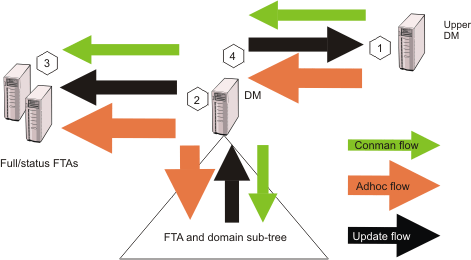
In order to plan space for event queues, and possible alert levels
and reactions, it is necessary to model the flows passing through
the agents, and the domain managers in particular. Figure 1. Typical HCL Workload Automation network
flows.
For a typical domain manager, the main flow comes from update activity
reported by the sub tree, and from ad hoc submissions arriving from
the master domain manager and
propagating to the entire network. Under these conditions, the most critical errors
are listed by order of importance in Critical flow errors:
Table 1. Critical flow errors
Flow no.
Location
Queue
Risk
Impact
1
Upper domain manager
dm.msg
The queue fills up because of too
many unlinked workstations in the domain or a downstream domain manager
has failed.
The upper domain manager fails
and propagates the error.
2
Domain manager
FullStatus fta.msg
The queue fills because of too
many unlinked workstations in the domain or because the FullStatusfault-tolerant agent is
not coping with the flow.
The domain manager fails and favors
the occurrence of #1.
3
Domain manager and FullStatusfault-tolerant agent
Mailbox.msg or Intercom.msg
The queue fills because the FullStatusfault-tolerant agent cannot
cope with flow.
The FullStatusfault-tolerant agent fails
and favors the occurrence of #2.
4
Domain manager
tomaster.msg
The queue fills because of too
many unlinked workstations in the domain.
The domain manager starts to unlink
the subtree and accumulates messages in the structure.
5
Fault-tolerant agents - only
when enSwfaultTol global option is set to yes
deadletter.msg
The queue fills because of too
many unlinked workstations in the domain.
The agent stops.
6
Fault-tolerant agents - only
when enSwfaultTol global option is set to yes
ftbox.msg
This queue is circular. The rate
of messages entering the queue exceeds the rate of messages being
processed, because of too many unlinked workstations in the domain.
Events are lost.
Note:
Flows are greater at the master domain manager and
at any FullStatus fault-tolerant
agents in the master domain than at subordinate domain managers or FullStatusfault-tolerant agents.
Use evtsize -show to monitor queue sizes.
The amount of update flow is related to the amount of workload
running in a particular subtree and is unavoidable.
The amount of ad hoc flow is related to the amount of additional
workload on any point of the network. It can be reduced by planning
more workload even if it is inactive. Note that simple reruns (not rerun
from) do not create an ad hoc flow.
The planning, alert, and recovery strategy must take into account the following points:
Queue files are created with a fixed size and messages are added and removed in a cyclical
fashion. A queue reaches capacity when the flow of incoming messages exceeds the outgoing flow for a
sufficient length of time to use up the available space. For example, if messages are being added to
a queue at a rate of 1MB per time unit and are being processed and removed at a rate of 0.5 MB per
time unit, a queue sized at 10 MB (the default) is at capacity after 20 time units. But if the
inward flow rate descends to be the same as the outward flow rate after 19 time units, the queue
does not reach capacity.
The risk of the domain manager failing can be mitigated by switching to the backup domain
manager. In this case, the contents of the queues on the domain manager are unavailable until the
domain manager backup is started. In all cases, the size of the queue on the upper domain manager
towards any other domain manager must respect the condition A, as indicated in the table Queue sizing conditions..
The risk that fault-switching fault-tolerant agents might not be able to cope with the flow must
be planned beforehand. The specifications for fault-switching fault-tolerant agents must be similar
to those of the domain manager, to avoid that an agent receives a load that is not appropriate to
its capacity. Check if a queue is forming at the FullStatus fault-tolerant
agents, both in ordinary and peak operation situations.
Once risk #2 has been dealt with, the possibility of a network link failure can be mitigated by
sizing the queue from a domain manager to the FullStatus fault-tolerant agents
appropriately as a function of the average network outage duration, and by increasing the size of
the mailbox in case of unexpected long outage (see condition B of Queue sizing conditions.).
The same condition applies for avoiding an overflow of the domain manager's tomaster.msg queue
with respect to network outages (see condition C) of Queue sizing conditions..