
WebSphere Commerce search programming model, extension points, and customization tasks
The following guide outlines the WebSphere Commerce search programming model, extension points, and how it can be customized. There are mandatory and optional areas to work with, depending on the customization that is being performed to your WebSphere Commerce search implementation.
Most customization flows involve indexing new data from either the database or a file, searching against the new indexed fields, displaying the indexed data in the storefront, and creating business rules by using the indexed data field. There are other advanced search customization areas that require some runtime customization where a custom search expression provider, or other runtime search extension points might require customization.
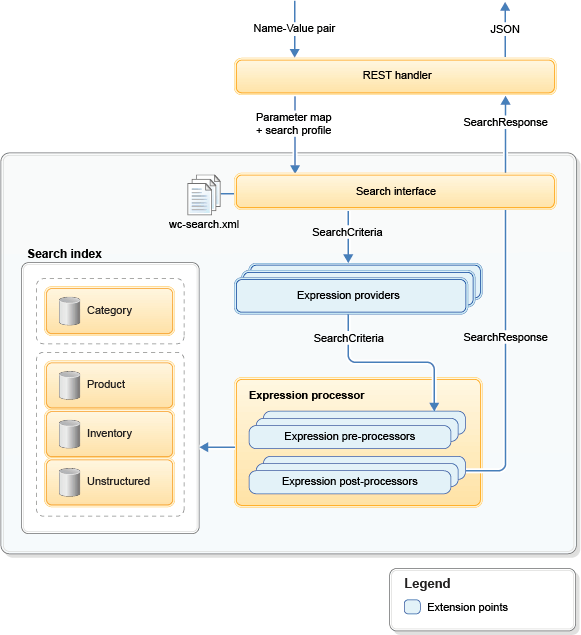
Where the WebSphere Commerce search runtime programming model is used on the search server. Instead of using BOD and performing object based-mediation, the search REST programming model does not rely on any SDO and instead uses POJO and raw data returned from the search server to perform simple name-value pair mapping.
Indexing (including preprocessing) is performed and launched from the WebSphere Commerce server. After index preprocessing successfully completes, the Data Import Handler (DIH) can be run from the same WebSphere Commerce server and Solr can start creating and updating the Lucene index from the WebSphere Commerce temporary database tables. If preprocessing is not required, such as for the inventory extension index, the DIH process can be launched either from WebSphere Commerce or directly from a URL issued against the WebSphere Commerce search server.