Unstructured content indexing and handling
The information stored in unstructured content can be organized and stored from several locations, including the WebSphere Commerce database, in file systems of servers, and on the Internet. Therefore, the indexing process of unstructured content uses a hybrid of data sources to create indexing information using the existing WebSphere Commerce Search indexing framework.
Unstructured content organization and retrieval
SELECT ATCHREL.atchrel_id, CE.CATENTRY_ID, ATCHAST.atchast_id, ATCHTGT.identifier, ATCHTGTDSC.name, ATCHTGTDSC.shortdescription, ATCHTGTDSC.longdescription,
ATCHAST.atchastpath , STORE.directory, ATCHAST.directorypath, ATCHAST.mimetype, ATCHASTLG.language_id, ATCHRLUS.Image, ATCHRLUS.identifier rulename
FROM TI_CATENTRY_0 CE
JOIN ATCHREL ON ATCHREL.BIGINTOBJECT_ID = CE.CATENTRY_ID
JOIN ATCHOBJTYP ON (ATCHREL.ATCHOBJTYP_ID = ATCHOBJTYP.ATCHOBJTYP_ID AND ATCHOBJTYP.IDENTIFIER = 'CATENTRY')
LEFT JOIN ATCHTGT on (ATCHREL.atchtgt_id = ATCHTGT.atchtgt_id )
LEFT JOIN ATCHAST on (ATCHAST.atchtgt_id = ATCHTGT.atchtgt_id)
LEFT JOIN ATCHASTLG on (ATCHASTLG.atchast_id = ATCHAST.atchast_id)
LEFT JOIN ATCHTGTDSC on (ATCHTGTDSC.atchtgt_id = ATCHTGT.atchtgt_id AND ATCHTGTDSC.language_id=?language_id?)
JOIN ATCHRLUS ON (ATCHREL.ATCHRLUS_ID = ATCHRLUS.ATCHRLUS_ID)
LEFT JOIN STORE on (ATCHAST.storeent_id = STORE.store_id)
WHERE (ATCHASTLG.atchastlg_id is null or ATCHASTLG.language_id=?language_id?) order by ATCHREL.atchrel_id
<script><![CDATA[
function isWriteToFile(row) {
var ruleName = row.get('RULENAME');
var writeToFile = "false";
if(ruleName != null){
if(ruleName == 'DOCUMENTS' || ruleName == 'USERMANUAL' || ruleName == 'WARRANTY'
|| ruleName == 'OTHER'){
writeToFile = "true";
}
}
row.put('writeToFile', writeToFile);
return row;
}
]]></script>
Content configuration for the preprocess utility
The preprocess utility extracts and flattens WebSphere Commerce data and then outputs the data into a set of temporary tables inside the WebSphere Commerce database. The data in the temporary tables is then used by the index building utility to populate the data into search indexes using the Data Import Handler (DIH).
The preprocess utility picks the wc-dataimport-preprocess-fullbuild.xml file or wc-dataimport-preprocess-deltaupdate.xml file first, and then transforms the results of the SQL statements defined in those files into temporary tables. Next, the utility handles each configuration XML file in a random order.
Unstructured content preprocessing is a language-specific process, where an unstructured content configuration file is used. The attachments and catalog entry information's relationship is stored in the generated table for further DIH retrieval.
See di-preprocess utility for more information.
Data Import Handler and indexing unstructured content
The data import handler handles the indexing process of unstructured content using a hybrid of data sources to create indexing information using the existing WebSphere Commerce Search indexing framework. The TikaEntityProcessor is used to support the hybrid data.
The following diagram illustrates the role of the TikaEntityProcessor in handling unstructured content in WebSphere Commerce:
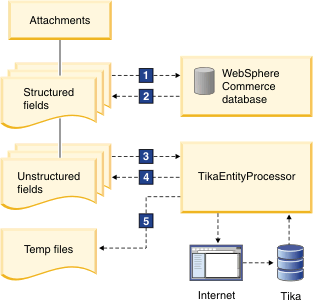
- 1, 2
- Catalog entries are indexed from the WebSphere Commerce database as structured content.
- 3, 4, 5
- The logic reuses the features of the DIH framework such as looping through the SQL result set
rows and passing parameters in a form resembling the following:
${Attachment.CATENTRY_ID}. The TikaEntityProcessor uses thesourceUrlparameter withcommercebaseparameters to fetch content from the Internet, parses the binary content, and returns the results to the unstructured content index. Next, the TikaEntityProcessor appends the text content to a catentryId.txt file, located in the temp folder under the unstructured core root folder.
The commercebase parameters can be customized to meet your specific search
requirements. The tikacontentfield and tikaprefix parameters are
directly mapped to the fmap.content and uprefix Solr Cell
parameters. For more information, see ExtractingRequestHandler.
The di-buildindex utility is used to index the unstructured content.
Structured content data import handler process updates to index unstructured content
Structured objects might need to be searched by the content of related unstructured content. Therefore, the unstructured content is also needed by structured content. That is, the default structured content DIH indexing process must also read the content of unstructured content. Based on the temporary files that the TikaEntityProcessor creates during the unstructured content DIH process, the PlainTextEntityProcessor is used to read the content of the temporary files and index them in the defined field.
The basePath data source in the DIH configuration file defines the temporary
folder location. In this configuration, onError="continue" is set so that if the
file does not exist, or there are other errors, the DIH process continues running and ignores the
error. The column name of the unstructure field is a fixed value set as
plainText and must not be changed.