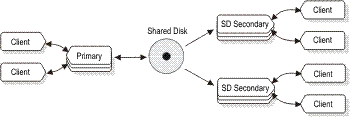
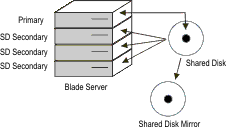
The following figure shows an example of a primary server with
two SD secondary servers. In this case the role of the primary server
can be transferred to either of the two SD secondary servers. This
is true whether the primary must be taken out of service because of
a planned outage, or because of failure of the primary server.Figure 1: Primary server configured with
two SD secondary servers
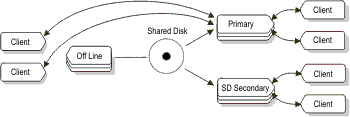
Because both of the SD secondary servers are reading from the same
disk subsystem, they are both equally able to assume the primary server
role. The following figure illustrates a situation in which the primary
server is offline.Figure 2: SD secondary
server assuming role of primary server
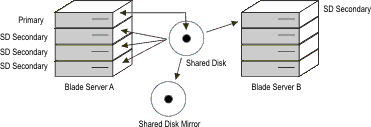
There are several ways to protect against hardware failure of the
shared disk. Probably the most common way is to configure the disk
array based on RAID technology (such as RAID-5). Another way to protect
against disk failure is to use SAN (Storage Area Technology) to include
some form of remote disk mirroring. Since SAN disks can be located
a short distance from the primary disk and its mirror, this provides
a high degree of availability for both the planned and unplanned outage
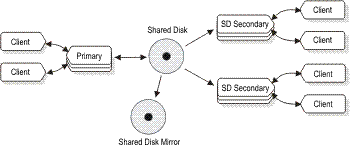
of either the server or of the disk subsystem. The following illustration
depicts such a configuration:Figure 3: Primary
server and SD secondary servers with mirrored disks
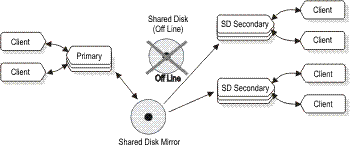
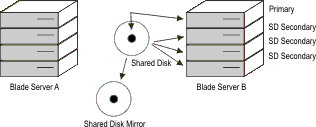
In the event of a disk failure, the servers can be reconfigured
as in the following illustration:Figure 4: Shared disk mirror after failure of primary shared disk In addition to configuring a mirrored disk subsystem as in the
previous illustration, you might want to configure additional servers.
For example, you might want to use the primary and two SD secondary
servers within a single blade server enclosure. By placing the server
group within a single blade server, the blade server itself can become
a failure point. The configuration in the following illustration is
an attractive solution when you must periodically increase read processing
ability such as when performing large reporting tasks.Figure 5: Primary and SD secondary servers
in a blade server
You might decide to avoid the possible failure point of a single
blade server by using multiple blade servers, as in the following
illustration.Figure 6: Multiple blade
server configuration to prevent single point of failure
In the previous illustration, if Blade Server A fails, it would
be possible to transfer the primary server role to the SD secondary
server on Blade Server B. Since it is possible to bring additional
SD secondary servers online very quickly, it would be possible to
dynamically add additional SD secondary servers to Blade Server B
as in the following illustration.
Figure 7: Failover after failure
of blade server
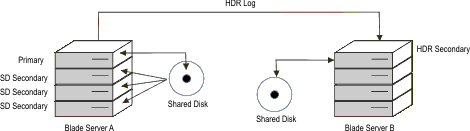
Because of limits on the distance between the primary and mirrored
disks that disk mirroring can support, you might be concerned about
using shared disks and relying on shared disk mirroring to provide
disk availability. For example, you might want significant distance
between the two copies of the disk subsystem. In this case, you might
choose to use either an HDR secondary or an RS secondary server to
maintain the secondary copy of the disk subsystem. If the network
connection is fairly fast (that is, if a ping to the secondary server
is less than 50 milliseconds) you must consider using an HDR secondary
server. For slower network connections, consider using an RS secondary
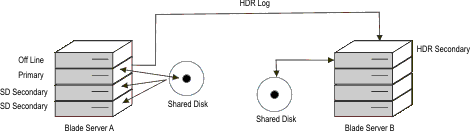
server. The following illustration shows an example of an HDR secondary
server in a blade server configuration.Figure 8: HDR secondary server in blade server configuration
In the configuration shown in the previous illustration, if the
primary node fails, but the shared disks are intact and the blade
server is still functional, it is possible to transfer the primary
server role from the first server in Blade Server A to another server
in the same blade server. Changing the primary server would cause
the source of the remote HDR secondary server to automatically reroute
to the new primary server, as illustrated in the following diagram:Figure 9: Failover of primary server to SD
secondary server in blade server configuration
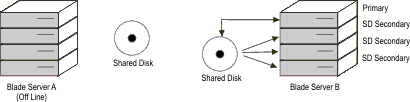
Suppose, however, that the failure described in the previous illustration
was not a blade within the blade server, but the entire blade server.
In this case you might be required to fail over to the HDR secondary.
Since starting an SD secondary server is very quick, you can easily
add additional SD secondary servers. Note that the SD secondary server
can only work with the primary node; when the primary has been transferred
to Blade Server B, then it becomes possible to start SD secondary
servers on Blade Server B as well, as shown in the following illustration.Figure 10: Failure of entire blade server
Have feedback?
Google Analytics is used to store comments and ratings. To provide a comment or rating for a topic, click Accept All Cookies or Allow All in Cookie Preferences in the footer of this page.