Canalizaciones de índice de palabras frecuentes de Ingest
Las palabras clave se generan fácilmente utilizando la canalización NiFi.
Correlación de campos de índice de palabras clave de la especificación de datos
El diagrama siguiente ilustra la canalización de indexación de palabras clave implementada en Apache NiFi. El flujo consta principalmente de tres etapas:
- Generar un documento de diccionario de palabras frecuentes para ElasticSearch basándose en la palabra frecuente de entrada por idioma.
- (IF POST) Extraiga las palabras frecuentes actuales en el Diccionario de índice de productos y añádalas al documento generado en la etapa uno.
- Actualice los diccionarios específicos del idioma del producto con el documento de palabras frecuentes generado en la etapa uno y dos.
- Inicial
- Llamada PUT o POST REST: http://<Hostname>:30700/connectors/JsonStopword/data
{ "stopwords": { "english": { "stopwords": ["step1", "car"] }, "french": { "stopwords": ["step2", "dark"] } } }
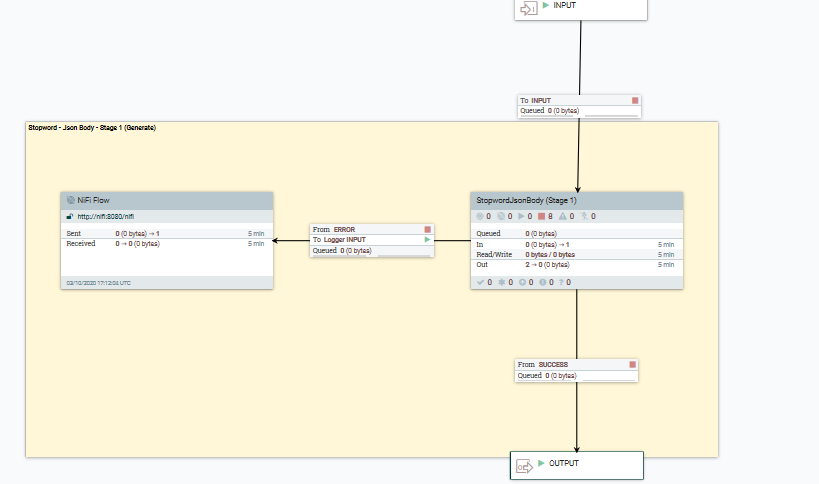
- Etapa 1. Generar un documento de diccionario de palabras frecuentes
- En el siguiente flujo de datos se describe cómo se pueden transformar las palabras frecuentes específicas del idioma utilizando el script Groovy CreateStopwordBodyPart1.
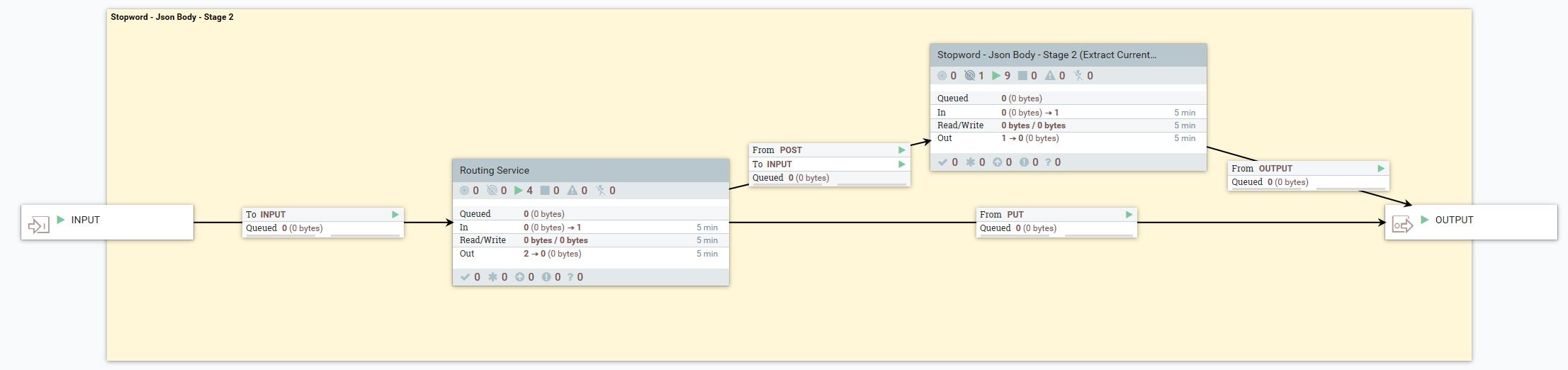
- Etapa 2. (IF POST) Extraer las palabras principales actuales en el diccionario de índice de productos y añadirlas al documento generado
- El siguiente flujo de entrada muestra que, cuando el usuario realiza una solicitud POST*, tienen lugar los siguientes pasos:

- Etapa 3. Actualice los diccionarios específicos del idioma del producto con el documento de palabras frecuentes generado.
- El siguiente flujo de información describe el proceso de actualización (sobrescritura) del diccionario específico del idioma con la documentación generada anteriormente a través de los pasos siguientes:
- Cerrar índice de productos
- Actualizar índice de productos
- Abrir índice de productos
