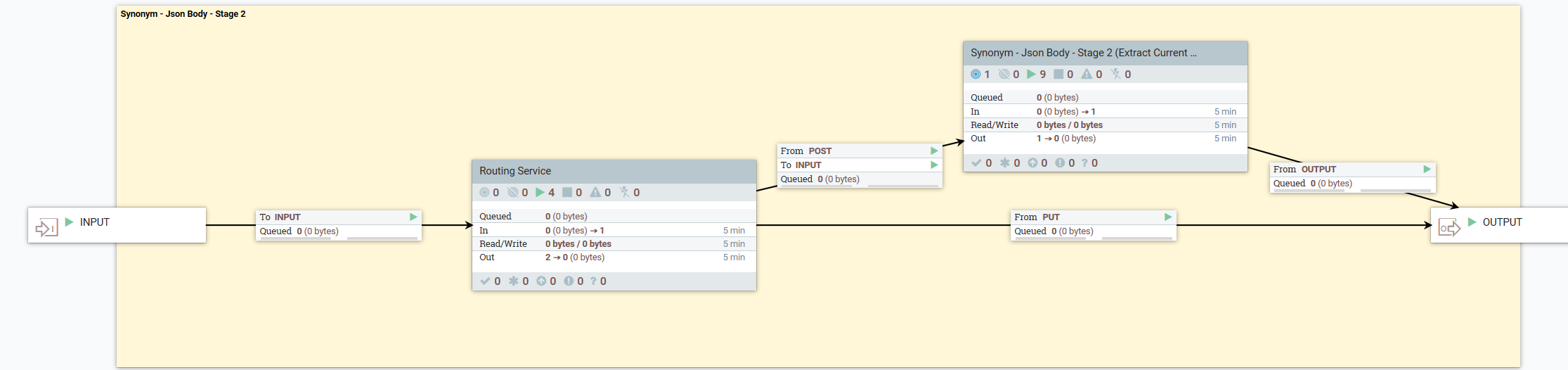
- 3. Actualizar los diccionarios específicos del idioma del producto con el documento de sinónimos
- El flujo de información anterior describirá el proceso de actualización (sobrescritura) del diccionario específico del idioma con la documentación generada anteriormente.

Correlación de campos de índice de sinónimos de la base de datos
Especificación de datos:
El diagrama siguiente ilustra la canalización de indexación de asociación de términos de búsqueda (STA) implementada en Apache NiFi. El flujo consta principalmente de dos etapas:
- Extraiga las STA de la base de datos relativa a StoreID (y storeID relacionado) y genere el documento de STA para Elastic Search.
- Actualice los diccionarios específicos del idioma del producto con el documento de STA generado a partir de la etapa uno.
- Paso 1 Extraer las STA de la base de datos relativa a StoreID (y storeID relacionada) y generar documentos STA para Elastic Search
- En el siguiente flujo de datos se describe cómo se pueden transformar los datos de base de datos de STA utilizando el script Groovy CreateSTABody.
.png)
- Etapa 2. Actualizar diccionarios específicos de idioma del producto con el documento de STA generado en la etapa uno
- El siguiente flujo de entrada describe el proceso
- Cerrar índice de productos
- Actualizar índice de productos
- Abrir índice de productos
.png)