
WebSphere Commerce search index schema
The WebSphere Commerce search index process involves a search index schema, and is built from temporary tables.
Indexing WebSphere Commerce content with WebSphere Commerce search requires a well-structured index schema design, so that populating and querying the index is efficient when performing searches.
- Solr server instance
- A self-contained run time environment, which includes Solr server process, Solr home and Solr Cores.
- Solr Core
- Enables one Solr instance to contain multiple configurations and indexes, thus being more efficient than dedicated Solr instances for each configuration and index. Due to its hot Core reloading and swapping features, using the Solr Core is recommended.
- Solr index
- Solr maintains one or more indexes, which are searchable collections of items called documents. When using Solr to support catalog search, the documents in the index represent catalog entries.
- Solr schema
- Defined in the Solr configuration file, schema.xml. It defines the schema fields and data type of the fields.
- Solr data import handler (DIH)
- Provides a configuration-driven method of importing data from relational databases or XML to the Solr index.
- Solr home
- The root directory of the Solr configuration files and index data files. Each Solr instance can map to one Solr home.
The WebSphere Commerce search schema-related information is stored in the schema.xml file, with other configuration information stored in the solrconfig.xml file. You can customize these files directly to suit your business needs. The unique key of the index is the catentry_id field. That is, the index document is only for CATENTRY. If other WebSphere Commerce objects must be indexed, for example, CATGROUP, separate index document must be created. The default query operator is set to OR.
- wc_text
- Used for searchable fields. The field is tokenized and lower-cased, to support not case-sensitive searches. The dictionary functions are enabled, such has synonyms, stopwords, and stemming.
- wc_keywordText
- Used for generic sorting and faceting. The field is non-tokenized. No dictionary functions are enabled. In general, WebSphere Commerce search requires a sorting or faceting field to be indexed, but not multivalued or tokenized.
- wc_keywordTextLowerCase
- Used for not case-sensitive sorting and faceting. The field is non-tokenized, and lower-cased. No dictionary functions are enabled. In general, WebSphere Commerce search requires a sorting or faceting field to be indexed, but not multivalued or tokenized.




 wc_textSpell
wc_textSpell- Used for spell checking. By default, spell checking is enabled
on field name, mfname, shortdescription and keyword.
Search dictionary files
- Synonyms
-
Query-time synonym processing is implemented
in WebSphere Commerce search, as it is relatively flexible when compared
to indexing-time synonym processing. Synonym expansion is enabled
by default. Synonyms are contained in the synonyms.txt file, and are
maintained by Product Managers in the Management Center using Search term associations.
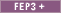 Synonym expansion is implemented using WebSphere
Commerce Web services.
Synonym expansion is implemented using WebSphere
Commerce Web services. - Stop words
- Basic United States English stop words are contained in the stopwords.txt file. This stop word list contains words merged from the default Solr stop words and ODE stop words. You can manually maintain stop words in the stopwords.txt file if necessary.
- Stemming
- The EnglishPorterFilterFactory is used for the English language, as this factory supports user-defined protected words, and performs relatively well. The SnowballPorterFilterFactory is used for other languages. Stemming is only enabled in the wc_text field type. You can manually maintain protected words in the protwords.txt file if necessary.
<SolrSearch solrHome="/solr/WebSphere/search/demo/search/solr/home"/>
Highlighting search keywords
Highlighting
keywords is a default query component. The query controls how the
highlighting works. The field must be stored in the index for highlighting
to be enabled. The field option stored must be set
to true in the schema.xml file.
Spelling correction
The indexed content is used to create the term dictionary, so that the generated dictionary data is relevant to the indexed data. Spell checking is enabled in the search request handler in the wc_spellcheck component in the solrconfig.xml file. The wc_textSpell field type and spellCheck field is created in the schema.xml file. The spellCheck field contains the field's name, shortDescription, and keyWord by default.
http://localhost/solr/CatalogEntry/select?indent=on&version=2.2&q=shortDescription%3Acofffee
&fq=&start=0&rows=10&fl=*%2CsCore&qt=standard&wt=standard&explainOther=&hl.fl=&
spellcheck=true&spellcheck.collate=trueSpell check index
The spell check index ensures that automatically suggested search terms accurately reflect the terms in the search index.
It is built automatically during commits (build index and replication), including subordinate search nodes in a clustered environment.
To change the spell check index behavior for performance reasons, see Tuning the spell check index.

Spell checker component
A more efficient spell checker, DirectSolrSpellChecker, is used instead of the
spell check index. This spell checker component uses data directly from the CatalogEntry index,
instead of relying on a separate stand-alone index. Therefore, no additional index builds are
required to synchronize changes between the base index and the spell checker index. For more
information, see SpellCheckComponent.
Automatic keyword suggestions
The TermsComponent is implemented in WebSphere Commerce for auto-suggest functionality. The component provides fast field faceting over the entire index. That is, it is not restricted by the base query or any filters. The document frequencies returned are the number of documents that match the term, including any documents that have been marked for deletion but not yet removed from the index.
Retrieving terms from the index order is relatively fast since the implementation directly uses the Lucene TermEnum functionality to iterate over the term dictionary.
The wc_termsComponent search component and wc_terms request handler are created in the solrconfig.xml file.
http://localhost/solr/MC_10001_CatalogEntry_en_US/terms?terms.fl=shortDescription&terms.sort=index&erms.limit=5&terms.prefix=ligh
Default search scope
- Product description (name)
- Short description (shortDescription)
- Part number (partNumber_ntk)
- Keyword
- Attribute Dictionary attribute values
Schema changes when relating structured content with unstructured content
When structured content contains a relationship with unstructured content, it must contain a new field in the structured schema.xml file to represent the unstructured information. This new field can query the structured objects by their unstructured content.
<field name="unstructure" type="wc_text" indexed="true" stored="false" multiValued="true" />
stored="false" snippet enables
unstructured content to not be retrieved by queries.