Insertion into an R-tree index
When data is inserted into an R-tree indexed table column, the R-tree index must also be updated with the new information. Insertion into an R-tree index is similar to insertion into a B-tree index in that new index records are added to the leaves, nodes that overflow are split, and splits propagate up the tree.
First, the R-tree secondary access method calculates a bounding box for the new data object. The access method then searches for a leaf page whose existing entries form the tightest group with the new data object. The access method searches down the tree from the root page, looking for data objects whose bounding box best fits the new data object. Then it descends into that subtree, repeating the selection process at each internal page until it reaches a leaf page.
As the R-tree access method searches down the tree, it looks for bounding boxes that will be enlarged the least to accommodate the new data object. The access method might also use internal criteria other than the bounding box being enlarged by the smallest amount when it chooses the best leaf page.
Once the access method finds the best leaf page, and there is space on the corresponding disk page, the access method adds a new index entry that consists of a copy of the new data object. The bounding boxes of the parent index pages all the way up to the root page might also need to be enlarged.
If no space is left on the leaf page for the new data object, the leaf page is split into two pages. This means that a new page is allocated and the contents of the old page, plus the new data object, are divided between the old and the new pages. If the parent page is full, it might also need to split, and so on up to the root page. If the root page splits, the tree becomes one level deeper.
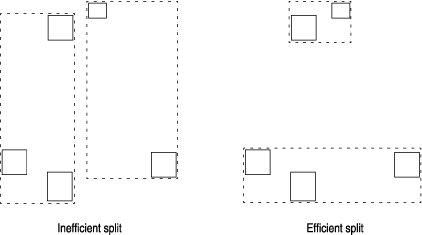
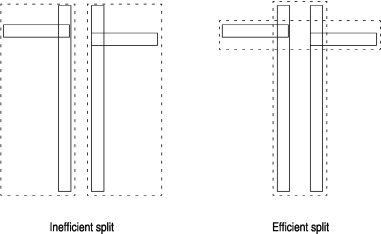
The preceding example shows that avoiding overlap is not necessarily the best, and definitely not the only, criterion for dividing index entries between the two resulting pages of a page split.
The R-tree index is initially created by starting with an empty root page and inserting index entries one by one.