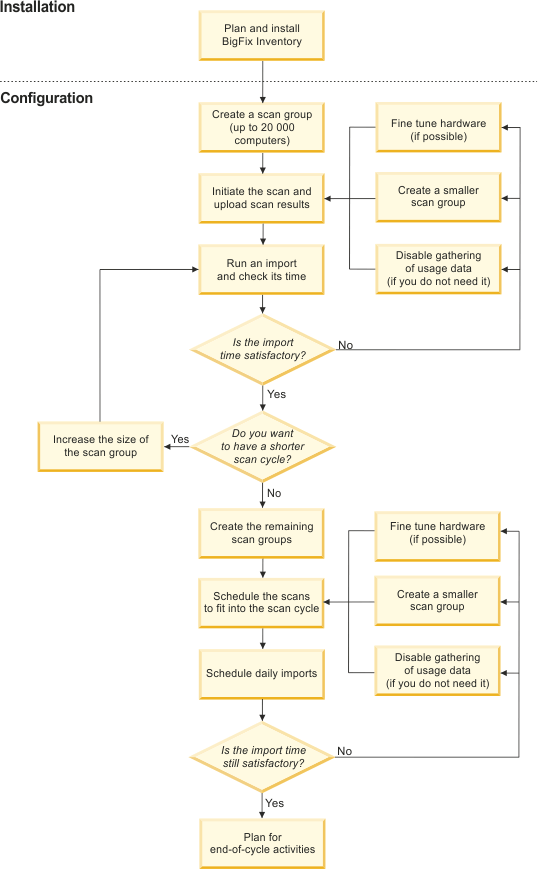
Dividing the infrastructure into scan groups
To avoid running into performance issues, you should divide the computers in your infrastructure into scan groups and properly set the scan schedule. You should start by creating a benchmark scan group on which you can try different configurations to achieve optimal import time. After the import time is satisfactory for the benchmark group, you can divide the rest of your infrastructure into analogous scan groups.
Procedure
-
Create a single scan group that will be your benchmark.
The size of the scan group might vary depending on the size of your infrastructure. However, the recommendation is to avoid creating a group larger than 20 000 endpoints. For more information about creating computer groups, see: Lesson 1 (Optional): Creating computer groups in the BigFix console
- Run Initiate Software Scan fixlet and scan the computers in this scan group. For more information, see: Initiating software scans.
- When the scan finishes, use Upload Software Scan Results fixlet to upload the results of the scan to the BigFix server. For more information, see: Uploading software scan results.
- Run an import of data. For more information about running imports, see: Scheduling imports of data. Check the import time and decide whether its duration is satisfactory.
- If you are not satisfied with the import time, go to the following directory and check
the import log.
 installation_directory/wlp/usr/servers/server1/logs/imports
installation_directory/wlp/usr/servers/server1/logs/imports installation_directory\wlp\usr\servers\server1\logs\imports
installation_directory\wlp\usr\servers\server1\logs\imports
- Undertake one of the following actions:
- If you see that the duration of the import of raw file system scan data or package data takes longer than one third of the ETL time and the volume of the data is large (a few millions of entries), create a smaller group.
- If you see that the duration of the import of raw file system scan data or package data takes longer than one third of the ETL time but the volume of the data is low, fine-tune hardware. For information about processor and RAM requirements as well as network latency and storage throughput, see: Hardware requirements.
- If you see that processing of usage data takes an excessive amount of time and you are not interested in collecting usage data, disable gathering of usage data. For more information, see: Disabling the collection of software usage.
- After you adjust the first scan group, run the software scan again, upload its results to the BigFix server and run an import of data.
- When you achieve an import time that is satisfactory, decide whether you want to have a shorter scan cycle.
Example
What to do next
Use the following diagram to get an overview of actions and decisions that you will have to undertake to achieve optimal performance of BigFix Inventory.